
این فصل شامل موارد زیره:
- مقایسهی سبکهای مختلف تست واحد
- رابطهی بین معماری تابعی و معماری ششضلعی
- گذار به سمت تست مبتنی بر خروجی
فصل ۴ چهار ویژگی یک تست واحد خوب رو معرفی کرد: محافظت در برابر خطاهای برگشتی (Regression)، مقاومت در برابر تغییرات کد (Refactoring)، بازخورد سریع، و قابلنگهداری بودن. این ویژگیها یه چارچوب فکری بهت میدن تا بتونی تستهای مختلف و رویکردهای تستنویسی رو تحلیل کنی. یکی از این رویکردها رو هم توی فصل ۵ بررسی کردیم: استفاده از شبیهسازها (Mock).
توی این فصل، همین چارچوب رو میبریم سراغ سبکهای مختلف تست واحد. سه سبک اصلی وجود داره: تست مبتنی بر خروجی (Output-based)، تست مبتنی بر وضعیت (State-based)، و تست مبتنی بر ارتباط (Communication-based). بین این سه تا، تست مبتنی بر خروجی بهترین کیفیت رو تولید میکنه، تست مبتنی بر وضعیت انتخاب دومه، و تست مبتنی بر ارتباط فقط گاهیوقتها باید استفاده بشه.
البته نمیتونی همیشه از تست مبتنی بر خروجی استفاده کنی. این سبک فقط برای کدی جواب میده که کاملاً به شکل تابعی نوشته شده باشه (Purely Functional Code). ولی نگران نباش؛ تکنیکهایی هست که کمک میکنه تعداد بیشتری از تستهات رو به این سبک نزدیک کنی. برای این کار باید از اصول برنامهنویسی تابعی (Functional Programming) کمک بگیری و ساختار کد رو به سمت معماری تابعی (Functional Architecture) تغییر بدی.
توجه داشته باش که این فصل قرار نیست وارد جزئیات عمیق برنامهنویسی تابعی (Functional Programming) بشه. با این حال، امیدوارم تا آخر فصل یه درک شهودی و راحت از این پیدا کنی که برنامهنویسی تابعی چه ارتباطی با تست مبتنی بر خروجی (Output-based Testing) داره. همینطور یاد میگیری چطور تعداد بیشتری از تستهات رو با سبک مبتنی بر خروجی بنویسی، و در کنارش با محدودیتهای برنامهنویسی تابعی و معماری تابعی (Functional Architecture) هم آشنا میشی.
۶.۱ سه سبک تست واحد
همونطور که توی مقدمهی فصل گفتم، سه سبک اصلی برای تست واحد وجود داره:
- تست مبتنی بر خروجی (Output-based Testing)
- تست مبتنی بر وضعیت (State-based Testing)
- تست مبتنی بر ارتباط یا تعامل (Communication-based Testing)
میتونی یکی، دوتا، یا حتی هر سه سبک رو توی یک تست کنار هم استفاده کنی. این بخش پایه و اساس کل فصل رو میسازه و این سه سبک تست واحد رو با تعریف و مثال توضیح میده. توی بخش بعدی هم میبینی که این سبکها چطور در مقایسه با هم امتیاز میگیرن و کدومها کیفیت بالاتری تولید میکنن.
۶.۱.۱ تعریف سبک مبتنی بر خروجی
اولین سبک تست واحد، سبک مبتنی بر خروجیه (Output‑based Testing). توی این روش، یه ورودی به واحد تحت تست (سیستم مورد آزمون یا SUT) میدی و فقط خروجیای که تولید میکنه رو بررسی میکنی. این سبک فقط برای کدی قابل استفادهست که هیچ حالت داخلی یا وضعیت سراسری (Global State) رو تغییر نمیده. بنابراین تنها چیزی که باید بررسی بشه، مقدار بازگشتی اون تابع یا متده.
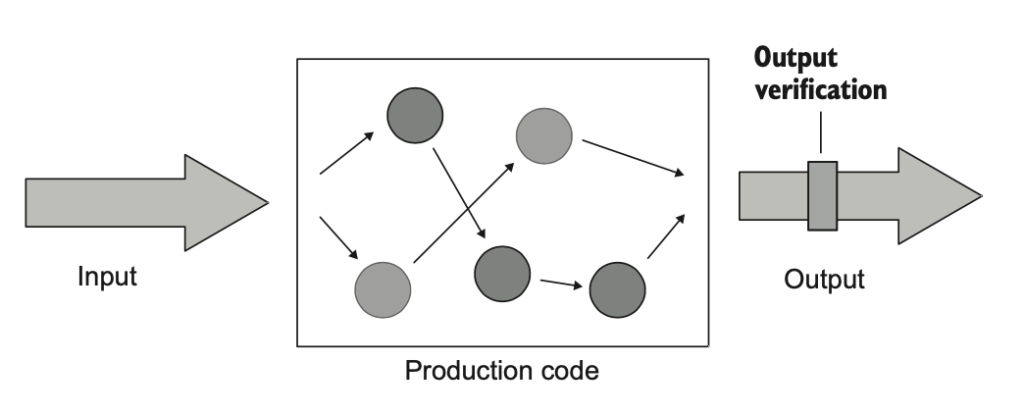
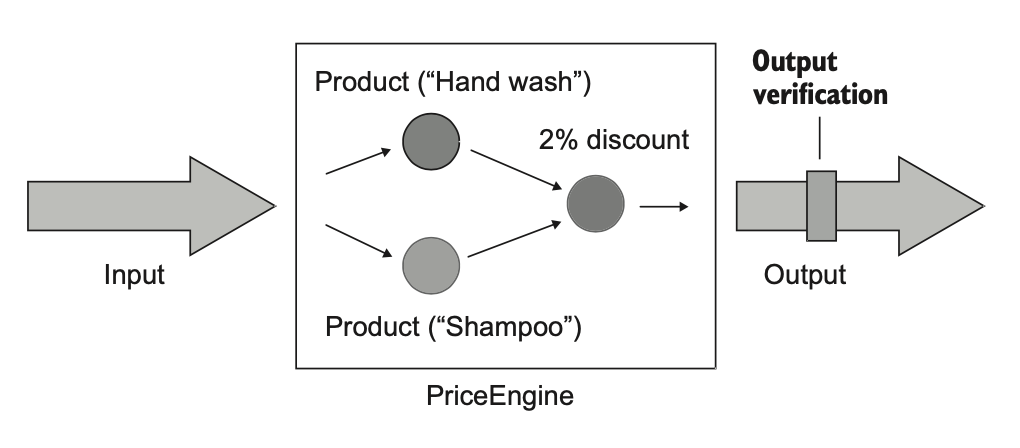
مثال زیر نمونهای از همین نوع کده و همراهش تستی هم هست که اون رو پوشش میده. کلاس «موتور قیمتگذاری» (Price Engine) یه آرایه از محصولات میگیره و مقدار تخفیف رو محاسبه میکنه.
public class PriceEngine
{
public decimal CalculateDiscount(params Product[] products)
{
decimal discount = products.Length * 0.01m;
return Math.Min(discount, 0.2m);
}
}
[Fact]
public void Discount_of_two_products()
{
var product1 = new Product("Hand wash");
var product2 = new Product("Shampoo");
var sut = new PriceEngine();
decimal discount = sut.CalculateDiscount(product1, product2);
Assert.Equal(0.02m, discount);
}کد ۶.۱
کلاس «موتور قیمتگذاری» تعداد محصولات رو در یک درصد ضرب میکنه و نتیجه رو هم حداکثر تا بیست درصد محدود نگه میداره. همین و بس. این کلاس نه محصولات رو توی یه مجموعهی داخلی ذخیره میکنه، نه اونا رو توی پایگاه داده مینویسه. تنها نتیجهی متد «محاسبهی تخفیف» همون مقداریه که برمیگردونه؛ یعنی خروجی نهایی.
سبک تست مبتنی بر خروجی رو یه جورایی «تابعی» هم میگن. این اسم از برنامهنویسی تابعی (Functional Programming) میاد؛ رویکردی که تأکیدش روی نوشتن کد بدون اثر جانبیه (بدون تغییر وضعیت بیرونی یا داخلی). در ادامهی فصل، بیشتر دربارهی برنامهنویسی تابعی و معماری تابعی صحبت میکنیم و میبینی این سبک چه ارتباطی با تست مبتنی بر خروجی داره.
۶.۱.۲ تعریف سبک مبتنی بر وضعیت
سبک مبتنی بر وضعیت یعنی بعد از اینکه یک عملیات انجام شد، وضعیت سیستم رو بررسی کنیم. منظور از «وضعیت» توی این سبک تست میتونه وضعیت خود واحد تحت تست (SUT)، وضعیت یکی از همکارهاش (Collaborator)، یا وضعیت یک وابستگی خارج از فرایند مثل پایگاه داده یا فایلسیستم باشه. به زبان ساده: تو ورودی میدی، عملیات انجام میشه، و بعد نگاه میکنی ببینی چه چیزی در سیستم تغییر کرده.
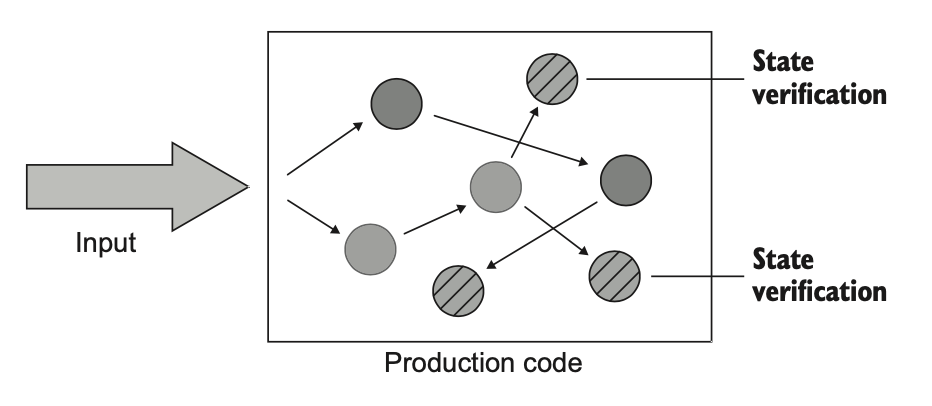
این هم یک نمونه از تست مبتنی بر وضعیت. کلاس «سفارش» (Order) به مشتری اجازه میده یک محصول جدید به سفارش اضافه کنه.
public class Order
{
private readonly List<Product> _products = new List<Product>();
public IReadOnlyList<Product> Products => _products.ToList();
public void AddProduct(Product product)
{
_products.Add(product);
}
}
[Fact]
public void Adding_a_product_to_an_order()
{
var product = new Product("Hand wash");
var sut = new Order();
sut.AddProduct(product);
Assert.Equal(1, sut.Products.Count);
Assert.Equal(product, sut.Products[0]);
}کد ۶.۲
توی این تست، بعد از اینکه محصول اضافه شد، مجموعهی محصولات بررسی میشه تا مطمئن بشیم تغییر درست انجام شده. برخلاف مثال تست مبتنی بر خروجی که قبلاً دیدیم، نتیجهی متد «اضافه کردن محصول» فقط یک مقدار بازگشتی نیست؛ خروجی واقعی این متد همون تغییریه که در وضعیت سفارش ایجاد میشه. یعنی خودِ تغییر وضعیت، نتیجهی تست محسوب میشه.
۶.۱.۳ تعریف سبک مبتنی بر ارتباطات
سومین سبک تست واحد، تست مبتنی بر ارتباطه. توی این سبک، از شبیهسازها (Mock) استفاده میکنی تا مطمئن بشی واحد تحت تست چطور با همکارهاش ارتباط برقرار میکنه. یعنی بهجای اینکه خروجی یا وضعیت نهایی رو بررسی کنی، تمرکزت روی اینه که «چه پیامی» و «چند بار» و «به کدوم همکار» ارسال شده.
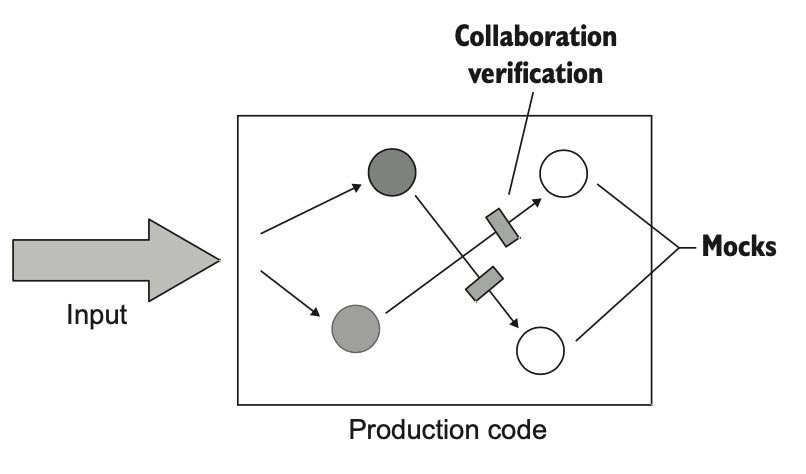
کد زیر نمونهای از تست مبتنی بر ارتباطاته.
[Fact]
public void Sending_a_greetings_email()
{
var emailGatewayMock = new Mock<IEmailGateway>();
var sut = new Controller(emailGatewayMock.Object);
sut.GreetUser("user@email.com");
emailGatewayMock.Verify(
x => x.SendGreetingsEmail("user@email.com"),
Times.Once);
}شکل ۶.۳
سبکها و مکتبهای تست واحد
مکتب کلاسیکِ تست واحد، سبک مبتنی بر وضعیت (State‑based) رو به سبک مبتنی بر ارتباط (Communication‑based) ترجیح میده. در مقابل، مکتب لندن دقیقاً برعکس عمل میکنه و اولویت رو به تست مبتنی بر ارتباط میده. البته هر دو مکتب، تست مبتنی بر خروجی (Output‑based) رو هم استفاده میکنن و این بخش بینشون مشترکه.
۶.۲ مقایسهی سه سبک تست واحد
هیچ چیز جدیدی دربارهی سبکهای مبتنی بر خروجی (Output‑based)، مبتنی بر وضعیت (State‑based)، و مبتنی بر ارتباط (Communication‑based) در تست واحد وجود نداره. در واقع، تو همین کتاب قبلاً هر سه سبک رو دیدی. چیزی که اینجا جذابش میکنه، مقایسهی این سبکها با همدیگهست؛ اون هم با استفاده از چهار ویژگی یک تست واحد خوب.
این چهار ویژگی رو دوباره مرور کنیم (برای جزئیات بیشتر به فصل ۴ مراجعه کن):
- محافظت در برابر خطاهای برگشتی (Regression Protection)
- مقاومت در برابر تغییرات کد (Refactoring Resistance)
- بازخورد سریع (Fast Feedback)
- قابلنگهداری بودن (Maintainability)
توی این مقایسه، هر کدوم از این چهار ویژگی رو جداگانه بررسی میکنیم.
۶.۲.۱ مقایسهی سبکها با معیارهای محافظت در برابر Regressions و سرعت بازخورد
بیایید اول این سه سبک رو از نظر دو ویژگی «محافظت در برابر خطاهای برگشتی» (Regression Protection) و «سرعت بازخورد» (Feedback Speed) مقایسه کنیم، چون این دو ویژگی در این مقایسه سادهترین و مستقیمترین معیارها هستن.
معیار محافظت در برابر خطاهای برگشتی به یک سبک خاص از تستنویسی وابسته نیست. این معیار حاصل سه ویژگیه:
- مقدار کدی که در طول تست اجرا میشه
- میزان پیچیدگی اون کد
- اهمیت دامنهای اون کد (Domain Significance)
بهطور کلی، میتونی تستی بنویسی که هر مقدار کدی رو که بخوای اجرا کنه—کم یا زیاد. هیچ سبک خاصی توی این بخش مزیت ویژهای نداره. همین موضوع دربارهی پیچیدگی کد و اهمیت دامنهای هم صدق میکنه.
تنها استثنا سبک مبتنی بر ارتباط (Communication‑based Testing) هست: استفادهی بیش از حد از این سبک میتونه باعث تستهای سطحی (Shallow Tests) بشه؛ تستهایی که فقط یک لایهی خیلی نازک از کد رو بررسی میکنن و بقیهی بخشها رو شبیهسازی (Mock) میکنن.
البته این سطحی بودن، ویژگی ذاتی این سبک نیست—بلکه نتیجهی استفادهی افراطی و نادرست از این تکنیکه.
بین سبکهای تست و سرعت بازخورد (Feedback Speed) هم ارتباط چندانی وجود نداره.
تا زمانی که تستهات با وابستگیهای خارج از فرایند (Out‑of‑process Dependencies) مثل دیتابیس یا فایلسیستم درگیر نشن و در محدودهی تست واحد باقی بمونن، همهی سبکها تقریباً سرعت اجرای مشابهی دارن.
تست مبتنی بر ارتباط ممکنه کمی کندتر باشه، چون شبیهسازها (Mocks) معمولاً در زمان اجرا کمی تأخیر اضافه میکنن. ولی این تفاوت آنقدر ناچیزه که فقط وقتی حس میشه که دهها هزار تست از این نوع داشته باشی.
۶.۲.۲ مقایسهی سبکها با معیار مقاومت در برابر بازآرایی
وقتی به معیار «مقاومت در برابر تغییرات کد» (Resistance to Refactoring) میرسیم، ماجرا فرق میکنه. این معیار اندازهگیری میکنه که تستها هنگام بازآرایی کد (Refactoring) چند تا هشدار اشتباه یا مثبت کاذب (False Positive) تولید میکنن. مثبت کاذب زمانی اتفاق میافته که تست به جزئیات پیادهسازی (Implementation Details) گره خورده باشه، نه به رفتار قابل مشاهده (Observable Behavior).
تست مبتنی بر خروجی (Output‑based Testing) بهترین محافظت رو در برابر مثبتهای کاذب ارائه میده، چون این تستها فقط به خودِ متد تحت تست (Method Under Test) وابسته هستن. تنها زمانی که این تستها به جزئیات پیادهسازی گره میخورن، اینه که خودِ متد تحت تست یک جزئیات پیادهسازی باشه.
تست مبتنی بر وضعیت (State‑based Testing) معمولاً بیشتر در معرض مثبتهای کاذبه. چون علاوه بر متد تحت تست، با وضعیت داخلی کلاس (Class State) هم کار میکنه. از نظر احتمالاتی، هرچقدر میزان اتصال (Coupling) بین تست و کد تولیدی بیشتر باشه، احتمال اینکه تست به یک جزئیات پیادهسازی نشتکرده (Leaking Implementation Detail) وابسته بشه هم بیشتره.
تستهای مبتنی بر وضعیت سطح بزرگتری از API رو لمس میکنن، و همین باعث میشه احتمال گره خوردنشون به جزئیات پیادهسازی بالاتر بره.
تست مبتنی بر ارتباط (Communication‑based Testing) بیشترین آسیبپذیری رو در برابر هشدارهای اشتباه یا مثبتهای کاذب (False Alarms / False Positives) داره. همونطور که از فصل ۵ یادت هست، بخش بزرگی از تستهایی که تعامل با جایگزینهای تست (Test Doubles) رو بررسی میکنن، در نهایت شکننده (Brittle) میشن. این موضوع همیشه دربارهی تعامل با استابها (Stub) صدق میکنه—هیچوقت نباید تعامل با استاب رو بررسی کنی.
استفاده از ماکها (Mock) فقط زمانی قابل قبوله که تعاملات از مرز برنامه عبور کنن (Crossing Application Boundary) و اثرات جانبی اون تعاملات (Side Effects) برای دنیای بیرون قابل مشاهده باشه. همونطور که میبینی، استفاده از تست مبتنی بر ارتباط نیازمند دقت و احتیاط بیشتریه تا مقاومت تستها در برابر تغییرات کد (Refactoring Resistance) حفظ بشه.
اما درست مثل سطحی بودن (Shallowness)، شکنندگی هم ویژگی ذاتی این سبک نیست. میتونی تعداد مثبتهای کاذب رو به حداقل برسونی، به شرط اینکه کپسولهسازی درست (Proper Encapsulation) رو رعایت کنی و تستهات رو فقط به رفتار قابل مشاهده (Observable Behavior) وصل کنی، نه به جزئیات پیادهسازی. البته میزان دقت و مراقبتی که لازم داری، بسته به سبک تست واحدی که استفاده میکنی فرق میکنه.
۶.۲.۳ مقایسهی سبکها با معیار قابلیت نگهداری
در نهایت، معیار «قابلنگهداری بودن» (Maintainability) ارتباط خیلی زیادی با سبکهای مختلف تست واحد داره؛ اما برخلاف «مقاومت در برابر تغییرات کد» (Refactoring Resistance)، اینجا کار زیادی برای کاهش اثراتش نمیتونی انجام بدی. قابلنگهداری بودن، هزینهی نگهداری تستها رو اندازهگیری میکنه و بر اساس دو ویژگی تعریف میشه:
- اینکه فهمیدن تست چقدر سخت باشه، که خودش تابعی از اندازهی تست (Test Size) هست
- اینکه اجرای تست چقدر سخت باشه، که تابعی از تعداد وابستگیهای خارج از فرایند (Out‑of‑process Dependencies) هست که تست مستقیماً باهاشون کار میکنه
تستهای بزرگتر قابلنگهداری کمتری دارن، چون فهمیدن یا تغییر دادنشون سختتره. به همین شکل، تستی که مستقیماً با یک یا چند وابستگی خارج از فرایند—مثل پایگاه داده—کار میکنه، قابلنگهداری کمتری داره. چون باید زمان بذاری تا اون وابستگیها رو سرپا نگه داری: مثلاً ریاستارت کردن سرور دیتابیس، حل مشکلات اتصال شبکه، و موارد مشابه.
قابلیت نگهداری تستهای مبتنی بر خروجی
در مقایسه با دو سبک دیگه، تست مبتنی بر خروجی (Output‑based Testing) بیشترین میزان قابلیت نگهداری رو داره. تستهایی که با این سبک نوشته میشن تقریباً همیشه کوتاه و جمعوجورن، و همین باعث میشه نگهداریشون سادهتر باشه. این مزیت از این واقعیت میاد که این سبک فقط به دو کار خلاصه میشه: دادن یک ورودی به متد و بررسی خروجی اون—که معمولاً با چند خط کد هم انجام میشه.
از اونجایی که کدی که با تست مبتنی بر خروجی پوشش داده میشه نباید وضعیت داخلی یا وضعیت سراسری (Global State) رو تغییر بده، این تستها هیچ تعاملی با وابستگیهای خارج از فرایند (Out‑of‑process Dependencies) ندارن. به همین دلیل، تستهای مبتنی بر خروجی از هر دو جنبهی قابلیت نگهداری—چه فهمیدن و چه اجرا—بهترین عملکرد رو دارن.
قابلیت نگهداری تستهای مبتنی بر وضعیت
تستهای مبتنی بر وضعیت (State‑based Tests) معمولاً نسبت به تستهای مبتنی بر خروجی (Output‑based Tests) قابلیت نگهداری کمتری دارن. دلیلش هم اینه که بررسی وضعیت (State Verification) معمولاً فضای بیشتری میگیره و مفصلتر از بررسی خروجیه.
در ادامه، یک نمونهی دیگه از تست مبتنی بر وضعیت آورده شده.
[Fact]
public void Adding_a_comment_to_an_article()
{
var sut = new Article();
var text = "Comment text";
var author = "John Doe";
var now = new DateTime(2019, 4, 1);
sut.AddComment(text, author, now);
// Verifies the state of the article
Assert.Equal(1, sut.Comments.Count);
Assert.Equal(text, sut.Comments[0].Text);
Assert.Equal(author, sut.Comments[0].Author);
Assert.Equal(now, sut.Comments[0].DateCreated);
}کد ۶.۴
این تست یک کامنت رو به یک مقاله اضافه میکنه و بعد بررسی میکنه که آیا اون کامنت در فهرست کامنتهای مقاله ظاهر شده یا نه. با اینکه این تست سادهسازی شده و فقط یک کامنت داره، بخش بررسی (Assertion) همین تستِ ساده هم چهار خط طول میکشه. تستهای مبتنی بر وضعیت (State‑based Tests) معمولاً مجبور میشن دادههای خیلی بیشتری رو بررسی کنن، و به همین دلیل اندازهشون میتونه بهطور قابلتوجهی بزرگ بشه.
میتونی این مشکل رو با معرفی متدهای کمکی (Helper Methods) کاهش بدی—متدهایی که بخش زیادی از کد رو پنهان میکنن و تست رو کوتاهتر نشون میدن (طبق کد ۶.۵). اما نوشتن و نگهداری این متدهای کمکی خودش تلاش زیادی میطلبه. این تلاش فقط زمانی توجیه داره که این متدها قرار باشن در چندین تست مختلف استفاده بشن—که معمولاً هم اینطور نیست. در بخش سوم کتاب، بیشتر دربارهی متدهای کمکی توضیح داده میشه.
[Fact]
public void Adding_a_comment_to_an_article()
{
var sut = new Article();
var text = "Comment text";
var author = "John Doe";
var now = new DateTime(2019, 4, 1);
sut.AddComment(text, author, now);
// Helper methods
sut.ShouldContainNumberOfComments(1)
.WithComment(text, author, now);
}کد ۶.۵
راه دیگهای برای کوتاهتر کردن یک تست مبتنی بر وضعیت اینه که برای کلاسی که قرار هست روی اون Assertion انجام بشه، اعضای برابری (Equality Members) تعریف کنی. در کد ۶.۶، این کلاس Comment هست. میتونی این کلاس رو به یک Value Object تبدیل کنی—یعنی کلاسی که نمونههاش بر اساس مقدار مقایسه میشن، نه بر اساس Reference. این کار تست رو هم سادهتر میکنه، مخصوصاً اگر از یک کتابخانهی Assertion مثل Fluent Assertions هم استفاده کنی.
[Fact]
public void Adding_a_comment_to_an_article()
{
var sut = new Article();
var comment = new Comment(
"Comment text",
"John Doe",
new DateTime(2019, 4, 1));
sut.AddComment(comment.Text, comment.Author, comment.DateCreated);
sut.Comments.Should().BeEquivalentTo(comment);
}کد ۶.۶
این تست از این واقعیت استفاده میکنه که کامنتها رو میشه بهصورت یک «مقدار کامل» با هم مقایسه کرد، بدون اینکه لازم باشه تکتک ویژگیهاشون رو جداگانه بررسی کنیم. همچنین از متد BeEquivalentTo در کتابخانهی Fluent Assertions استفاده میکنه؛ متدی که میتونه کل مجموعهها رو با هم مقایسه کنه و در نتیجه نیاز به بررسی اندازهی مجموعه رو هم از بین میبره.
این یک تکنیک قدرتمنده، اما فقط زمانی جواب میده که کلاس ذاتاً یک «مقدار» باشه و بشه اون رو به یک Value Object تبدیل کرد. در غیر این صورت، این کار باعث آلودگی کد (Code Pollution) میشه—یعنی اضافه کردن کدی به بخش تولیدی که تنها هدفش سادهتر کردن تست واحده، نه حل یک نیاز واقعی در دامنه. در فصل ۱۱ دربارهی آلودگی کد و سایر ضدالگوهای تست واحد بیشتر صحبت میکنیم.
همونطور که میبینی، این دو تکنیک—استفاده از متدهای کمکی و تبدیل کلاسها به Value Object—فقط در موارد خاص قابل استفادهان. و حتی وقتی هم قابل استفاده باشن، تستهای مبتنی بر وضعیت همچنان فضای بیشتری نسبت به تستهای مبتنی بر خروجی اشغال میکنن و در نتیجه کمتر قابلنگهداری باقی میمونن.
قابلیت نگهداری تستهای مبتنی بر ارتباطات
تستهای مبتنی بر ارتباط (Communication‑based Tests) از نظر معیار قابلیت نگهداری عملکرد ضعیفتری نسبت به تستهای مبتنی بر خروجی و مبتنی بر وضعیت دارن. این سبک تست نیاز داره که جایگزینهای تست (Test Doubles) رو تنظیم کنی و تعاملات رو بررسی (Assert Interactions) کنی، و همین خودش فضای زیادی از تست رو اشغال میکنه.
وقتی زنجیرههای ماک (Mock Chains) هم وارد ماجرا میشن—یعنی ماک یا استابی که یک ماک دیگه برمیگردونه، و اون یکی هم یک ماک دیگه، و همینطور چند لایه پشت سر هم—تستها حتی بزرگتر و سختتر برای نگهداری میشن.
۶.۲.۴ مقایسهی سبکها: نتایج
حالا بیایید سبکهای مختلف تست واحد رو با استفاده از ویژگیهای یک تست واحد خوب مقایسه کنیم. جدول ۶.۱ خلاصهی نتایج این مقایسه رو نشون میده. همونطور که در بخش ۶.۲.۱ گفته شد، هر سه سبک از نظر «محافظت در برابر خطاهای برگشتی» و «سرعت بازخورد» امتیاز یکسانی دارن؛ بنابراین این دو معیار از مقایسه حذف شدن.
تست مبتنی بر خروجی (Output‑based Testing) بهترین نتایج رو نشون میده. این سبک تستهایی تولید میکنه که بهندرت به جزئیات پیادهسازی (Implementation Details) گره میخورن و بنابراین برای حفظ مقاومت در برابر تغییرات کد (Refactoring Resistance) نیاز به مراقبت و دقت زیادی ندارن. این تستها همچنین بهخاطر کوتاه و جمعوجور بودن و نداشتن وابستگیهای خارج از فرایند (Out‑of‑process Dependencies)، بیشترین میزان قابلیت نگهداری رو دارن.
| معیار مقایسه | تست مبتنی بر خروجی | تست مبتنی بر وضعیت | تست مبتنی بر ارتباطات |
|---|---|---|---|
| میزان دقت لازم برای حفظ مقاومت در برابر بازآرایی | کم | متوسط | متوسط |
| هزینههای نگهداری | کم | متوسط | زیاد |
تستهای مبتنی بر وضعیت (State‑based) و مبتنی بر ارتباط (Communication‑based) در هر دو معیار عملکرد ضعیفتری دارن. این تستها بیشتر در معرض این هستن که به یک جزئیات پیادهسازی نشتکرده (Leaking Implementation Detail) گره بخورن، و همچنین بهخاطر بزرگتر بودن، هزینهی نگهداری بالاتری ایجاد میکنن.
همیشه تست مبتنی بر خروجی (Output‑based Testing) رو به بقیه ترجیح بده. متأسفانه گفتنش خیلی راحتتر از انجامشه. این سبک تست فقط زمانی قابل استفادهست که کد به شکل «تابعی» (Functional) نوشته شده باشه—چیزی که در اکثر زبانهای شیءگرا خیلی کم اتفاق میافته. با این حال، تکنیکهایی وجود داره که میتونی با استفاده از اونها بخش بیشتری از تستهات رو به سمت سبک مبتنی بر خروجی منتقل کنی.
باقی این فصل نشون میده چطور از تستهای مبتنی بر وضعیت و مبتنی بر همکاری (Collaboration‑based) به تست مبتنی بر خروجی مهاجرت کنی. این مهاجرت نیاز داره که کدت رو «تابعیتر» (More Purely Functional) کنی، و همین تغییر باعث میشه بتونی بهجای تستهای مبتنی بر وضعیت یا ارتباط، از تستهای مبتنی بر خروجی استفاده کنی.
۶.۳ آشنایی با معماری تابعی
برای اینکه بتونم روش انجام این انتقال رو نشون بدم، اول باید یکسری مقدمات رو آماده کنیم. در این بخش، میبینی که برنامهنویسی تابعی (Functional Programming) و معماری تابعی (Functional Architecture) چی هستن و اینکه معماری تابعی چه ارتباطی با معماری ششضلعی (Hexagonal Architecture) داره. بخش ۶.۴ این انتقال رو با یک مثال عملی توضیح میده.
توجه داشته باش که اینجا قرار نیست وارد یک بررسی عمیق از برنامهنویسی تابعی بشیم؛ هدف فقط توضیح اصول پایهای پشت این رویکرده. همین اصول پایهای برای درک ارتباط بین برنامهنویسی تابعی و تست مبتنی بر خروجی (Output‑based Testing) کافی هستن.
۶.۳.۱ برنامهنویسی تابعی چیست؟
همونطور که در بخش ۶.۱.۱ اشاره کردم، سبک تست واحد مبتنی بر خروجی (Output‑based) رو تابعی (Functional) هم مینامن. دلیلش اینه که این سبک تست نیاز داره کد تولیدی زیرین بهصورت کاملاً تابعی و با استفاده از برنامهنویسی تابعی نوشته شده باشه. خب، برنامهنویسی تابعی چیه؟
برنامهنویسی تابعی یعنی برنامهنویسی با توابع ریاضی. یک تابع ریاضی—که بهش تابع خالص (Pure Function) هم میگن—تابعی هست که هیچ ورودی یا خروجی پنهانی نداره. تمام ورودیها و خروجیهای یک تابع ریاضی باید بهطور کامل و شفاف در امضای متد (Method Signature) مشخص شده باشن؛ یعنی در نام متد، آرگومانها، و نوع خروجی.
یک تابع ریاضی برای یک ورودی مشخص، همیشه خروجی یکسانی تولید میکنه—فرقی نمیکنه چند بار فراخوانی بشه.
بیایید متد CalculateDiscount() از کد ۶.۱ رو بهعنوان مثال در نظر بگیریم (برای راحتی دوباره اون رو اینجا آورده شده):
public decimal CalculateDiscount(Product[] products)
{
decimal discount = products.Length * 0.01m;
return Math.Min(discount, 0.2m);
}این متد یک ورودی داره (یک آرایهی Product) و یک خروجی (مقدار decimal مربوط به تخفیف). هر دوی اینها بهصورت کاملاً شفاف در امضای متد مشخص شدن. هیچ ورودی یا خروجی پنهانی وجود نداره. همین ویژگیها باعث میشن CalculateDiscount یک «تابع ریاضی» یا تابع خالص (Pure Function) محسوب بشه (مطابق شکل ۶.۵).
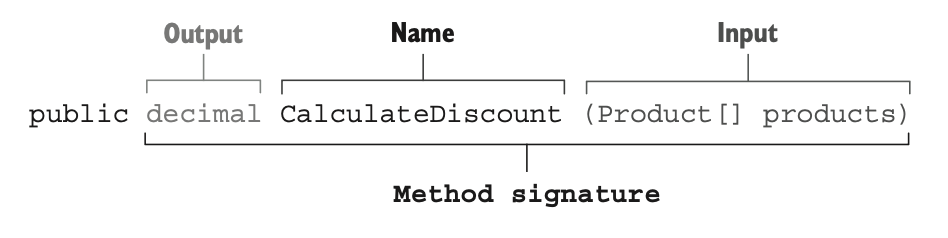
متدهایی که هیچ ورودی یا خروجی پنهانی ندارن، توابع ریاضی (Mathematical Functions) نامیده میشن، چون دقیقاً با تعریف یک تابع در ریاضیات مطابقت دارن.
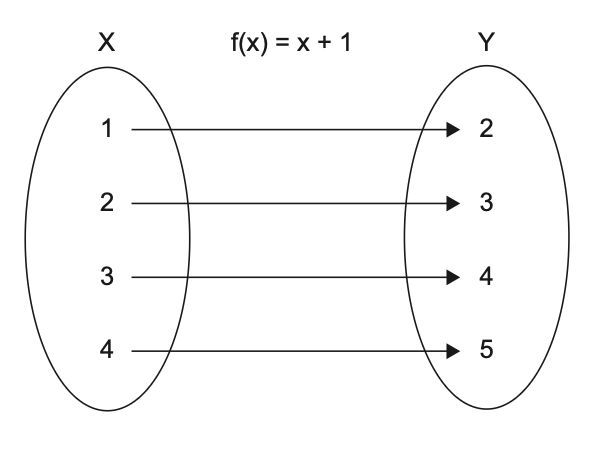
تعریف: در ریاضیات، یک تابع رابطهای بین دو مجموعه است که برای هر عنصر در مجموعهی اول، دقیقاً یک عنصر در مجموعهی دوم پیدا میکند.
شکل ۶.۶ نشان میدهد که چگونه برای هر عدد ورودی x، تابع f(x)=x+1 یک عدد متناظر y پیدا میکند. شکل ۶.۷ هم متد CalculateDiscount را با همان نمادگذاری شکل ۶.۶ نمایش میدهد.
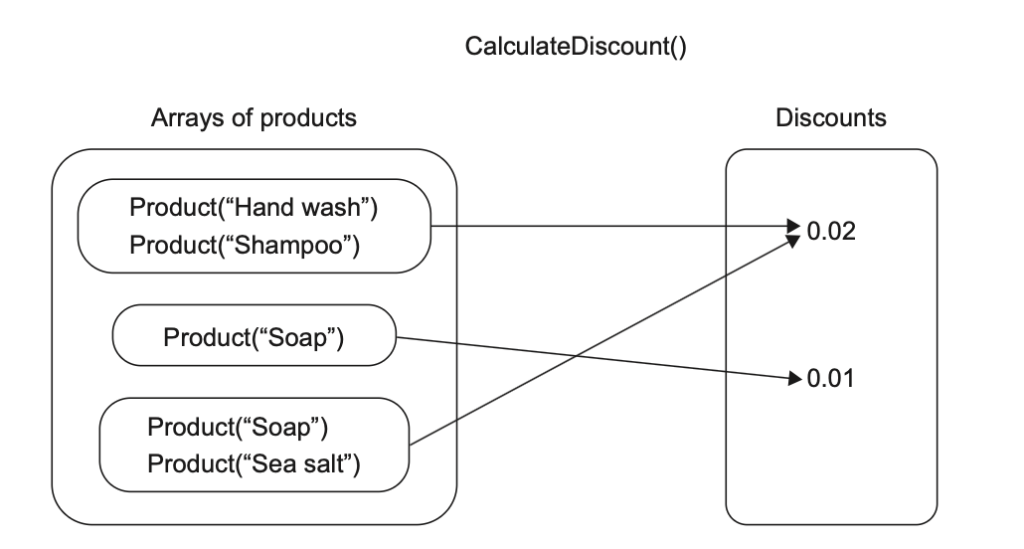
CalculateDiscount() با همان نمادگذاری تابع ( f(x) = x + 1 ) نمایش داده شده است. برای هر آرایهی ورودی از محصولات، این متد یک تخفیف متناظر بهعنوان خروجی پیدا میکند.ورودیها و خروجیهای صریح باعث میشن توابع ریاضی بهشدت قابل تست باشن، چون تستهایی که برای این توابع نوشته میشن کوتاه، ساده، قابلفهم و راحت برای نگهداری هستن. توابع ریاضی تنها نوع متدهایی هستن که میتونی روی اونها تست مبتنی بر خروجی (Output‑based Testing) اعمال کنی—سبکی که بهترین قابلیت نگهداری رو داره و کمترین احتمال تولید مثبت کاذب (False Positive) رو ایجاد میکنه.
در مقابل، ورودیها و خروجیهای پنهان باعث میشن کد کمتر قابل تست بشه (و البته کمتر قابل خواندن هم). این ورودیها و خروجیهای پنهان شامل موارد زیر هستن:
- عوارض جانبی (Side Effects): عارضهی جانبی خروجیه که در امضای متد بیان نشده و بنابراین پنهانه. مثلاً وقتی یک عملیات وضعیت یک شیء رو تغییر میده، یا فایلی روی دیسک رو بهروزرسانی میکنه، یک Side Effect ایجاد شده.
- استثناها (Exceptions): وقتی یک متد Exception پرتاب میکنه، یک مسیر جدید در جریان اجرای برنامه ایجاد میکنه که قرارداد تعریفشده توسط امضای متد رو دور میزنه. این Exception میتونه در هرجای Call Stack گرفته بشه، و همین باعث میشه یک خروجی اضافی ایجاد بشه که امضای متد هیچ اشارهای بهش نداره.
- ارجاع به وضعیت داخلی یا خارجی (Internal/External State): برای مثال، یک متد میتونه تاریخ و زمان فعلی رو از یک ویژگی استاتیک مثل
DateTime.Nowبگیره. میتونه از دیتابیس داده بخونه، یا به یک فیلد خصوصی قابل تغییر (Mutable Field) دسترسی داشته باشه. همهی اینها ورودیهایی هستن که در امضای متد وجود ندارن و بنابراین پنهان محسوب میشن.
یک قاعدهی سرانگشتی خوب برای تشخیص اینکه آیا یک متد یک «تابع ریاضی» هست یا نه اینه که ببینی آیا میتونی فراخوانی اون متد رو با مقدار بازگشتیاش جایگزین کنی بدون اینکه رفتار برنامه تغییر کنه. این قابلیت که بتونی یک فراخوانی متد رو با مقدار متناظر اون جایگزین کنی، شفافیت ارجاعی (Referential Transparency) نامیده میشه.
به مثال زیر نگاه کن:
public int Increment(int x)
{
return x + 1;
}این متد یک تابع ریاضیه، چون این دو عبارت معادل همدیگن:
int y = Increment(4);
int y = 5;از طرف دیگه، متد زیر یک تابع ریاضی محسوب نمیشه. نمیتونی فراخوانی این متد رو با مقدار بازگشتیاش جایگزین کنی، چون مقدار بازگشتی همهی خروجیهای متد رو پوشش نمیده. در این مثال، خروجی پنهان تغییر در فیلد x هست—یعنی یک Side Effect:
int x = 0;
public int Increment()
{
x++;
return x;
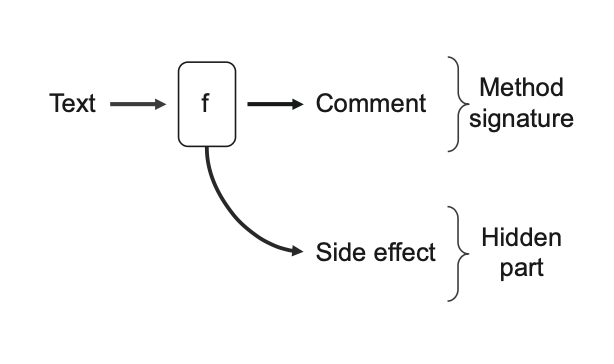
}اثرات جانبی رایجترین نوع خروجیهای پنهان هستن. کد بعدی یک متد AddComment رو نشون میده که در ظاهر شبیه یک تابع ریاضی به نظر میرسه، اما در واقع تابع ریاضی نیست. شکل ۶.۸ این متد رو بهصورت گرافیکی نمایش میده.
public Comment AddComment(string text)
{
var comment = new Comment(text);
_comments.Add(comment); // Side effect
return comment;
}کد ۶.۷
۶.۳.۲ معماری تابعی چیست؟
طبیعتاً نمیتونی برنامهای بسازی که هیچ اثر جانبی (Side Effect) نداشته باشه. چنین برنامهای عملاً بیفایده خواهد بود. در نهایت، همهی برنامهها برای ایجاد اثر جانبی ساخته میشن: بهروزرسانی اطلاعات کاربر، اضافه کردن یک خط سفارش جدید به سبد خرید، و موارد مشابه.
هدف برنامهنویسی تابعی (Functional Programming) این نیست که اثرهای جانبی رو بهطور کامل حذف کنه، بلکه اینه که بین کدی که منطق تجاری (Business Logic) رو مدیریت میکنه و کدی که اثر جانبی ایجاد میکنه جداسازی (Separation) برقرار کنه. هر کدوم از این دو مسئولیت بهاندازهی کافی پیچیده هستن؛ ترکیب کردنشون پیچیدگی رو چند برابر میکنه و در بلندمدت نگهداری کد رو سختتر میکنه. اینجاست که معماری تابعی (Functional Architecture) وارد عمل میشه. این معماری منطق تجاری رو از اثرهای جانبی جدا میکنه، با این روش که اثرهای جانبی رو به «لبههای عملیات تجاری» منتقل میکنه.
تعریف: معماری تابعی بیشترین میزان کد رو بهصورت کاملاً تابعی (Immutable) مینویسه و کمترین میزان کد رو به بخشهایی اختصاص میده که با اثرهای جانبی سروکار دارن. Immutable یعنی «غیرقابل تغییر»: وقتی یک شیء ساخته شد، وضعیتش دیگه قابل تغییر نیست. این در تضاد با شیء قابل تغییر (Mutable) قرار میگیره که بعد از ساخته شدن میشه وضعیتش رو تغییر داد.
این جداسازی بین منطق تجاری و اثرهای جانبی با تفکیک دو نوع کد انجام میشه:
- کدی که تصمیم میگیره (Decision‑making Code): این کد نیازی به اثر جانبی نداره و بنابراین میشه اون رو با توابع ریاضی (Mathematical Functions) نوشت.
- کدی که بر اساس تصمیم عمل میکنه (Decision‑acting Code): این کد همهی تصمیمهای گرفتهشده توسط توابع ریاضی رو به خروجیهای قابل مشاهده تبدیل میکنه، مثل تغییرات در پایگاه داده (Database) یا ارسال پیام به یک Message Bus.
کدی که تصمیمها رو میگیره معمولاً بهعنوان هستهی تابعی (Functional Core) یا هستهی غیرقابل تغییر (Immutable Core) شناخته میشه. کدی که بر اساس اون تصمیمها عمل میکنه یک پوستهی قابل تغییر (Mutable Shell) هست (مطابق شکل ۶.۹).
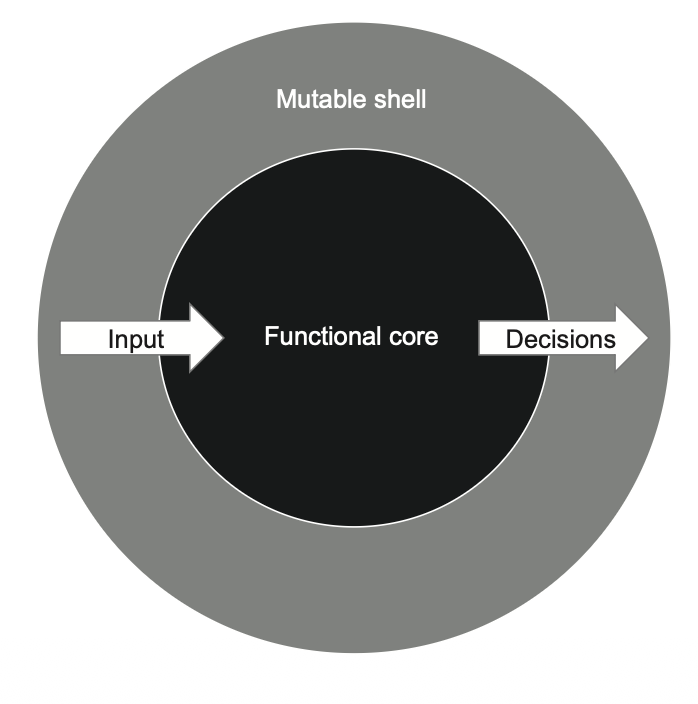
هستهی تابعی (Functional Core) و پوستهی قابل تغییر (Mutable Shell) به این شکل با هم همکاری میکنن:
- پوستهی قابل تغییر (Mutable Shell) همهی ورودیها رو جمعآوری میکنه.
- هستهی تابعی (Functional Core) تصمیمها رو تولید میکنه.
- پوسته (Shell) اون تصمیمها رو به اثرهای جانبی (Side Effects) تبدیل میکنه.
برای حفظ جداسازی درست بین این دو لایه، باید مطمئن بشی کلاسهایی که تصمیمها رو نمایش میدن، اطلاعات کافی در خودشون داشته باشن تا پوستهی قابل تغییر بتونه بدون نیاز به تصمیمگیری اضافه بر اساس اونها عمل کنه. به عبارت دیگه، پوستهی قابل تغییر باید تا حد ممکن ساده و بدون هوش (Dumb) باشه.
هدف اینه که هستهی تابعی رو بهطور گسترده با تستهای مبتنی بر خروجی (Output‑based Tests) پوشش بدی و پوستهی قابل تغییر رو فقط با تعداد کمی تست یکپارچهسازی (Integration Tests) بررسی کنی.
کپسولهسازی و تغییرناپذیری
مثل کپسولهسازی (Encapsulation)، معماری تابعی (Functional Architecture) بهطور کلی و تغییرناپذیری (Immutability) بهطور خاص، همگی یک هدف مشترک با تست واحد (Unit Testing) دارن: ایجاد امکان رشد پایدار برای پروژهی نرمافزاری. در واقع، یک ارتباط عمیق بین مفهومهای کپسولهسازی و تغییرناپذیری وجود داره.
همونطور که احتمالاً از فصل ۵ به یاد داری، کپسولهسازی یعنی محافظت از کد در برابر ناسازگاریها. کپسولهسازی از درونیات کلاس در برابر خرابی محافظت میکنه از طریق:
- کاهش سطح رابطهای عمومی (public API) که اجازهی تغییر اطلاعات رو میدن.
- قرار دادن رابطهای باقیمانده تحت کنترل دقیق (Scrutiny).
تغییرناپذیری (Immutability) همین مسئلهی حفظ قواعد (Invariants) رو از زاویهی دیگهای حل میکنه. وقتی کلاسها تغییرناپذیر باشن، دیگه لازم نیست نگران خرابی وضعیت باشی، چون چیزی که از ابتدا قابل تغییر نیست، نمیتونه خراب بشه. در نتیجه، در برنامهنویسی تابعی (Functional Programming) نیازی به کپسولهسازی وجود نداره. کافیه وضعیت کلاس رو فقط یک بار، هنگام ساخت نمونه (Instance) اعتبارسنجی کنی. بعد از اون میتونی این نمونه رو آزادانه در کل برنامه پاس بدی. وقتی همهی دادهها تغییرناپذیر باشن، کل مجموعهی مشکلات ناشی از نبود کپسولهسازی بهطور کامل از بین میره.
یک نقلقول عالی از مایکل فیدرز (Michael Feathers) در این زمینه وجود داره:
برنامهنویسی شیءگرا (Object‑oriented Programming) کد رو با کپسولهسازی بخشهای متحرک قابل فهم میکنه. برنامهنویسی تابعی (Functional Programming) کد رو با به حداقل رساندن بخشهای متحرک قابل فهم میکنه.
۶.۳.۳ مقایسهی معماری تابعی و معماری ششضلعی
شباهتهای زیادی بین معماری تابعی (Functional Architecture) و معماری ششضلعی (Hexagonal Architecture) وجود داره. هر دوی این معماریها حول ایدهی تفکیک مسئولیتها (Separation of Concerns) ساخته شدن. البته جزئیات این جداسازی با هم فرق میکنه.
همونطور که احتمالاً از فصل ۵ به یاد داری، معماری ششضلعی بین لایهی دامنه (Domain Layer) و لایهی سرویسهای کاربردی (Application Services Layer) تفاوت قائل میشه (شکل ۶.۱۰). لایهی دامنه مسئول منطق تجاری (Business Logic) هست، در حالی که لایهی سرویسهای کاربردی مسئول ارتباط با برنامههای خارجی مثل پایگاه داده (Database) یا سرویس SMTP. این موضوع خیلی شبیه معماری تابعی هست، جایی که جداسازی بین تصمیمها (Decisions) و اقدامها (Actions) معرفی میشه.
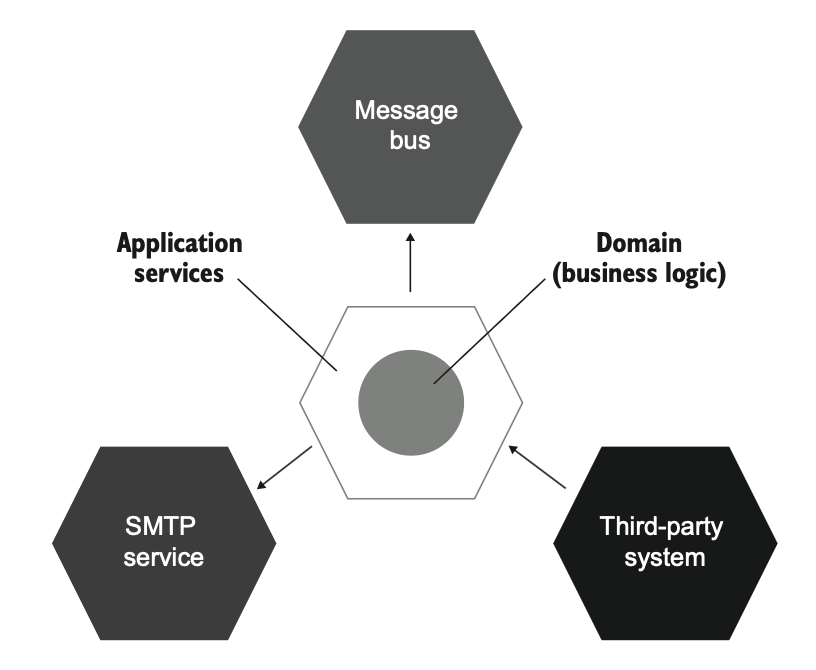
شباهت دیگه بین این دو، جریان یکطرفهی وابستگیها (One‑way Flow of Dependencies) هست. در معماری ششضلعی، کلاسهای داخل لایهی دامنه فقط باید به همدیگه وابسته باشن؛ نباید به کلاسهای لایهی سرویسهای کاربردی وابسته باشن. به همین شکل، هستهی غیرقابل تغییر (Immutable Core) در معماری تابعی به پوستهی قابل تغییر (Mutable Shell) وابسته نیست. این هسته خودکفا (Self‑sufficient) هست و میتونه مستقل از لایههای بیرونی کار کنه. همین ویژگی باعث میشه معماری تابعی بهشدت قابل تست باشه: میتونی هستهی غیرقابل تغییر رو کاملاً از پوسته جدا کنی و ورودیهایی که پوسته فراهم میکنه رو با مقادیر ساده شبیهسازی کنی.
تفاوت اصلی بین این دو در نحوهی برخورد با اثرهای جانبی (Side Effects) هست. معماری تابعی همهی اثرهای جانبی رو از هستهی غیرقابل تغییر بیرون میبره و اونها رو به لبههای عملیات تجاری منتقل میکنه. این لبهها توسط پوستهی قابل تغییر مدیریت میشن. در مقابل، معماری ششضلعی با اثرهای جانبی ایجادشده توسط لایهی دامنه مشکلی نداره، به شرطی که این اثرها فقط محدود به همون لایه باشن و از مرز اون عبور نکنن. برای مثال، یک نمونهی کلاس دامنه نمیتونه چیزی رو مستقیماً در پایگاه داده ذخیره کنه، اما میتونه وضعیت خودش رو تغییر بده. سپس یک سرویس کاربردی این تغییر رو دریافت میکنه و اون رو در پایگاه داده اعمال میکنه.
نکته: معماری تابعی یک زیرمجموعه (Subset) از معماری ششضلعی محسوب میشه. میتونی معماری تابعی رو بهعنوان معماری ششضلعی در حالت افراطی (Taken to an Extreme) در نظر بگیری.
۶.۴ گذار به معماری تابعی و تستهای مبتنی بر خروجی
در این بخش، یک برنامهی نمونه رو برمیداریم و اون رو به سمت معماری تابعی (Functional Architecture) بازآرایی (Refactor) میکنیم. دو مرحلهی بازآرایی رو خواهیم دید:
- انتقال از استفاده از یک وابستگی خارج از فرایند (Out‑of‑process Dependency) به استفاده از ماکها (Mocks)
- انتقال از استفاده از ماکها به استفاده از معماری تابعی (Functional Architecture)
این انتقال روی کد تست هم تأثیر میذاره! ما تستهای مبتنی بر وضعیت (State‑based Tests) و تستهای مبتنی بر ارتباط (Communication‑based Tests) رو به سبک تست واحد مبتنی بر خروجی (Output‑based Unit Testing) بازآرایی میکنیم.
قبل از شروع بازآرایی، بیایید پروژهی نمونه و تستهایی که اون رو پوشش میدن مرور کنیم.
۶.۴.۱ معرفی یک سیستم ممیزی
پروژهی نمونه یک سیستم ثبت رفتوآمد (Audit System) که ورود همهی بازدیدکنندههای یک سازمان رو ثبت میکنه. برای ذخیرهسازی هم از فایلهای متنی ساده (Flat Text Files) استفاده میکنه؛ همون ساختاری که توی شکل ۶.۱۱ نشون داده شده.
سیستم اسم بازدیدکننده و زمان ورودش رو برمیداره و به آخرین فایل موجود اضافه میکنه. وقتی تعداد رکوردهای یک فایل به سقف مجازش رسید، یه فایل جدید ساخته میشه و شمارهی فایل هم یکی زیاد میشه.
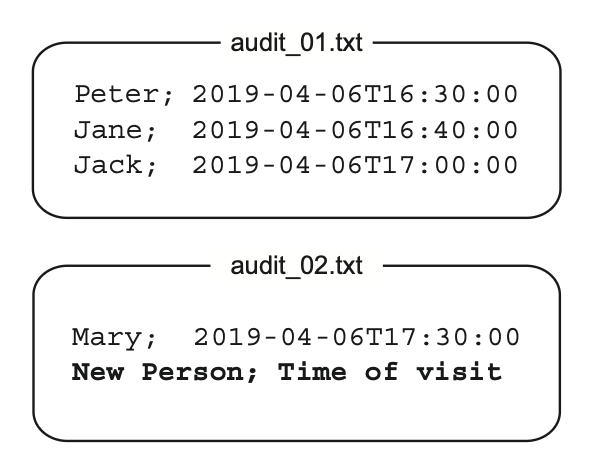
کد زیر نسخهی اولیهی سیستم رو نشون میده.
public class AuditManager
{
private readonly int _maxEntriesPerFile;
private readonly string _directoryName;
public AuditManager(int maxEntriesPerFile, string directoryName)
{
_maxEntriesPerFile = maxEntriesPerFile;
_directoryName = directoryName;
}
public void AddRecord(string visitorName, DateTime timeOfVisit)
{
string[] filePaths = Directory.GetFiles(_directoryName);
(int index, string path)[] sorted = SortByIndex(filePaths);
string newRecord = visitorName + ";" + timeOfVisit;
if (sorted.Length == 0)
{
string newFile = Path.Combine(_directoryName, "audit_1.txt");
File.WriteAllText(newFile, newRecord);
return;
}
(int currentFileIndex, string currentFilePath) = sorted.Last();
List<string> lines = File.ReadAllLines(currentFilePath).ToList();
if (lines.Count < _maxEntriesPerFile)
{
lines.Add(newRecord);
string newContent = string.Join("\r\n", lines);
File.WriteAllText(currentFilePath, newContent);
}
else
{
int newIndex = currentFileIndex + 1;
string newName = $"audit_{newIndex}.txt";
string newFile = Path.Combine(_directoryName, newName);
File.WriteAllText(newFile, newRecord);
}
}
}کد ۶.۸
کد شاید در نگاه اول کمی بزرگ به نظر بیاد، اما واقعاً سادهست. کلاس AuditManager کلاس اصلی برنامهست. سازندهی این کلاس (Constructor) دو تا پارامتر پیکربندی میگیره: حداکثر تعداد رکوردهای مجاز در هر فایل، و مسیر پوشهی کاری (Working Directory).
این کلاس فقط یک متد عمومی داره: AddRecord و همین متد تمام کارهای سیستم ممیزی رو انجام میده:
- لیست کامل فایلها رو از پوشهی کاری میگیره
- فایلها رو بر اساس شمارهی داخل اسمشون مرتب میکنه (همهی فایلها یک الگوی ثابت دارن:
audit_{index}.txt— مثلاًaudit_1.txt) - اگر هنوز هیچ فایل ممیزی وجود نداشته باشه، یک فایل جدید میسازه و یک رکورد داخلش مینویسه
- اگر فایل وجود داشته باشه، آخرین فایل رو برمیداره و بسته به اینکه تعداد رکوردهای اون فایل به سقف رسیده یا نه، یا رکورد جدید رو به همون فایل اضافه میکنه، یا یک فایل جدید با شمارهی بالاتر میسازه
کلاس AuditManager در حالت فعلی تست کردنش خیلی سخت هست، چون بهشدت به فایلسیستم (File System) وابستهست. برای تست کردنش باید قبل از اجرای تست، فایلها رو در مسیر درست قرار بدی، و بعد از اجرای تست هم باید فایلها رو بخونی، محتواشون رو بررسی کنی، و در نهایت همه رو پاک کنی (شکل ۶.۱۲).
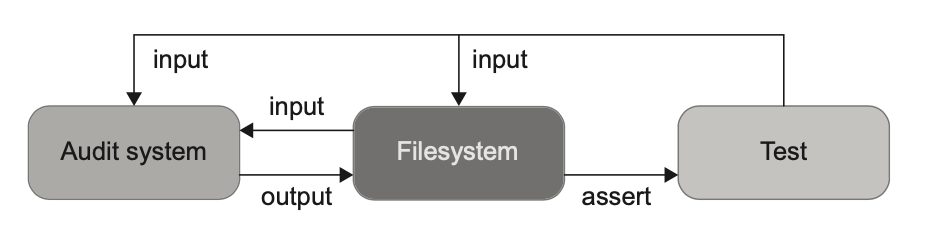
نمیتونی این نوع تستها رو بهصورت موازی (Parallelize) اجرا کنی—حداقل نه بدون اینکه کلی کار اضافه انجام بدی که خودش هزینهی نگهداری رو حسابی بالا میبره. گلوگاه اصلی هم فایلسیستم (Filesystem) هست: چون یک وابستگی مشترکه و تستها میتونن از طریقش توی جریان اجرای همدیگه دخالت کنن.
فایلسیستم باعث میشه تستها کند هم بشن. از نظر نگهداری هم اوضاع خوب نیست، چون باید مطمئن باشی پوشهی کاری (Working Directory) وجود داره و تستها بهش دسترسی دارن— چه روی سیستم خودت، چه روی سرور بیلد (Build Server).
جدول ۶.۲ هم خلاصهی امتیازدهی این وضعیت رو نشون میده.
| معیار | امتیاز نسخه اولیه |
|---|---|
| محافظت در برابر بازگشت خطاها | خوب |
| مقاومت در برابر بازآرایی | خوب |
| بازخورد سریع | بد |
| نگهداریپذیری | بد |
| راستی، تستهایی که مستقیماً با فایلسیستم (Filesystem) کار میکنن، اصلاً در تعریف تست واحد (Unit Test) جا نمیگیرن. این تستها با ویژگی دوم و سوم یک تست واحد سازگار نیستن، و همین باعث میشه در عمل تبدیل بشن به تست یکپارچهسازی (Integration Tests) (برای جزئیات بیشتر، فصل ۲ رو ببین). یک تست واحد باید: |
- فقط یک «واحد رفتار» رو بررسی کنه،
- این کار رو سریع انجام بده،
- و کاملاً جدا از بقیهی تستها (In Isolation) اجرا بشه.
۶.۴.۲ استفاده از ماکها برای جداسازی تستها از سیستم فایل
راهحل معمول برای مشکل تستهایی که بیش از حد به هم چسبیدهان (Tightly Coupled Tests) اینه که فایلسیستم رو ماک (Mock) کنی. میتونی تمام عملیات مربوط به فایلها رو داخل یک کلاس جداگانه (مثلاً IFileSystem) قرار بدی و این کلاس رو از طریق سازنده به AuditManager تزریق کنی. تستها هم همین کلاس رو ماک میکنن و تمام عملیات نوشتنیای که سیستم ممیزی روی فایلها انجام میده رو ثبت و بررسی میکنن (شکل ۶.۱۳).
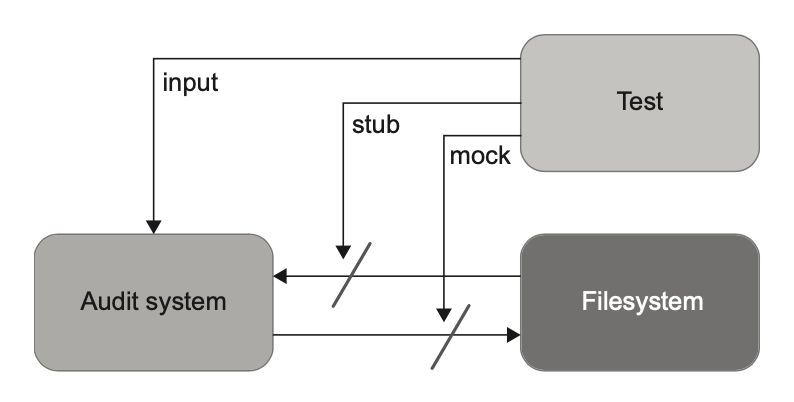
کد زیر نشون میده که چگونه فایل سیستم به AuditManager تزریق میشه:
public class AuditManager
{
private readonly int _maxEntriesPerFile;
private readonly string _directoryName;
private readonly IFileSystem _fileSystem;
public AuditManager(
int maxEntriesPerFile,
string directoryName,
IFileSystem fileSystem) // The new interface represents the filesystem.
{
_maxEntriesPerFile = maxEntriesPerFile;
_directoryName = directoryName;
_fileSystem = fileSystem;
}
}کد ۶.۹
و متد AddRecord به این شکل اصلاح میشه.
public void AddRecord(string visitorName, DateTime timeOfVisit)
{
string[] filePaths = _fileSystem.GetFiles(_directoryName);
(int index, string path)[] sorted = SortByIndex(filePaths);
string newRecord = visitorName + ";" + timeOfVisit;
if (sorted.Length == 0)
{
string newFile = Path.Combine(_directoryName, "audit_1.txt");
_fileSystem.WriteAllText(newFile, newRecord);
return;
}
(int currentFileIndex, string currentFilePath) = sorted.Last();
List<string> lines = _fileSystem.ReadAllLines(currentFilePath).ToList();
if (lines.Count < _maxEntriesPerFile)
{
lines.Add(newRecord);
string newContent = string.Join("\r\n", lines);
_fileSystem.WriteAllText(currentFilePath, newContent);
}
else
{
int newIndex = currentFileIndex + 1;
string newName = $"audit_{newIndex}.txt";
string newFile = Path.Combine(_directoryName, newName);
_fileSystem.WriteAllText(newFile, newRecord);
}
}کد ۶.۱۰
در کد ۶.۱۰، IFileSystem یک اینترفیس سفارشی جدیده که کار با فایل سیستم رو کپسوله میکنه:
public interface IFileSystem
{
string[] GetFiles(string directoryName);
void WriteAllText(string filePath, string content);
List<string> ReadAllLines(string filePath);
}حالا که AuditManager از فایل سیستم جدا شده، وابستگی مشترک از بین رفته و تستها میتونن مستقل از یکدیگه اجرا بشن. در ادامه نمونهای از چنین تستی آورده شده.
[Fact]
public void A_new_file_is_created_when_the_current_file_overflows()
{
var fileSystemMock = new Mock<IFileSystem>();
fileSystemMock
.Setup(x => x.GetFiles("audits"))
.Returns(new string[]
{
@"audits\audit_1.txt",
@"audits\audit_2.txt"
});
fileSystemMock
.Setup(x => x.ReadAllLines(@"audits\audit_2.txt"))
.Returns(new List<string>
{
"Peter; 2019-04-06T16:30:00",
"Jane; 2019-04-06T16:40:00",
"Jack; 2019-04-06T17:00:00"
});
var sut = new AuditManager(3, "audits", fileSystemMock.Object);
sut.AddRecord("Alice", DateTime.Parse("2019-04-06T18:00:00"));
fileSystemMock.Verify(x => x.WriteAllText(
@"audits\audit_3.txt",
"Alice;2019-04-06T18:00:00"));
}کد ۶.۱۱
این تست بررسی میکنه که وقتی تعداد رکوردهای داخل فایل فعلی به حد مجاز میرسه (توی این مثال، عدد ۳)، یک فایل جدید ساخته بشه و فقط یک رکورد ممیزی داخلش قرار بگیره. نکتهی مهم اینه که اینجا استفاده از ماکها (Mocks) کاملاً درست و منطقیه. برنامه داره فایلهایی تولید میکنه که برای کاربر نهایی قابل مشاهدهست (فرض میکنیم کاربر با یک برنامهی دیگه—چه نرمافزار تخصصی، چه حتی یک notepad.exe ساده—این فایلها رو میخونه). پس ارتباط برنامه با فایلسیستم (Filesystem) و اثرهای جانبی این ارتباط (یعنی تغییراتی که روی فایلها ایجاد میشه) جزو رفتار قابل مشاهدهی برنامه (Observable Behavior) محسوب میشن. همونطور که از فصل ۵ یادت هست، این تنها موردیه که استفاده از ماکها واقعاً درست محسوب میشه.
این پیادهسازیِ جایگزین نسبت به نسخهی اولیه یک پیشرفت حساب میشه. چون تستها دیگه مستقیم سراغ فایلسیستم نمیرن، سرعت اجرای تستها بالاتر میره. از طرف دیگه، چون لازم نیست برای خوشحال نگه داشتن تستها مدام مراقب فایلسیستم باشی، هزینهی نگهداری (Maintenance Cost) هم پایینتر میاد. در عین حال، محافظت در برابر بازگشت خطاها (Regression Protection) و مقاومت در برابر بازآرایی (Refactoring Resistance) هم هیچ آسیبی ندیده. جدول ۶.۳ تفاوتهای بین این دو نسخه رو نشون میده.
| معیار | نسخه اولیه | با ماک |
|---|---|---|
| محافظت در برابر بازگشت خطاها | خوب | خوب |
| مقاومت در برابر بازآرایی | خوب | خوب |
| بازخورد سریع | بد | خوب |
| نگهداریپذیری | بد | متوسط |
با این حال، هنوز میتونیم بهترش کنیم. تستی که توی کد ۶.۱۱ هست، راهاندازیهای پیچیده داره، و این از نظر هزینهی نگهداری (Maintenance Cost) اصلاً ایدهآل نیست. کتابخانههای ماکینگ (Mocking Libraries) هر کاری از دستشون برمیاد انجام میدن تا کار رو راحتتر کنن، اما خروجی نهایی همچنان به اندازهی تستهایی که فقط روی ورودی و خروجی ساده (Plain Input/Output) تکیه میکنن، خوانا و قابل فهم نیست.
۶.۴.۳ بازآرایی به سوی معماری تابعی
بهجای اینکه اثرهای جانبی (Side Effects) رو پشت یک اینترفیس قایم کنی و اون اینترفیس رو به AuditManager تزریق کنی، میتونی این اثرهای جانبی رو کلاً از داخل کلاس بیرون ببری. در این حالت، AuditManager فقط یک کار انجام میده: اینکه تصمیم بگیره با فایلها چه اتفاقی باید بیفته. بعد یک کلاس جدید به اسم Persister وارد میشه که بر اساس اون تصمیم عمل میکنه و تغییرات لازم رو روی فایلسیستم (Filesystem) اعمال میکنه (شکل ۶.۱۴).
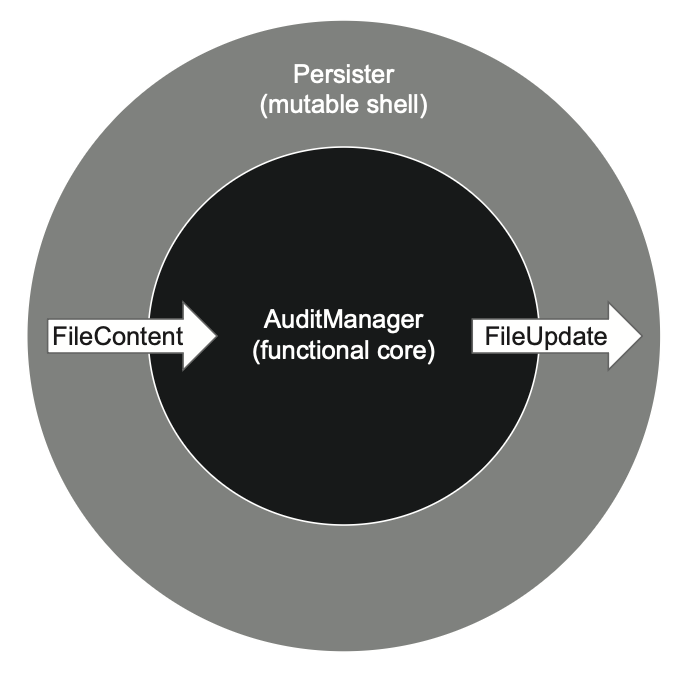
Persister و AuditManager معماری تابعی را شکل میدهند. Persister فایلها و محتوای آنها را از پوشهی کاری جمعآوری میکند، آنها را به AuditManager میدهد، و سپس مقدار بازگشتی را به تغییرات در سیستم فایل تبدیل میکند.در این سناریو، Persister نقش پوستهی قابل تغییر (Mutable Shell) رو بازی میکنه، و AuditManager تبدیل میشه به هستهی تابعی و غیرقابل تغییر (Functional / Immutable Core). کد بعدی نسخهی AuditManager رو بعد از بازآرایی (Refactoring) نشون میده.
public class AuditManager
{
private readonly int _maxEntriesPerFile;
public AuditManager(int maxEntriesPerFile)
{
_maxEntriesPerFile = maxEntriesPerFile;
}
public FileUpdate AddRecord(
FileContent[] files,
string visitorName,
DateTime timeOfVisit)
{
(int index, FileContent file)[] sorted = SortByIndex(files);
string newRecord = visitorName + ";" + timeOfVisit;
if (sorted.Length == 0)
{
// Returns an update instruction
return new FileUpdate("audit_1.txt", newRecord);
}
(int currentFileIndex, FileContent currentFile) = sorted.Last();
List<string> lines = currentFile.Lines.ToList();
if (lines.Count < _maxEntriesPerFile)
{
lines.Add(newRecord);
string newContent = string.Join("\r\n", lines);
// Returns an update instruction
return new FileUpdate(currentFile.FileName, newContent);
}
else
{
int newIndex = currentFileIndex + 1;
string newName = $"audit_{newIndex}.txt";
// Returns an update instruction
return new FileUpdate(newName, newRecord);
}
}
}کد ۶.۱۲
بهجای اینکه مسیر پوشهی کاری (Working Directory Path) رو بگیره، AuditManager حالا یک آرایه از FileContent دریافت میکنه. این کلاس (FileContent) تمام چیزهایی رو که AuditManager برای تصمیمگیری دربارهی وضعیت فایلسیستم (Filesystem) لازم داره، در خودش نگه میداره:
public class FileContent
{
public readonly string FileName;
public readonly string[] Lines;
public FileContent(string fileName, string[] lines)
{
FileName = fileName;
Lines = lines;
}
}و حالا، بهجای اینکه خودش فایلها رو داخل پوشهی کاری تغییر بده، AuditManager فقط یک دستور (Instruction) برمیگردونه؛ یعنی میگه چه اثر جانبی (Side Effect) باید انجام بشه.
public class FileUpdate
{
public readonly string FileName;
public readonly string NewContent;
public FileUpdate(string fileName, string newContent)
{
FileName = fileName;
NewContent = newContent;
}
}کد بعدی کلاس Persister رو نشون میده.
public class Persister
{
public FileContent[] ReadDirectory(string directoryName)
{
return Directory
.GetFiles(directoryName)
.Select(x => new FileContent(
Path.GetFileName(x),
File.ReadAllLines(x)))
.ToArray();
}
public void ApplyUpdate(string directoryName, FileUpdate update)
{
string filePath = Path.Combine(directoryName, update.FileName);
File.WriteAllText(filePath, update.NewContent);
}
}کد ۶.۱۳
ببین چقدر این کلاس سادهست. تنها کاری که میکنه اینه که محتوای پوشهی کاری (Working Directory) رو میخونه و آپدیتهایی رو که از AuditManager میگیره، دوباره روی همون پوشه اعمال میکنه. هیچ شاخهبندیای هم نداره (هیچ ifای در کار نیست). تمام پیچیدگیها داخل خود AuditManager قرار گرفتن. این دقیقاً همون جداسازی بین منطق تجاری (Business Logic) و اثرهای جانبی (Side Effects) در عمله.
برای اینکه این جداسازی حفظ بشه، باید رابطهای FileContent و FileUpdate تا حد ممکن شبیه دستورهای داخلی خود فریمورک برای کار با فایلها باشن. تمام کارهای مربوط به پردازش و آمادهسازی باید داخل هستهی تابعی (Functional Core) انجام بشه، تا کدی که بیرون از اون هسته قرار میگیره، همینطور ساده و پیشپاافتاده باقی بمونه.
مثلاً فرض کن .NET متد File.ReadAllLines رو نداشت— که محتویات فایل رو بهصورت آرایهای از خطوط برمیگردونه— و فقط File.ReadAllText وجود داشت که کل فایل رو به شکل یک رشتهی تکی برمیگردونه. در این حالت، مجبور بودی ویژگی Lines در FileContent رو هم تبدیل به یک رشته کنی و عملیات تبدیل رو داخل AuditManager انجام بدی.
public class FileContent
{
public readonly string FileName;
public readonly string Text; // قبلاً string[] Lines;
}برای اینکه AuditManager و Persister به هم وصل بشن و با هم کار کنن، به یک کلاس دیگه نیاز داری—چیزی که در دستهبندی معماری ششضلعی (Hexagonal Architecture) بهش میگن سرویس کاربردی (Application Service). کد بعدی همین کلاس رو نشون میده.
public class ApplicationService
{
private readonly string _directoryName;
private readonly AuditManager _auditManager;
private readonly Persister _persister;
public ApplicationService(string directoryName, int maxEntriesPerFile)
{
_directoryName = directoryName;
_auditManager = new AuditManager(maxEntriesPerFile);
_persister = new Persister();
}
public void AddRecord(string visitorName, DateTime timeOfVisit)
{
FileContent[] files = _persister.ReadDirectory(_directoryName);
FileUpdate update = _auditManager.AddRecord(
files, visitorName, timeOfVisit);
_persister.ApplyUpdate(_directoryName, update);
}
}کد ۶.۱۴
علاوه بر اینکه هستهی تابعی (Functional Core) رو به پوستهی قابل تغییر (Mutable Shell) وصل میکنه، سرویس کاربردی (Application Service) یک نقطهی ورود (Entry Point) هم برای کل سیستم فراهم میکنه تا کلاینتهای بیرونی بتونن با سیستم کار کنن (شکل ۶.۱۵). با این پیادهسازی، بررسی رفتار سیستم ممیزی خیلی راحت میشه. تمام تستها در نهایت خلاصه میشن به اینکه یک وضعیت فرضی از پوشهی کاری (Working Directory) به سیستم بدی و بعد بررسی کنی AuditManager چه تصمیمی میگیره.
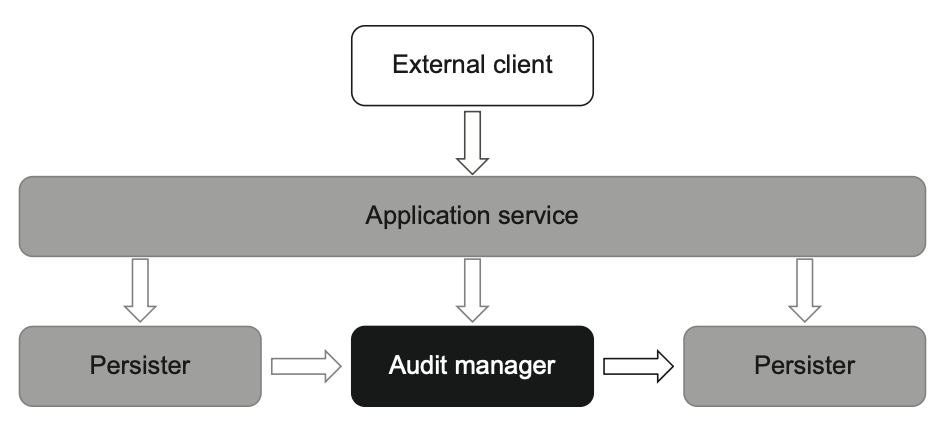
ApplicationService هستهی تابعی (AuditManager) و پوستهی قابل تغییر (Persister) را به هم متصل میکند و یک نقطهی ورود برای کلاینتهای خارجی فراهم میسازد. در ردهبندی معماری ششضلعی، ApplicationService و Persister بخشی از لایهی سرویسهای کاربردی هستند، در حالی که AuditManager متعلق به مدل دامنه است.[Fact]
public void A_new_file_is_created_when_the_current_file_overflows()
{
var sut = new AuditManager(3);
var files = new FileContent[]
{
new FileContent("audit_1.txt", new string[0]),
new FileContent("audit_2.txt", new string[]
{
"Peter; 2019-04-06T16:30:00",
"Jane; 2019-04-06T16:40:00",
"Jack; 2019-04-06T17:00:00"
})
};
FileUpdate update = sut.AddRecord(
files, "Alice", DateTime.Parse("2019-04-06T18:00:00"));
Assert.Equal("audit_3.txt", update.FileName);
Assert.Equal("Alice;2019-04-06T18:00:00", update.NewContent);
}کد ۶.۱۵
این تست، بهبودی رو که تستِ مبتنی بر ماکها نسبت به نسخهی اولیه ایجاد کرده بود (یعنی بازخورد سریع) حفظ میکنه، اما از نظر نگهداری (Maintainability) حتی یک قدم جلوتر هم میره. دیگه نیازی به اون راهاندازیهای پیچیدهی ماکها نیست؛ فقط ورودی و خروجی ساده داریم، و همین باعث میشه تستها خیلی خواناتر بشن. جدول ۶.۴ هم تستِ مبتنی بر خروجی (Output‑based Test) رو با نسخهی اولیه و نسخهی مبتنی بر ماکها مقایسه میکنه.
| معیار | نسخه اولیه | نسخه با ماکها | نسخه مبتنی بر خروجی |
|---|---|---|---|
| محافظت در برابر بازگشت خطاها | خوب | خوب | خوب |
| مقاومت در برابر بازآرایی | خوب | خوب | خوب |
| بازخورد سریع | بد | خوب | خوب |
| نگهداریپذیری | بد | متوسط | خوب |
دقت کن که دستورهایی که هستهی تابعی (Functional Core) تولید میکنه، همیشه یک مقدار (Value) یا یک مجموعهای از مقادیر هستن. دو نمونه از چنین مقداری، تا وقتی که محتوای یکسانی داشته باشن، قابلجایگزینی هستن. میتونی از همین ویژگی استفاده کنی و خوانایی تستها رو حتی بیشتر هم بهبود بدی؛ چطور؟ با تبدیل کردن FileUpdate به یک Value Object.
برای انجام این کار در .NET، باید یا:
- کلاس رو تبدیل به struct کنی،
- یا اعضای برابری سفارشی (Custom Equality Members) تعریف کنی.
این کار باعث میشه مقایسهها بر اساس مقدار (Comparison by Value) انجام بشن، نه بر اساس مرجع (Comparison by Reference) که رفتار پیشفرض کلاسها در C# هست. مقایسهی مبتنی بر مقدار همچنین بهت اجازه میده اون دو تا Assertion موجود در کد ۶.۱۵ رو به یک Assertion خلاصه کنی.
Assert.Equal(
new FileUpdate("audit_3.txt", "Alice;2019-04-06T18:00:00"),
update);یا با استفاده از Fluent Assertions:
update.Should().Be(
new FileUpdate("audit_3.txt", "Alice;2019-04-06T18:00:00"));۶.۴.۴ نگاهی به توسعههای بیشتر
بیاییم یک قدم عقبتر بریم و نگاهی بندازیم به توسعههای بیشتری که میشه روی پروژهی نمونه انجام داد. سیستم ممیزیای که تا اینجا دیدی، واقعاً سادهست و فقط سه شاخهی رفتاری داره:
- ساختن یک فایل جدید وقتی پوشهی کاری (Working Directory) خالیه
- اضافه کردن یک رکورد جدید به یک فایل موجود
- ساختن یک فایل جدید وقتی تعداد رکوردهای فایل فعلی از حد مجاز عبور میکنه
علاوه بر این، فقط یک مورد استفاده (Use Case) وجود داره: اضافه کردن یک ورودی جدید به لاگ ممیزی. حالا فرض کن یک مورد استفادهی دیگه هم وجود داشته باشه—مثلاً حذف تمام اشارهها به یک بازدیدکنندهی خاص. یا فرض کن سیستم نیاز داشته باشه اعتبارسنجی (Validation) انجام بده (مثلاً محدودیت روی حداکثر طول نام بازدیدکننده).
حذف تمام اشارهها به یک بازدیدکنندهی خاص ممکنه روی چندین فایل اثر بذاره، پس متد جدید باید چندین دستور فایل (File Instructions) برگردونه:
public FileUpdate[] DeleteAllMentions(FileContent[] files, string visitorName)علاوه بر این، ممکنه افراد کسبوکار ازت بخوان که فایلهای خالی رو داخل پوشهی کاری (Working Directory) نگه نداری. اگر ورودی حذفشده آخرین ورودی یک فایل ممیزی باشه، باید اون فایل رو کلاً حذف کنی. برای پیادهسازی این نیازمندی، میتونی نام FileUpdate رو به FileAction تغییر بدی و یک فیلد جدید از نوع ActionType enum اضافه کنی تا مشخص کنه این عمل یک بهروزرسانی (Update) بوده یا حذف (Deletion).
مدیریت خطا (Error Handling) هم با معماری تابعی (Functional Architecture) سادهتر و شفافتر میشه. میتونی خطاها رو داخل امضای متد (Method Signature) قرار بدی— یا داخل خود کلاس FileUpdate، یا بهعنوان یک مؤلفهی جداگانه:
public (FileUpdate update, Error error) AddRecord(
FileContent[] files,
string visitorName,
DateTime timeOfVisit)سرویس کاربردی (Application Service) در این حالت خطا رو بررسی میکنه. اگر خطا وجود داشته باشه، سرویس دیگه دستور بهروزرسانی رو به Persister ارسال نمیکنه؛ در عوض، پیام خطا رو به کاربر منتقل میکنه.
۶.۵ درک معایب معماری تابعی
متأسفانه، معماری تابعی (Functional Architecture) همیشه قابل دستیابی نیست. و حتی وقتی هم که قابل اجرا باشه، مزایای نگهداریپذیری (Maintainability Benefits) گاهی با کاهش کارایی (Performance Impact) و افزایش حجم کد خنثی میشن. در این بخش، میخوایم هزینهها و مصالحهها (Trade‑offs) مرتبط با معماری تابعی رو بررسی کنیم.
۶.۵.۱ کاربرد معماری تابعی
معماری تابعی برای سیستم ممیزی ما جواب داد، چون این سیستم میتونست همهی ورودیها رو از قبل جمعآوری کنه و بعد تصمیم بگیره. اما در بسیاری از سیستمها، جریان اجرا (Execution Flow) اینقدر سرراست نیست. گاهی لازم میشه بر اساس یک نتیجهی میانی در فرآیند تصمیمگیری، اطلاعات بیشتری رو از یک وابستگی خارج از فرآیند (Out‑of‑Process Dependency) —مثلاً یک سرویس خارجی یا یک پایگاه داده— استعلام بگیری.
مثال: فرض کن سیستم ممیزی باید سطح دسترسی بازدیدکننده (Access Level) رو بررسی کنه اگر تعداد دفعاتی که در ۲۴ ساعت گذشته وارد شده، از یک حد مشخص بیشتر بشه. و فرض کنیم که سطح دسترسی همهی بازدیدکنندهها داخل یک پایگاه داده (Database) ذخیره شده.
در این حالت، نمیتونی یک نمونه از IDatabase رو اینطوری به AuditManager پاس بدی:
public FileUpdate AddRecord(
FileContent[] files, string visitorName,
DateTime timeOfVisit, IDatabase database
)چنین نمونهای یک ورودی پنهان به متد AddRecord وارد میکنه. در نتیجه، این متد دیگه یک تابع ریاضی (Mathematical Function) نخواهد بود (شکل ۶.۱۶)، و این یعنی دیگه نمیتونی از تست مبتنی بر خروجی (Output‑based Testing) استفاده کنی.
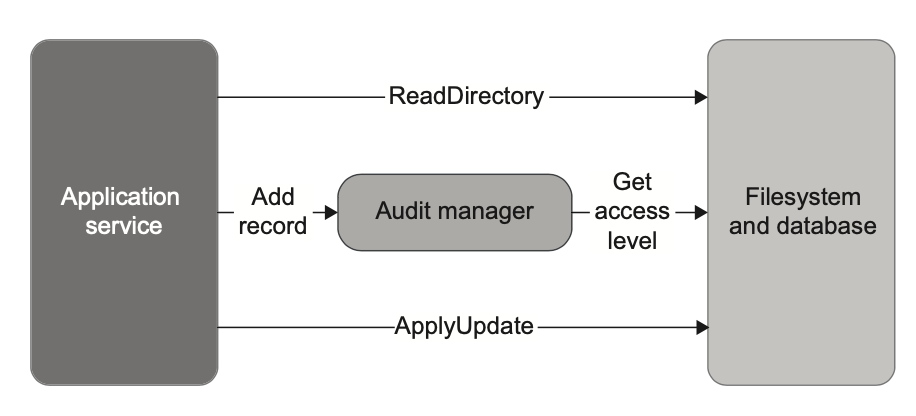
AuditManager میکنه. وقتی این اتفاق رخ بده، دیگه این کلاس کاملاً تابعی (purely functional) نیست و کل برنامه هم از معماری تابعی خارج میشه.در چنین وضعیتی دو راهحل وجود داره:
- میتونی سطح دسترسی بازدیدکننده (Access Level) رو از قبل، همراه با محتوای پوشهی کاری، داخل سرویس کاربردی (Application Service) جمعآوری کنی.
- میتونی یک متد جدید مثل IsAccessLevelCheckRequired داخل AuditManager معرفی کنی. سرویس کاربردی قبل از فراخوانی AddRecord این متد رو صدا میزنه، و اگر نتیجهی اون true بود، سرویس سطح دسترسی رو از پایگاه داده میگیره و به AddRecord پاس میده.
هر دو رویکرد نقطهضعف دارن. رویکرد اول از نظر کارایی (Performance) امتیاز از دست میده— چون بدون قید و شرط از پایگاه داده کوئری میگیره، حتی وقتی که اصلاً نیازی به سطح دسترسی نیست. اما این رویکرد جداسازی بین منطق تجاری (Business Logic) و ارتباط با سیستمهای خارجی (External Systems) رو کاملاً حفظ میکنه؛ تمام تصمیمگیریها همچنان داخل AuditManager باقی میمونه.
رویکرد دوم بخشی از این جداسازی رو فدای بهبود کارایی میکنه: تصمیم اینکه آیا باید پایگاه داده صدا زده بشه یا نه، دیگه داخل Application Service گرفته میشه، نه داخل AuditManager.
نکتهی مهم: برخلاف این دو گزینه، اینکه مدل دامنه (Domain Model)—یعنی AuditManager— به پایگاه داده وابسته بشه، ایدهی خوبی نیست. در دو فصل بعدی بیشتر دربارهی حفظ تعادل بین کارایی و تفکیک مسئولیتها (Separation of Concerns) توضیح میدم.
همکارها (Collaborators) در برابر مقادیر (Values)
ممکنه متوجه شده باشی که متد AddRecord در AuditManager یک وابستگی داره که داخل امضای متد دیده نمیشه: فیلد maxEntriesPerFile. مدیر ممیزی برای اینکه تصمیم بگیره رکورد جدید رو به فایل موجود اضافه کنه یا یک فایل جدید بسازه، به همین فیلد رجوع میکنه.
با اینکه این وابستگی بین آرگومانهای متد وجود نداره، پنهان هم نیست. چون میشه اون رو از امضای سازندهی کلاس (Constructor Signature) فهمید. و از اونجا که فیلد maxEntriesPerFile غیرقابلتغییر (Immutable) هست، بین زمان ساخت شیء و فراخوانی AddRecord هیچ تغییری نمیکنه. به عبارت دیگه، این فیلد یک مقدار (Value) محسوب میشه.
اما وضعیت وابستگی IDatabase فرق میکنه، چون این یکی یک همکار (Collaborator) هست، نه یک مقدار مثل maxEntriesPerFile.
همونطور که از فصل ۲ یادت هست، یک همکار وابستگیایه که یکی از این دو ویژگی رو داره:
- قابلتغییر (Mutable) باشه
- یا پروکسیای برای دادهای باشه که هنوز داخل حافظه نیست (یعنی یک وابستگی مشترک و خارج از فرآیند)
نمونهی IDDatabase داخل دستهی دوم قرار میگیره، و بنابراین یک Collaborator محسوب میشه. چون برای کار کردن نیاز به یک فراخوانی اضافه به یک وابستگی خارج از فرآیند داره، و همین باعث میشه نتونی از تست مبتنی بر خروجی (Output‑based Testing) استفاده کنی.
نکته: کلاسی که داخل هستهی تابعی (Functional Core) قرار داره نباید با یک Collaborator کار کنه، بلکه باید با محصول کار اون Collaborator کار کنه—یعنی با یک مقدار (Value).
۶.۵.۲ معایب مربوط به کارایی
تأثیر عملکردی (Performance Impact) روی کل سیستم یکی از رایجترین استدلالها علیه معماری تابعی (Functional Architecture) هست. دقت کن که این کاهش عملکرد مربوط به تستها نیست. تستهای مبتنی بر خروجی (Output‑based Tests) که در نهایت بهشون رسیدیم، به همون سرعت تستهای مبتنی بر ماکها اجرا میشن.
مشکل اینجاست که خود سیستم حالا باید فراخوانیهای بیشتری به وابستگیهای خارج از فرآیند (Out‑of‑Process Dependencies) انجام بده و همین باعث کاهش کارایی میشه. نسخهی اولیهی سیستم ممیزی همهی فایلهای پوشهی کاری رو نمیخوند، نسخهی مبتنی بر ماکها هم همینطور. اما نسخهی نهایی این کار رو انجام میده تا با الگوی خواندن–تصمیمگیری–اقدام (Read–Decide–Act) سازگار باشه.
انتخاب بین معماری تابعی و یک معماری سنتیتر، در واقع یک مصالحه (Trade‑off) بین کارایی (Performance) و نگهداریپذیری کد (Code Maintainability) هست (چه کد تولیدی، چه کد تست). در بعضی سیستمها که تأثیر عملکردی چندان محسوس نیست، بهتره از معماری تابعی استفاده کنی تا مزایای بیشتری در نگهداریپذیری به دست بیاری. در سیستمهای دیگه، ممکنه مجبور بشی انتخاب برعکس انجام بدی. هیچ راهحل واحد و همگانیای وجود نداره.
۶.۵.۳ افزایش اندازهی کدبیس
همین موضوع دربارهی حجم کد (Codebase Size) هم صدق میکنه. معماری تابعی (Functional Architecture) نیازمند یک جداسازی شفاف بین هستهی تابعی و غیرقابلتغییر (Immutable Core) و پوستهی قابلتغییر (Mutable Shell) هست. این کار در ابتدا کدنویسی بیشتری میطلبه، اما در نهایت باعث کاهش پیچیدگی کد و بهبود نگهداریپذیری (Maintainability) میشه.
البته همهی پروژهها آنقدر پیچیدگی ندارن که چنین سرمایهگذاری اولیهای رو توجیه کنن. بعضی کدبیسها از نظر کسبوکار اهمیت چندانی ندارن، یا صرفاً خیلی ساده هستن. در چنین پروژههایی استفاده از معماری تابعی منطقی نیست، چون این سرمایهگذاری هیچوقت بازدهی نخواهد داشت. همیشه معماری تابعی رو استراتژیک بهکار ببر— با توجه به پیچیدگی و اهمیت سیستم.
در نهایت، دنبال پاکی مطلق (Purity) در رویکرد تابعی نباش اگر این پاکی هزینهی زیادی برات ایجاد میکنه. در بیشتر پروژهها نمیتونی مدل دامنه (Domain Model) رو کاملاً غیرقابلتغییر کنی، و بنابراین نمیتونی فقط به تستهای مبتنی بر خروجی (Output‑based Tests) تکیه کنی— بهخصوص وقتی از زبانهای شیءگرا مثل C# یا Java استفاده میکنی.
در اغلب موارد، ترکیبی از اینها خواهی داشت:
- تستهای مبتنی بر خروجی (Output‑based)
- تستهای مبتنی بر وضعیت (State‑based)
- و مقدار کمی تست مبتنی بر ارتباط (Communication‑based)
و این کاملاً طبیعیه. هدف این فصل این نیست که همهی تستهات رو مجبور کنه به سبک مبتنی بر خروجی منتقل کنی؛ هدف اینه که تا جایی که منطقی و ممکنه این کار رو انجام بدی. این تفاوت ظریفه—اما خیلی مهم.
خلاصه
- تست خروجیمحور (Output-based): توی این سبک تست، یه ورودی به سیستم تحت تست (SUT) میدی و خروجیای که تولید میکنه رو بررسی میکنی. فرض این روش اینه که هیچ ورودی یا خروجی پنهونی وجود نداره و تنها نتیجهی کار سیستم همون مقداریه که برمیگردونه.
- تست حالتمحور (State-based): وضعیت سیستم رو بعد از اجرای عملیات بررسی میکنی.
- تست ارتباطمحور (Communication-based): با ماکها ارتباط بین سیستم تحت تست و همکارهاش رو بررسی میکنی.
- مکتب کلاسیکِ تست واحد بیشتر طرفدار تست حالتمحوره، در حالی که مدرسهی لندن بیشتر تست ارتباطمحور رو ترجیح میده. هر دو مدرسه از تست خروجیمحور هم استفاده میکنن.
- تست خروجیمحور معمولاً باکیفیتترین تستها رو تولید میکنه. این تستها به جزئیات پیادهسازی وابسته نیستن، در برابر بازآرایی مقاومن، و چون کوچیک و جمعوجورن، نگهداریشون راحتتره.
- تست حالتمحور نیاز به دقت بیشتری داره تا شکننده نشه؛ باید مطمئن باشی حالت خصوصی رو برای تست کردن لو نمیدی. این تستها معمولاً بزرگتر از تستهای خروجیمحورن، پس نگهداریشون سختتره. میشه با کمک متدهای کمکی یا آبجکتهای مقداری کمی این مشکل رو کم کرد، ولی کامل حل نمیشه.
- تست ارتباطمحور هم همین مشکل شکنندگی رو داره. باید فقط ارتباطهایی رو بررسی کنی که از مرز اپلیکیشن رد میشن و اثرشون بیرون قابل مشاهدهست. نگهداری این تستها سختتر از دو سبک قبلیه، چون ماکها جا زیادی میگیرن و تست رو کمتر خوانا میکنن.
- برنامهنویسی تابعی یعنی برنامهنویسی با توابع ریاضی.
- یه تابع ریاضی تابعیه که هیچ ورودی یا خروجی پنهونی نداره. اثرات جانبی و استثناها خروجی پنهون حساب میشن، و ارجاع به وضعیت داخلی یا خارجی هم ورودی پنهونه. توابع ریاضی شفافن و همین باعث میشه خیلی راحت تست بشن.
- هدف برنامهنویسی تابعی اینه که منطق تجاری رو از اثرات جانبی جدا کنه.
- معماری تابعی این جداسازی رو با هل دادن اثرات جانبی به لبههای عملیات تجاری انجام میده. این رویکرد باعث میشه بیشترین بخش کد به شکل تابعی خالص نوشته بشه و کمترین بخش با اثرات جانبی سروکار داشته باشه.
- معماری تابعی همهی کد رو به دو بخش تقسیم میکنه: هستهی تابعی و پوستهی قابل تغییر. هسته تصمیم میگیره، پوسته دادهی ورودی رو به هسته میده و تصمیمهای هسته رو به اثرات جانبی تبدیل میکنه.
- تفاوت معماری تابعی با معماری ششضلعی (Hexagonal) توی برخورد با اثرات جانبیه. معماری تابعی همهی اثرات جانبی رو از لایهی دامنه بیرون میکشه، ولی معماری ششضلعی مشکلی نداره که دامنه اثر جانبی داشته باشه، به شرطی که محدود به همون لایه باشه. در واقع معماری تابعی یه جور معماری ششضلعیِ افراطی محسوب میشه.
- انتخاب بین معماری تابعی و معماری سنتی یه معاملهست بین کارایی و نگهداریپذیری. معماری تابعی کمی از کارایی رو قربانی میکنه تا نگهداری بهتر بشه.
- همهی کدبیسها ارزش تبدیل شدن به معماری تابعی رو ندارن. باید این معماری رو هوشمندانه و با توجه به پیچیدگی و اهمیت سیستم انتخاب کنی. توی پروژههای ساده یا کماهمیت، هزینهی اولیهی معماری تابعی هیچوقت جبران نمیشه.