
این فصل شامل موارد زیر است:
- تمایز بین ماکها (mocks) و استابها (stubs)
- تعریف رفتار قابل مشاهده و جزئیات پیادهسازی
- درک رابطهی بین ماکها و شکنندگی تست
- استفاده از ماکها بدون به خطر انداختن مقاومت در برابر بازآرایی
فصل ۴ چارچوبی معرفی کرد که میتونی برای تحلیل تستهای مشخص و رویکردهای تست واحد ازش استفاده کنی. در این فصل، اون چارچوب رو در عمل خواهیم دید؛ موضوع ماکها رو با همین چارچوب بررسی میکنیم.
استفاده از ماکها در تست موضوعی بحثبرانگیزه. بعضیها معتقدن ماکها ابزار خیلی خوبی هستن و در بیشتر تستها ازشون استفاده میکنن. بعضی دیگه میگن ماکها باعث شکنندگی تست میشن و سعی میکنن اصلاً ازشون استفاده نکنن. اما حقیقت جایی بین این دو دیدگاه قرار داره. در این فصل نشون داده میشه که واقعاً ماکها اغلب منجر به تستهای شکننده میشن—تستهایی که معیار مقاومت در برابر بازآرایی رو ندارن. اما همچنان مواردی وجود دارن که استفاده از ماکها هم کاربردی و حتی ترجیحی هست.
این فصل بهشدت بر بحث مربوط به مکتب لندن در برابر مکتب کلاسیکِ تست واحد در فصل ۲ تکیه میکنه. بهطور خلاصه، اختلاف بین این دو مکتب ناشی از دیدگاه اونها نسبت به موضوع جداسازی تست هست.
- مکتب لندن طرفدار جداسازی بخشهای کد تحت تست از یکدیگره و برای این جداسازی از تستدابلها(test double) استفاده میکنه، بهجز در مورد وابستگیهای تغییرناپذیر.
- مکتب کلاسیک بر جداسازی خود تستهای واحد تأکید داره تا بتونن بهصورت موازی اجرا بشن. این مکتب فقط برای وابستگیهایی که بین تستها مشترک هستن از تستدابلها استفاده میکنه.
ارتباطی عمیق و تقریباً اجتنابناپذیر بین ماکها و شکنندگی تست وجود داره. در بخشهای بعدی، بهتدریج پایههای لازم رو برای درک دلیل این ارتباط توضیح میدم. همچنین یاد میگیری که چطور از ماکها استفاده کنی بدون اینکه مقاومت تست در برابر بازآرایی به خطر بیفته.
۵.۱ تمایز بین ماکها و استابها
در فصل ۲ بهطور مختصر اشاره شد که ماک یک تستدابل هست که امکان بررسی تعاملات بین سیستم تحت تست (SUT) و همکارانش رو فراهم میکنه. نوع دیگهای از تستدابل وجود داره: استاب (stub). حالا دقیقتر نگاه میکنیم که ماک چی هست و چه تفاوتی با استاب داره.
۵.۱.۱ انواع تستدابلها
تستدابل اصطلاحی کلیه که همهی انواع وابستگیهای جعلی در تستها رو توصیف میکنه. این اصطلاح از مفهوم بدلکار در فیلم گرفته شده. استفادهی اصلی تستدابلها تسهیل تست کردنه؛ اونها به جای وابستگیهای واقعی که ممکنه راهاندازی یا نگهداریشون سخت باشه استفاده میشن.
طبق گفتهی جرارد مزاروس، پنج نوع تستدابل وجود داره: Dummy، Stub، Spy، Mock و Fake.
این تنوع ممکنه در نگاه اول ترسناک به نظر برسه، اما در واقع همهی اونها رو میشه فقط در دو دستهی اصلی گروهبندی کرد: ماکها و استابها (شکل ۵.۱).
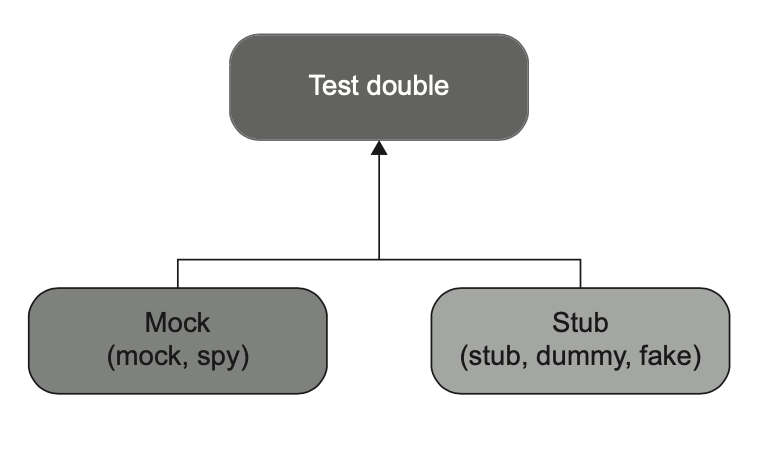
تفاوت بین این دو نوع در موارد زیر خلاصه میشه:
- ماکها به شبیهسازی و بررسی تعاملات خروجی کمک میکنن. این تعاملات همون فراخوانیهایی هستن که SUT به وابستگیهاش انجام میده تا وضعیت اونها رو تغییر بده.
- استابها به شبیهسازی تعاملات ورودی کمک میکنن. این تعاملات فراخوانیهایی هستن که SUT به وابستگیهاش انجام میده تا دادهی ورودی دریافت کنه (شکل ۵.۲).
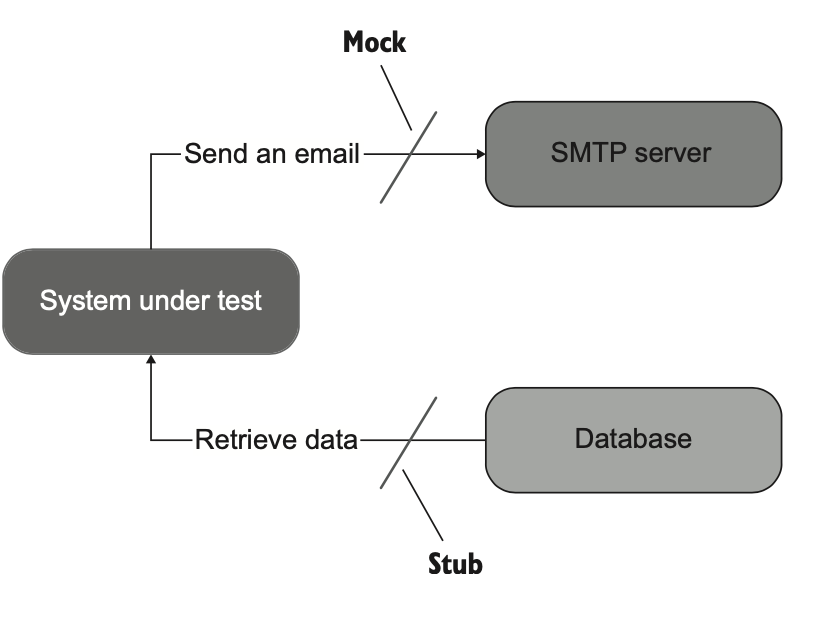
تمام تفاوتهای دیگه بین پنج نوع تستدابل ذکر شده در جزئیات پیادهسازی کماهمیت هستن. برای مثال، اسپایها همون نقش ماکها رو دارن. تفاوت اینه که اسپایها بهصورت دستی نوشته میشن، در حالی که ماکها با کمک یک فریمورک ماکینگ ساخته میشن. گاهی به اسپایها «ماکهای دستنویس» هم گفته میشه.
از طرف دیگه، تفاوت بین استاب، دامی و فیک در میزان هوشمندی اونهاست:
- دامی یک مقدار ساده و ثابت مثل
nullیا یک رشتهی ساختگیه. فقط برای پر کردن امضای متد SUT استفاده میشه و در نتیجهی نهایی نقشی نداره. - استاب پیشرفتهتره. یک وابستگی کامل محسوب میشه که میتونی اون رو طوری پیکربندی کنی که در سناریوهای مختلف مقادیر متفاوتی برگردونه.
- فیک از بیشتر جهات شبیه استابه. تفاوت در دلیل ایجادشه: فیک معمولاً برای جایگزینی یک وابستگی که هنوز وجود نداره پیادهسازی میشه.
به تفاوت بین ماکها و استابها توجه کن (علاوه بر تعاملات خروجی در برابر ورودی). ماکها به شبیهسازی و بررسی تعاملات بین SUT و وابستگیهاش کمک میکنن، در حالی که استابها فقط به شبیهسازی اون تعاملات کمک میکنن. این تفاوت مهمیه و بهزودی دلیلش رو خواهی دید.
۵.۱.۲ ماک (ابزار) در برابر ماک (تستدابل)
اصطلاح ماک بار معنایی زیادی داره و در شرایط مختلف میتونه معانی متفاوتی داشته باشه. در فصل ۲ اشاره شد که خیلیها این اصطلاح رو برای اشاره به هر نوع تستدابل به کار میبرن، در حالی که ماکها فقط یک زیرمجموعه از تستدابلها هستن.
اما معنای دیگهای هم برای واژهی ماک وجود داره: میتونی به کلاسهایی که از کتابخانههای ماکینگ ارائه میشن هم ماک بگی. این کلاسها بهت کمک میکنن ماکهای واقعی بسازی، اما خودشون ذاتاً ماک محسوب نمیشن.
در ادامه یک مثال برای روشنتر شدن این موضوع آورده شده.
[Fact]
public void Sending_a_greetings_email()
{
var mock = new Mock<IEmailGateway>(); // از ابزار ماک برای ایجاد ماک (تستدابل) استفاده شده
var sut = new Controller(mock.Object);
sut.GreetUser("user@email.com");
mock.Verify(
x => x.SendGreetingsEmail("user@email.com"),
Times.Once); // بررسی فراخوانی متد تستدابل توسط سیستم تحت تست
}کد ۵.۱
تست در کد ۵.۱ از کلاس Mock در کتابخانهی ماکینگ انتخابی من (Moq) استفاده میکنه. این کلاس یک ابزار محسوب میشه که بهت امکان ساختن یک تستدابل—یعنی ماک—رو میده. به عبارت دیگه، کلاس Mock (یا Mock<IEmailGateway>) یک ماک بهعنوان ابزاره، در حالی که نمونهی ساختهشده از اون کلاس (mock) یک ماک بهعنوان تستدابله.
نکتهی مهم اینه که نباید ماک (ابزار) رو با ماک (تستدابل) یکی بدونی، چون میتونی با استفاده از ماک (ابزار) هر دو نوع تستدابل رو بسازی: هم ماکها و هم استابها.
تست در کد بعدی هم از کلاس Mock استفاده میکنه، اما نمونهی ساختهشده از اون کلاس در این حالت یک استاب هست، نه ماک.
[Fact]
public void Creating_a_report()
{
var stub = new Mock<IDatabase>(); // استفاده از ابزار ماک برای ساخت استاب
stub.Setup(x => x.GetNumberOfUsers()) // تنظیم پاسخ از پیشتعریفشده
.Returns(10);
var sut = new Controller(stub.Object);
Report report = sut.CreateReport();
Assert.Equal(10, report.NumberOfUsers);
}کد ۵.۲
این تستدابل یک تعامل ورودی رو شبیهسازی میکنه—یعنی فراخوانیای که به SUT دادهی ورودی میده. در مقابل، در مثال قبلی (کد ۵.۱)، فراخوانی متد SendGreetingsEmail() یک تعامل خروجی بود. هدف اصلی اون ایجاد یک اثر جانبی بود—ارسال ایمیل.
۵.۱.۳ هیچوقت تعاملات با استابها رو بررسی (assert) نکن.
همونطور که در بخش ۵.۱.۱ گفته شد، ماکها برای شبیهسازی و بررسی تعاملات خروجی بین SUT و وابستگیهاش استفاده میشن، در حالی که استابها فقط تعاملات ورودی رو شبیهسازی میکنن اما بررسی نمیکنن. تفاوت اصلی بین این دو در همین راهنماست:
- فراخوانی SUT به یک استاب بخشی از نتیجهی نهایی تولیدشده توسط SUT نیست.
- این فراخوانی فقط وسیلهای برای تولید نتیجهی نهایی محسوب میشه: استاب دادهی ورودی رو فراهم میکنه و SUT خروجی رو بر اساس اون میسازه.
نکته: بررسی تعاملات با استابها یک آنتیپترن رایجه که منجر به تستهای شکننده میشه.
همونطور که از فصل ۴ یادت هست، تنها راه جلوگیری از false positiveها و افزایش مقاومت تستها در برابر بازآرایی اینه که تستها نتیجهی نهایی رو بررسی کنن، نه جزئیات پیادهسازی.
در کد ۵.۱، بررسی زیر:
mock.Verify(x => x.SendGreetingsEmail("user@email.com"))این بررسی در واقع به یک خروجی واقعی مربوط میشه، و اون خروجی برای یک متخصص دامنه معنادار هست: ارسال ایمیل خوشامد چیزیست که افراد کسبوکار انتظار دارن سیستم انجام بده.
در مقابل، فراخوانی متد GetNumberOfUsers() در کد ۵.۲ اصلاً یک خروجی محسوب نمیشه. این فقط یک جزئیات داخلی پیادهسازی دربارهی نحوهی جمعآوری داده توسط SUT برای ساخت گزارشه. بنابراین، بررسی این فراخوانی باعث شکنندگی تست میشه: نباید اهمیتی داشته باشه که SUT چطور نتیجهی نهایی رو تولید میکنه، تا زمانی که اون نتیجه درست باشه.
کد زیر نمونهای از چنین تست شکنندهای رو نشون میده.
[Fact]
public void Creating_a_report()
{
var stub = new Mock<IDatabase>();
stub.Setup(x => x.GetNumberOfUsers()).Returns(10);
var sut = new Controller(stub.Object);
Report report = sut.CreateReport();
Assert.Equal(10, report.NumberOfUsers);
stub.Verify( // بررسی تعامل با استاب
x => x.GetNumberOfUsers(),
Times.Once);
}کد ۵.۳
این کارِ بررسی چیزهایی که بخشی از نتیجهی نهایی نیستن، بیشتعیینگری (overspecification) نامیده میشه. بیشتعیینگری معمولاً زمانی رخ میده که تعاملات بررسی میشن. بررسی تعاملات با استابها یک ایراد آشکار محسوب میشه، چون تستها نباید هیچ تعاملی با استابها رو بررسی کنن.
اما ماکها موضوع پیچیدهتری هستن: همهی استفادهها از ماکها منجر به تستهای شکننده نمیشن، ولی خیلی از اونها این مشکل رو ایجاد میکنن. دلیلش رو در ادامهی این فصل خواهی دید.
۵.۱.۴ استفادهی همزمان از ماکها و استابها
گاهی لازم میشه یک تستدابل بسازی که ویژگیهای هر دو رو داشته باشه: هم مثل یک استاب دادهی ورودی رو شبیهسازی کنه و هم مثل یک ماک تعامل خروجی رو بررسی کنه.
برای نمونه، در فصل ۲ تستی آورده شده بود که سبک London در واحد تستنویسی رو نشون میداد.
[Fact]
public void Purchase_fails_when_not_enough_inventory()
{
var storeMock = new Mock<IStore>();
storeMock
.Setup(x => x.HasEnoughInventory(Product.Shampoo, 5)) // نقش استاب: پاسخ از پیشتعریفشده
.Returns(false);
var sut = new Customer();
bool success = sut.Purchase(storeMock.Object, Product.Shampoo, 5);
Assert.False(success);
storeMock.Verify(// نقش ماک: بررسی تعامل خروجی
x => x.RemoveInventory(Product.Shampoo, 5),
Times.Never);
}کد ۵.۴
این تست از storeMock برای دو منظور استفاده میکنه:
- یک پاسخ از پیشتعریفشده برمیگردونه (از متد
HasEnoughInventory()→ نقش استاب) - و یک فراخوانی از طرف SUT رو بررسی میکنه (به متد
RemoveInventory()→ نقش ماک)
نکتهی مهم اینه که این دو متد متفاوت هستن. تست پاسخ رو از HasEnoughInventory() تنظیم میکنه، اما بررسی رو روی RemoveInventory() انجام میده. بنابراین، قانون «عدم بررسی تعاملات با استابها» نقض نمیشه.
وقتی یک تستدابل هم ویژگیهای ماک رو داشته باشه و هم ویژگیهای استاب رو، همچنان بهش ماک گفته میشه، نه استاب. دلیلش هم اینه که باید یک نام انتخاب بشه و از طرفی، ماک بودن اهمیت بیشتری نسبت به استاب بودن داره.
۵.۱.۵ ارتباط ماکها و استابها با فرمانها (Command) و پرسوجوها (Queries)
مفهوم ماکها و استابها به اصل جداسازی فرمان و پرسوجو (CQS) مربوط میشه. اصل CQS بیان میکنه که هر متد باید یا یک فرمان باشه یا یک پرسوجو، اما نه هر دو. همانطور که در شکل ۵.۳ نشان داده شده، فرمانها متدهایی هستن که اثر جانبی تولید میکنن و هیچ مقداری برنمیگردونن (void). نمونههایی از اثر جانبی شامل تغییر وضعیت یک شیء، تغییر یک فایل در سیستم فایل و غیره هست. پرسوجوها برعکس این هستن—بدون اثر جانبی و یک مقدار برمیگردونن.
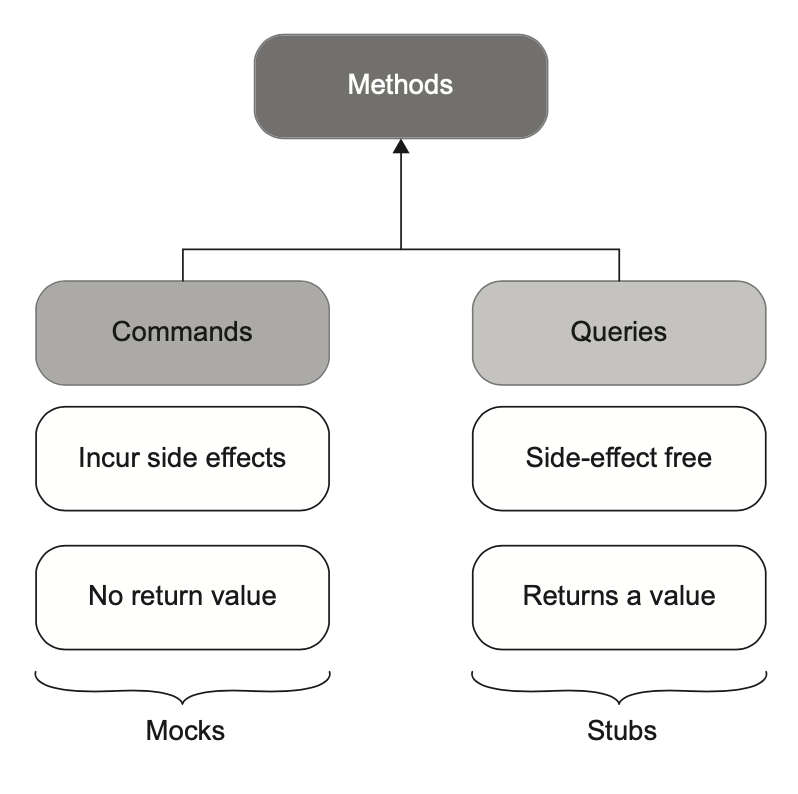
برای اینکه این اصل رعایت بشه، باید حواست باشه اگه یه متد اثر جانبی ایجاد میکنه، خروجیش void باشه. و اگه یه متد قراره مقداری برگردونه، دیگه نباید هیچ اثر جانبی داشته باشه. یعنی وقتی یه سؤال میپرسی، جوابش نباید تغییر کنه. کدی که این جداسازی رو داشته باشه خیلی راحتتر خونده میشه؛ با یه نگاه به امضای متد میفهمی چی کار میکنه، بدون اینکه بری سراغ جزئیاتش.
البته همیشه نمیشه این اصل رو کامل رعایت کرد. بعضی وقتها منطقیه یه متد هم اثر جانبی داشته باشه و هم چیزی برگردونه. مثال معروفش stack.Pop() هست: هم عنصر بالای پشته رو حذف میکنه و هم همون رو برمیگردونه. با این حال، هر جا که بشه بهتره به اصل CQS پایبند بمونیم.
تستدابلهایی که جایگزین فرمانها (commands) میشن، ماک هستن. به همین شکل، تستدابلهایی که جایگزین پرسوجوها (queries) میشن، استاب هستن. دوباره به دو تست از کدهای ۵.۱ و ۵.۲ نگاه کن (فقط بخشهای مربوطه رو اینجا میارم):
var mock = new Mock<IEmailGateway>();
mock.Verify(x => x.SendGreetingsEmail("user@email.com"));
var stub = new Mock<IDatabase>();
stub.Setup(x => x.GetNumberOfUsers()).Returns(10);متد SendGreetingsEmail() یه فرمانه که اثر جانبیش ارسال ایمیل هست. تستدابلی که جایگزین این فرمان شده، ماک محسوب میشه. از طرف دیگه، GetNumberOfUsers() یه پرسوجوئه که یه مقدار برمیگردونه و وضعیت دیتابیس رو تغییر نمیده. تستدابلی که جایگزین این پرسوجو شده، استاب هست.
۵.۲ رفتار قابل مشاهده در برابر جزئیات پیادهسازی
بخش ۵.۱ توضیح داد که ماک چیست. قدم بعدی برای توضیح ارتباط بین ماکها و شکنندگی تست، بررسی اینه که چه چیزی باعث چنین شکنندگی میشه.
همونطور که از فصل ۴ یادت هست، شکنندگی تست به دومین ویژگی یک تست واحد خوب مربوط میشه: مقاومت در برابر بازآرایی (Refactoring). (یادآوری: چهار ویژگی اصلی تست واحد خوب عبارتاند از: محافظت در برابر regression، مقاومت در برابر بازآرایی، بازخورد سریع، و قابلیت نگهداری.) معیار مقاومت در برابر بازآرایی مهمترین ویژگیه، چون داشتن یا نداشتن این ویژگی معمولاً یک انتخاب دوحالته است. بنابراین بهتره این معیار رو تا حد ممکن بالا نگه داریم، البته تا جایی که تست همچنان در محدودهی تست واحد باقی بمونه و وارد دستهی تستهای end-to-end نشه. تستهای end-to-end، با وجود اینکه بهترین مقاومت رو در برابر بازآرایی دارن، معمولاً نگهداریشون خیلی سختتره.
در فصل ۴ همچنین دیدی که دلیل اصلی خطای مثبت کاذب در تستها (و در نتیجه شکست در مقاومت در برابر بازآرایی) اینه که تستها به جزئیات پیادهسازی کد وابسته میشن. تنها راه جلوگیری از این وابستگی اینه که نتیجهی نهایی تولیدشده توسط کد (رفتار قابل مشاهده) رو بررسی کنیم و تا حد ممکن تستها رو از جزئیات پیادهسازی دور نگه داریم. به عبارت دیگه، تستها باید روی «چی» تمرکز کنن، نه روی «چطور». حالا دقیقاً جزئیات پیادهسازی چی هست و چه فرقی با رفتار قابل مشاهده داره؟
۵.۲.۱ رفتار قابل مشاهده همان API عمومی نیست
تمام کدهای تولیدی رو میشه در دو بُعد دستهبندی کرد:
- رابط برنامه نویسی (Api) عمومی در برابر خصوصی
- رفتار قابل مشاهده در برابر جزئیات پیادهسازی
این دستهبندیها با هم همپوشانی ندارن. یک متد نمیتونه همزمان جزو API عمومی و خصوصی باشه؛ یا عمومیه یا خصوصی. همینطور، کد یا بخشی از جزئیات داخلی پیادهسازی محسوب میشه یا بخشی از رفتار قابل مشاهدهی سیستم، ولی نمیتونه هر دو باشه.
بیشتر زبانهای برنامهنویسی مکانیزم سادهای برای تشخیص API عمومی و خصوصی دارن. مثلاً در سیشارپ میتونی هر عضو کلاس رو با کلیدواژهی private مشخص کنی تا از دید کدهای کلاینت مخفی بشه و جزو API خصوصی کلاس قرار بگیره. همین موضوع برای کلاسها هم صدق میکنه: میتونی با استفاده از کلیدواژههای private یا internal اونها رو خصوصی کنی.
تفاوت بین رفتار قابل مشاهده و جزئیات داخلی پیادهسازی یه کم ظریفتره. برای اینکه یه بخش از کد جزو رفتار قابل مشاهدهی سیستم حساب بشه، باید یکی از این کارها رو انجام بده:
- یه عملیات رو در اختیار کلاینت بذاره که به رسیدن به یکی از هدفهاش کمک کنه. عملیات یعنی متدی که یا محاسبهای انجام میده یا اثر جانبی ایجاد میکنه، یا هر دو.
- یه وضعیت (state) رو در اختیار کلاینت بذاره که به رسیدن به یکی از هدفهاش کمک کنه. وضعیت یعنی شرایط فعلی سیستم.
هر کدی که هیچکدوم از این دو کار رو انجام نده، جزئیات پیادهسازی محسوب میشه.
نکتهی مهم: اینکه یه کد رفتار قابل مشاهده بحساب بیاد یا نه، بستگی به این داره که کلاینت کیه و هدفش چیه. برای اینکه جزو رفتار قابل مشاهده باشه، کد باید ارتباط مستقیم با حداقل یکی از اون هدفها داشته باشه. منظور از «کلاینت» هم بسته به جایگاه کد فرق میکنه: میتونه کد دیگهای از همون پروژه باشه، یه اپلیکیشن خارجی، یا حتی رابط کاربری.
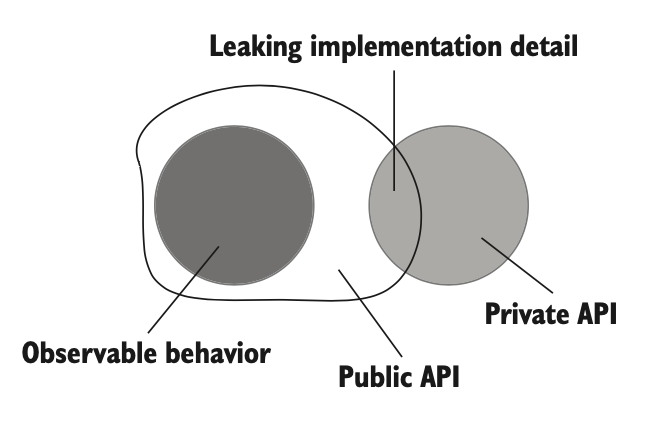
در حالت ایدهآل، سطح API عمومی سیستم باید دقیقاً با رفتار قابل مشاهدهی اون منطبق باشه، و همهی جزئیات پیادهسازی از دید کلاینتها پنهان بمونه. سیستمی که این ویژگی رو داشته باشه، یه API خوشطراحی داره (شکل ۵.۴).
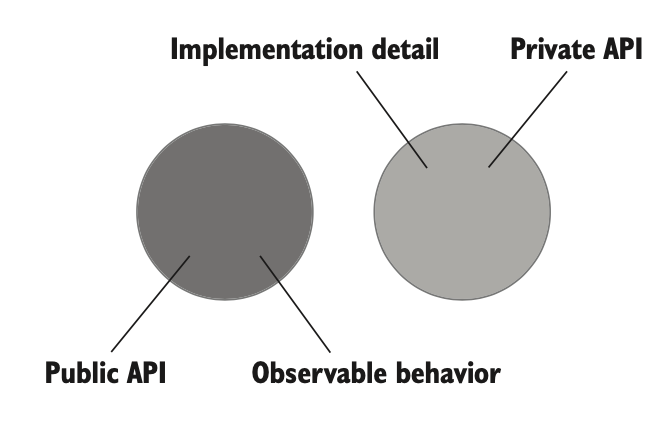
خیلی وقتها پیش میاد که API عمومی سیستم فراتر از رفتار قابل مشاهده میره و شروع میکنه به نمایش دادن جزئیات پیادهسازی. توی این حالت، جزئیات داخلی سیستم به سطح API عمومی نشت میکنن (شکل ۵.۵).
۵.۲.۲ نشت جزئیات پیادهسازی: مثالی با یک عملیات
بیاییم نگاهی بندازیم به نمونههایی از کدی که جزئیات پیادهسازیشون به API عمومی راه پیدا میکنه. کد ۵.۵ یه کلاس User رو نشون میده که API عمومیاش شامل دو عضو هست: یک پراپرتی به اسم Name و یک متد به اسم NormalizeName(). این کلاس همچنین یک قاعدهی ثابت داره: اسم کاربر نباید بیشتر از ۵۰ کاراکتر باشه و اگر بیشتر شد باید کوتاه بشه.
public class User
{
public string Name { get; set; }
public string NormalizeName(string name)
{
string result = (name ?? "").Trim();
if (result.Length > 50)
return result.Substring(0, 50);
return result;
}
}
public class UserController
{
public void RenameUser(int userId, string newName)
{
User user = GetUserFromDatabase(userId);
string normalizedName = user.NormalizeName(newName);
user.Name = normalizedName;
SaveUserToDatabase(user);
}
}کد ۵.۵
کلاس UserController در واقع کد کلاینت محسوب میشه. این کلاس از User در متد RenameUser استفاده میکنه و هدفش همونطور که حدس زدی تغییر اسم کاربره.
حالا چرا API کلاس User طراحی خوبی نداره؟ دوباره به اعضاش نگاه کن: پراپرتی Name و متد NormalizeName. هر دو عمومی هستن. برای اینکه API کلاس خوب طراحی شده باشه، این اعضا باید جزو رفتار قابل مشاهده باشن. یعنی باید یکی از این دو کار رو انجام بدن:
- یه عملیات رو در اختیار کلاینت بذارن که به رسیدن به هدفش کمک کنه.
- یه وضعیت رو در اختیار کلاینت بذارن که به رسیدن به هدفش کمک کنه.
از بین این دو عضو، فقط پراپرتی Name این شرط رو برآورده میکنه. چون setter داره و به UserController اجازه میده هدفش یعنی تغییر اسم کاربر رو محقق کنه.
اما متد NormalizeName با اینکه یه عملیات محسوب میشه، ارتباط مستقیمی با هدف کلاینت نداره. تنها دلیلی که UserController این متد رو صدا میزنه، رعایت قاعده کلاس User هست. بنابراین NormalizeName یه جزئیات پیادهسازی محسوب میشه که به API عمومی کلاس نشت کرده (شکل ۵.۶).
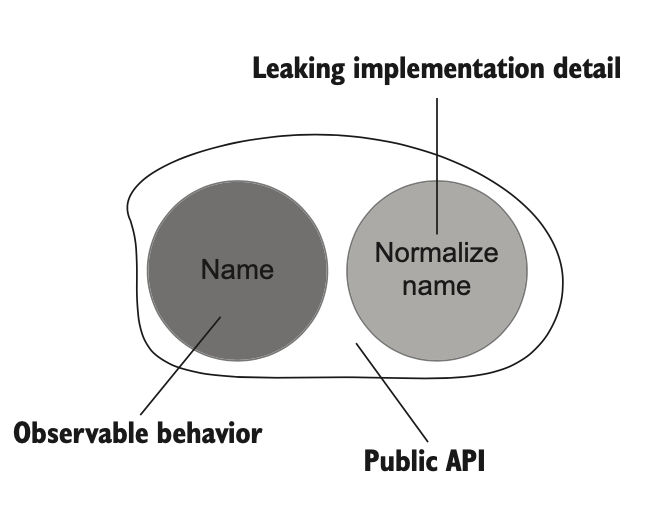
User طراحی خوبی نداره، چون متد NormalizeName رو به صورت عمومی در معرض قرار داده؛ در حالی که این متد جزو رفتار قابل مشاهده نیست و فقط یک جزئیات پیادهسازی داخلی محسوب میشه.برای اصلاح این وضعیت و خوشطراحی کردن API کلاس، لازم است که User متد NormalizeName() را پنهان کند و آن را به صورت داخلی در setter پراپرتی فراخوانی کند، بدون اینکه کد کلاینت مجبور باشد این کار را انجام دهد. لیستینگ ۵.۶ این رویکرد را نشان میدهد.
public class User
{
private string _name;
public string Name
{
get => _name;
set => _name = NormalizeName(value);
}
private string NormalizeName(string name)
{
string result = (name ?? "").Trim();
if (result.Length > 50)
return result.Substring(0, 50);
return result;
}
}
public class UserController
{
public void RenameUser(int userId, string newName)
{
User user = GetUserFromDatabase(userId);
user.Name = newName;
SaveUserToDatabase(user);
}
}کد ۵.۶
حالا API کلاس User در کد ۵.۶ خوشطراحی شده است: فقط رفتار قابل مشاهده (پراپرتی Name) به صورت عمومی ارائه شده، در حالی که جزئیات پیادهسازی (متد NormalizeName) پشت API خصوصی پنهان شدهاند (شکل ۵.۷).

یادداشت: از نظر دقیق، getter پراپرتی Name هم باید خصوصی بشه، چون توسط UserController استفاده نمیشه. اما در عمل، تقریباً همیشه میخوای تغییراتی رو که انجام دادی دوباره بخونی. بنابراین، در یک پروژهی واقعی قطعاً موارد استفادهی دیگهای وجود خواهد داشت که نیاز به دیدن نام فعلی کاربران از طریق getter پراپرتی Name دارن.
یک قاعدهی سرانگشتی خوب وجود داره که میتونه بهت کمک کنه تشخیص بدی آیا یک کلاس جزئیات پیادهسازی خودش رو لو میده یا نه. اگر تعداد عملیاتهایی که کلاینت باید روی کلاس اجرا کنه تا به یک هدف واحد برسه بیشتر از یکی باشه، اون کلاس احتمالاً جزئیات پیادهسازی رو نشت میده.
در حالت ایدهآل، هر هدف مستقل باید فقط با یک عملیات محقق بشه.
برای مثال، در کد ۵.۵، UserController مجبور بود دو عملیات از کلاس User استفاده کنه:
string normalizedName = user.NormalizeName(newName);
user.Name = normalizedName;اما بعد از بازطراحی، تعداد عملیاتها به یک کاهش پیدا کرد:
user.Name = newName;تجربه نشون داده این قاعدهی سرانگشتی در اکثر مواردی که منطق تجاری درگیر هست صدق میکنه. البته ممکنه استثناهایی هم وجود داشته باشه. با این حال، همیشه موقعی که کدت این قاعده رو نقض میکنه، بررسی کن که آیا جزئیات پیادهسازی به API عمومی نشت کرده یا نه.
۵.۲.۳ API خوشطراحی و کپسولهسازی
حفظ یک API خوب ارتباط مستقیم به مفهوم کپسولهسازی داره. همونطور که احتمالاً از فصل ۳ یادت هست، کپسولهسازی یعنی محافظت از کدت در برابر ناسازگاریها؛ همون نقض اینورینتها. اینورینت یعنی شرطی که باید همیشه برقرار باشه. کلاس User در مثال قبلی یه همچین اینورینتی داشت: هیچ کاربری نباید نامی داشته باشه که از ۵۰ کاراکتر بیشتر بشه.
لو دادن جزئیات پیادهسازی معمولاً با نقض اینورینت همزمانه؛ خیلی وقتها اولی باعث دومی میشه. نسخهی اولیهی User هم جزئیات پیادهسازی رو لو میداد، هم کپسولهسازی درست رو نگه نمیداشت. به کلاینت اجازه میداد اینورینت رو دور بزنه و بدون نرمالسازی، یه نام جدید به کاربر نسبت بده.
کپسولهسازی برای نگهداشت پایگاه کد در بلندمدت خیلی مهمه. دلیلش هم پیچیدگیه. پیچیدگی کد یکی از بزرگترین چالشهاییست که توی توسعهی نرمافزار باهاش روبهرو میشی. هرچی کد پیچیدهتر بشه، کار کردن باهاش سختتر میشه و همین باعث کند شدن سرعت توسعه و زیاد شدن باگها میشه.
بدون کپسولهسازی، راه عملی برای مدیریت این پیچیدگی رو به رشد نداری. وقتی API کد بهت نشون نمیده چه کارهایی مجازه و چه کارهایی نه، مجبور میشی کلی اطلاعات رو توی ذهن نگه داری تا مطمئن باشی تغییرات جدید ناسازگاری ایجاد نمیکنن. این خودش بار ذهنی اضافهای به فرآیند برنامهنویسی وارد میکنه. باید تا جای ممکن این بار رو از دوشت برداری. نمیتونی همیشه به خودت اعتماد کنی که کار درست رو انجام بدی—پس باید امکان انجام کار اشتباه رو کلاً حذف کنی. بهترین راه برای این کار حفظ کپسولهسازی درسته، طوری که پایگاه کد حتی گزینهای برای انجام کار نادرست در اختیارت نذاره.
در نهایت، کپسولهسازی همون هدفی رو دنبال میکنه که تست واحد داره: فراهم کردن امکان رشد پایدار پروژهی نرمافزاری.
یه اصل مشابه هم هست به اسم tell-don’t-ask. این مفهوم رو مارتین فاولر مطرح کرده (https://martinfowler.com/bliki/TellDontAsk.html) و منظورش اینه که دادهها رو همراه با توابعی که روی اون دادهها کار میکنن نگه داری. میتونی این اصل رو بهعنوان نتیجهی مستقیم کپسولهسازی ببینی. کپسولهسازی هدفه، و کنار هم آوردن داده و توابع، بهعلاوهی مخفی کردن جزئیات پیادهسازی، ابزار رسیدن به اون هدف هستن:
- مخفی کردن جزئیات پیادهسازی باعث میشه بخشهای داخلی کلاس از دید کلاینتها دور بمونه و احتمال خراب شدن اون بخشها کمتر بشه.
- کنار هم آوردن داده و عملیات باعث میشه این عملیاتها اینورینتهای کلاس رو نقض نکنن.
۵.۲.۴ نشت جزئیات پیادهسازی: مثالی با وضعیت
مثالی که در کد ۵.۵ دیدی، یک عملیات (متد NormalizeName) رو نشون میداد که جزئیات پیادهسازی رو به API عمومی لو میداد. حالا بیاییم یه نمونهی دیگه رو بررسی کنیم، این بار با وضعیت. کد زیر کلاس MessageRenderer رو نشون میده که در فصل ۴ دیدی. این کلاس از مجموعهای از زیربخشها استفاده میکنه تا نمایش HTML یک پیام رو بسازه؛ پیامی که شامل هدر، بدنه و فوتره.
public class MessageRenderer : IRenderer
{
public IReadOnlyList<IRenderer> SubRenderers { get; }
public MessageRenderer()
{
SubRenderers = new List<IRenderer>
{
new HeaderRenderer(),
new BodyRenderer(),
new FooterRenderer()
};
}
public string Render(Message message)
{
return SubRenderers
.Select(x => x.Render(message))
.Aggregate("", (str1, str2) => str1 + str2);
}
}کد ۵.۷
کالکشن SubRenderers عمومی است. اما آیا بخشی از رفتار قابل مشاهده محسوب میشود؟ اگر هدف کلاینت رندر کردن یک پیام HTML باشد، جواب منفی است. تنها عضوی که کلاینت به آن نیاز دارد متد Render است. بنابراین SubRenderers هم یک جزئیات پیادهسازی لو رفته به حساب میآید.
این مثال دوباره مطرح شد چون قبلاً برای توضیح یک تست شکننده از آن استفاده شده بود. آن تست دقیقاً به خاطر وابستگی به این جزئیات پیادهسازی شکننده بود—ترکیب کالکشن را بررسی میکرد. مشکل شکنندگی با هدفگیری دوبارهی تست به سمت متد Render حل شد. نسخهی جدید تست پیام خروجی را بررسی میکرد؛ همان چیزی که کد کلاینت به آن اهمیت میداد، یعنی رفتار قابل مشاهده.
همانطور که میبینی، بین تستهای واحد خوب و یک API خوشطراحی ارتباط ذاتی وجود دارد. وقتی همهی جزئیات پیادهسازی را خصوصی نگه داری، تستها چارهای جز بررسی رفتار قابل مشاهدهی کد ندارند، و همین مقاومت آنها در برابر تغییرات و بازآرایی را بهطور خودکار افزایش میدهد.
نکته: خوشطراحی بودن API بهطور خودکار کیفیت تستهای واحد را بهتر میکند.
یه راهنمای دیگه هم از تعریف API خوشطراحی بیرون میاد: باید حداقل تعداد ممکن عملیات و وضعیت رو عمومی کنی. فقط کدی که مستقیم به کلاینت کمک میکنه به هدفش برسه باید پابلیک باشه. هر چیز دیگهای جزئیات پیادهسازی محسوب میشه و باید پشت API خصوصی پنهان بشه.
دقت کن که چیزی به اسم «نشت رفتار قابل مشاهده» وجود نداره؛ این موضوع قرینهی نشت جزئیات پیادهسازی نیست. چون در حالی که میتونی یه جزئیات پیادهسازی رو لو بدی (مثل متدی یا کلاسی که قرار نیست کلاینت ازش استفاده کنه)، نمیتونی رفتار قابل مشاهده رو مخفی کنی. اگه یه متد یا کلاس دیگه ارتباط مستقیم با اهداف کلاینت نداشته باشه، کلاینت نمیتونه ازش استفاده کنه و بنابراین بهتعریف، دیگه جزو رفتار قابل مشاهده محسوب نمیشه.
جدول زیر همهی این نکات رو خلاصه میکنه.
| نوع Api | رفتار قابل مشاهده | جزئیات پیادهسازی |
|---|---|---|
| عمومی | خوب | بد |
| خصوصی | N/A | خوب |
۵.۳ رابطهی بین ماکها و شکنندگی تستها
بخشهای قبلی تعریف ماک رو توضیح دادن و تفاوت بین رفتار قابل مشاهده و جزئیات پیادهسازی رو نشون دادن. توی این بخش قراره با معماری ششضلعی آشنا بشی، فرق بین ارتباطات داخلی و خارجی رو ببینی، و در نهایت رابطهی بین ماکها و شکنندگی تستها رو یاد بگیری.
۵.۳.۱ تعریف معماری ششضلعی
یک اپلیکیشن معمولی از دو لایه تشکیل میشود: دامنه و سرویسهای اپلیکیشن، همونطور که در شکل ۵.۸ نشون داده شده. لایهی دامنه در وسط دیاگرام قرار میگیره چون بخش مرکزی اپلیکیشنه. این لایه منطق کسبوکار رو در خودش داره؛ همون کارکرد اصلی که اپلیکیشن برای اون ساخته شده. لایهی دامنه و منطق کسبوکارش این اپلیکیشن رو از بقیه متمایز میکنه و برای سازمان مزیت رقابتی به وجود میآره.
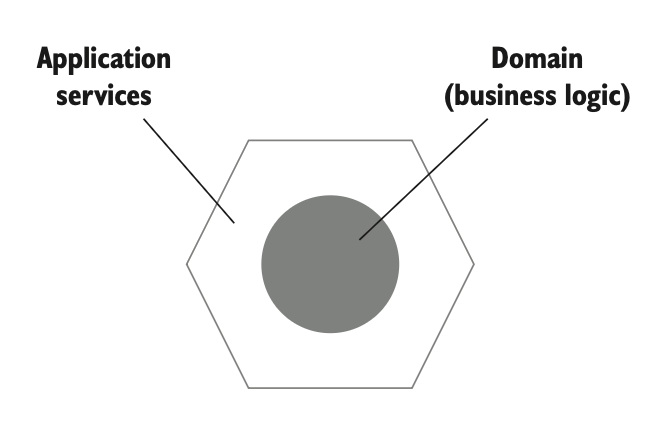
لایهی سرویسهای اپلیکیشن روی لایهی دامنه قرار میگیره و ارتباط بین اون لایه و دنیای بیرون رو هماهنگ میکنه. مثلاً اگه اپلیکیشن تو یه API مبتنی بر REST باشه، همهی درخواستها اول به لایهی سرویسهای اپلیکیشن میرسن. این لایه بعدش کار رو بین کلاسهای دامنه و وابستگیهای بیرونی هماهنگ میکنه. نمونهای از این هماهنگی توی سرویس اپلیکیشن این کارها رو انجام میده:
- کوئری گرفتن از دیتابیس و استفاده از دادهها برای ساختن یک نمونه از کلاس دامنه
- صدا زدن یک عملیات روی اون نمونه
- ذخیره کردن نتیجه دوباره در دیتابیس
ترکیب لایهی سرویسهای اپلیکیشن و لایهی دامنه یک ششضلعی میسازه که خودش نمایندهی اپلیکیشن توئه. این ششضلعی میتونه با اپلیکیشنهای دیگه تعامل داشته باشه، که هر کدوم با ششضلعی خودشون نمایش داده میشن (مثل شکل ۵.۹). این اپلیکیشنهای دیگه میتونن سرویس SMTP، یه سیستم شخص ثالث، یا یه message bus باشن. مجموعهای از این ششضلعیهای در تعامل، معماری ششضلعی رو تشکیل میده.

اصطلاح معماری ششضلعی توسط الیستر کاکبرن معرفی شد. هدفش اینه که سه راهنمای مهم رو برجسته کنه:
- جداسازی مسئولیتها بین لایهی دامنه و سرویسهای اپلیکیشن: منطق کسبوکار مهمترین بخش اپلیکیشنه. بنابراین لایهی دامنه باید فقط مسئول همین منطق باشه و از هر مسئولیت دیگهای معاف بشه. وظایفی مثل ارتباط با اپلیکیشنهای خارجی یا گرفتن داده از دیتابیس باید به سرویسهای اپلیکیشن سپرده بشه. در مقابل، سرویسهای اپلیکیشن نباید هیچ منطق کسبوکاری داشته باشن. وظیفهی اونها اینه که لایهی دامنه رو تطبیق بدن: درخواستهای ورودی رو به عملیات روی کلاسهای دامنه ترجمه کنن و بعد نتیجه رو ذخیره یا به کلاینت برگردونن. میتونی لایهی دامنه رو مجموعهای از دانش دامنه (چگونگیها) و سرویسهای اپلیکیشن رو مجموعهای از سناریوهای کسبوکار (چه چیزها) ببینی.
- ارتباطات داخل اپلیکیشن: معماری ششضلعی جریان یکطرفهی وابستگیها رو تجویز میکنه: از لایهی سرویسهای اپلیکیشن به لایهی دامنه. کلاسهای داخل دامنه فقط باید به همدیگه وابسته باشن و نباید به کلاسهای سرویسهای اپلیکیشن وابسته بشن. این راهنما از اصل قبلی ناشی میشه. جداسازی مسئولیتها یعنی سرویسهای اپلیکیشن از دامنه خبر دارن، اما برعکسش درست نیست. لایهی دامنه باید کاملاً از دنیای بیرون جدا باشه.
- ارتباطات بین اپلیکیشنها: اپلیکیشنهای خارجی از طریق یک رابط مشترک که توسط سرویسهای اپلیکیشن نگهداری میشه به اپلیکیشن تو وصل میشن. هیچکس دسترسی مستقیم به لایهی دامنه نداره. هر ضلع ششضلعی یک اتصال ورودی یا خروجی رو نشون میده. البته اینکه ششضلعی شش ضلع داره به این معنی نیست که اپلیکیشن فقط میتونه به شش اپلیکیشن دیگه وصل بشه. تعداد اتصالها دلخواه و میتونه زیاد باشه. نکته اینه که چنین اتصالهای متعددی وجود دارن.
هر لایهی اپلیکیشن رفتار قابل مشاهدهی خودش رو نشون میده و مجموعهای از جزئیات پیادهسازی مخصوص به خودش رو داره. مثلاً رفتار قابل مشاهدهی لایهی دامنه مجموع عملیاتها و وضعیتهاییست که به لایهی سرویسهای اپلیکیشن کمک میکنه حداقل یکی از اهدافش رو محقق کنه. اصول یک API خوشطراحی ماهیت fractal دارن: هم برای کل یک لایه صدق میکنن، هم برای یک کلاس منفرد.
وقتی API هر لایه رو درست طراحی کنی (یعنی جزئیات پیادهسازی رو مخفی کنی)، تستهات هم ساختار fractal پیدا میکنن؛ اونها رفتاری رو بررسی میکنن که به تحقق همون اهداف کمک میکنه، اما در سطوح مختلف. یه تست روی سرویس اپلیکیشن بررسی میکنه این سرویس چطور به یک هدف کلی و درشتدانه که کلاینت بیرونی مطرح کرده میرسه. در عین حال، یه تست روی کلاس دامنه یک زیرهدف رو بررسی میکنه که بخشی از اون هدف بزرگتره (شکل ۵.۱۰).

تو فصلهای قبلی یادته گفته بودم هر تست باید قابل ردیابی به یک نیاز کسبوکار مشخص باشه. هر تست باید یه داستان تعریف کنه که برای کارشناس دامنه معنا داشته باشه؛ اگه اینطور نباشه، نشونهی محکمیه که تست به جزئیات پیادهسازی گره خورده و شکننده شده. حالا میتونی ببینی چرا.
رفتار قابل مشاهده از لایههای بیرونی به سمت مرکز جریان پیدا میکنه. هدف کلی که کلاینت بیرونی مطرح میکنه به زیرهدفهایی ترجمه میشه که کلاسهای دامنه محققشون میکنن. بنابراین هر بخش از رفتار قابل مشاهده در لایهی دامنه، ارتباطش رو با یک سناریوی کسبوکار حفظ میکنه. میتونی این ارتباط رو بهصورت بازگشتی از درونیترین لایه (دامنه) به بیرون دنبال کنی: اول به سرویسهای اپلیکیشن و بعد به نیازهای کلاینت بیرونی. این قابلیت ردیابی از تعریف رفتار قابل مشاهده ناشی میشه. برای اینکه یه قطعه کد جزو رفتار قابل مشاهده باشه، باید به کلاینت کمک کنه یکی از اهدافش رو محقق کنه. برای کلاس دامنه، کلاینت همون سرویس اپلیکیشنه؛ برای سرویس اپلیکیشن، کلاینت همون کاربر بیرونی.
تستهایی که یه کدبیس با API خوشطراحی رو بررسی میکنن هم ارتباط مستقیم با نیازهای کسبوکار دارن، چون فقط به رفتار قابل مشاهده گره میخورن. مثال خوبش کلاسهای User و UserController در کد زیر هست.
public class User
{
private string _name;
public string Name
{
get => _name;
set => _name = NormalizeName(value);
}
private string NormalizeName(string name)
{
/* Trim name down to 50 characters */
}
}
public class UserController
{
public void RenameUser(int userId, string newName)
{
User user = GetUserFromDatabase(userId);
user.Name = newName;
SaveUserToDatabase(user);
}
}کد ۵.۸
در این مثال، UserController یک سرویس اپلیکیشن است. با فرض اینکه کلاینت بیرونی هدف مشخصی برای نرمالسازی نامها نداره و این کار فقط بهخاطر محدودیتهای خود اپلیکیشن انجام میشه، متد NormalizeName در کلاس User قابل ردیابی به نیازهای کلاینت نیست. بنابراین این متد یک جزئیات پیادهسازی محسوب میشه و باید خصوصی باشه (که قبلاً همین کار رو کردیم). علاوه بر این، تستها نباید این متد رو مستقیماً بررسی کنن؛ بلکه باید اون رو فقط بهعنوان بخشی از رفتار قابل مشاهدهی کلاس تست کنن—در این مثال، setter مربوط به ویژگی Name.
این راهنما که همیشه باید API عمومی کدبیس رو به نیازهای کسبوکار ردیابی کنیم، برای اکثر کلاسهای دامنه و سرویسهای اپلیکیشن صدق میکنه، اما برای کدهای ابزاری و زیرساختی کمتر کاربرد داره. مشکلاتی که این نوع کدها حل میکنن معمولاً خیلی سطح پایین و جزئی هستن و نمیشه اونها رو به یک سناریوی کسبوکار مشخص ربط داد.
۵.۳.۲ ارتباطات درونسیستمی در مقابل ارتباطات بینسیستمی
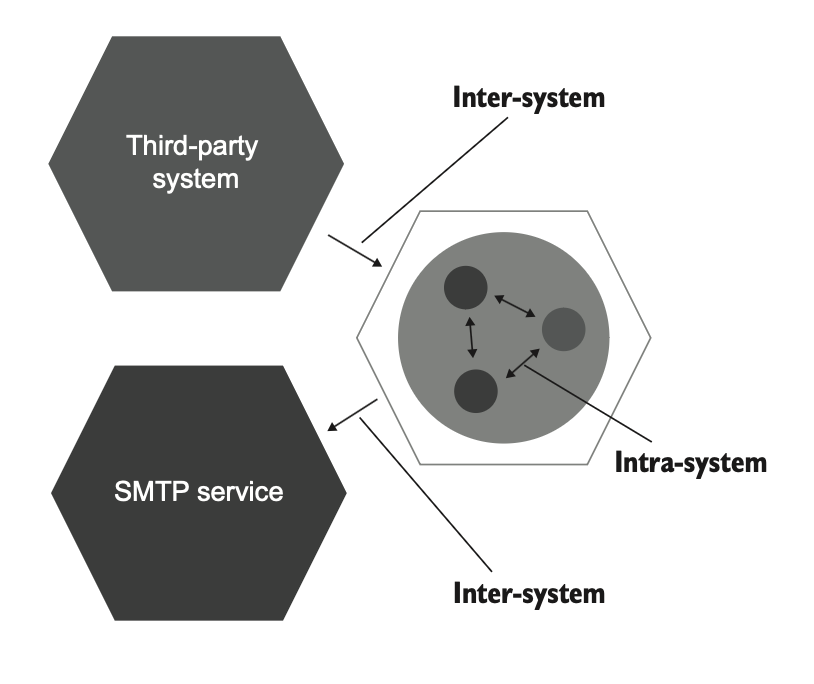
در یک اپلیکیشن معمولی دو نوع ارتباط وجود دارد: درونسیستمی و بینسیستمی.
- ارتباطات درونسیستمی: ارتباط بین کلاسهای داخل خود اپلیکیشن.
- ارتباطات بینسیستمی: زمانی که اپلیکیشن با اپلیکیشنهای دیگر صحبت میکند. (شکل ۵.۱۱)
یادداشت: ارتباطات درونسیستمی جزئیات پیادهسازی هستند؛ ارتباطات بینسیستمی اینطور نیستند.
ارتباطات درونسیستمی جزئیات پیادهسازی محسوب میشن چون همکاریهایی که کلاسهای دامنه برای انجام یک عملیات با هم دارن بخشی از رفتار قابل مشاهده نیست. این همکاریها ارتباط مستقیم با هدف کلاینت ندارن. بنابراین، وابستگی تستها به چنین همکاریهایی باعث شکنندگی میشه.
ارتباطات بینسیستمی موضوع متفاوتیه. برخلاف همکاری بین کلاسهای داخل اپلیکیشن، نحوهی تعامل سیستم با دنیای بیرون رفتار قابل مشاهدهی کل سیستم رو شکل میده. این تعامل بخشی از قرارداده که اپلیکیشن باید همیشه حفظش کنه (شکل ۵.۱۲).
این ویژگی ارتباطات بینسیستمی از نحوهی تکامل اپلیکیشنهای جداگانه با هم ناشی میشه. یکی از اصول اصلی این تکامل حفظ سازگاری عقبرو (backward compatibility) است. فارغ از اینکه چه تغییرات یا بازآراییهایی (refactor) داخل سیستم انجام بدی، الگوی ارتباطی که برای صحبت با اپلیکیشنهای خارجی استفاده میکنی باید همیشه ثابت بمونه تا اون اپلیکیشنها بتونن درکش کنن. مثلاً پیامهایی که اپلیکیشن روی یک باس (bus) منتشر میکنه باید ساختارشون رو حفظ کنن، یا فراخوانیهایی که به سرویس SMTP ارسال میشن باید همون تعداد و نوع پارامترها رو داشته باشن، و همینطور ادامه پیدا کنه.
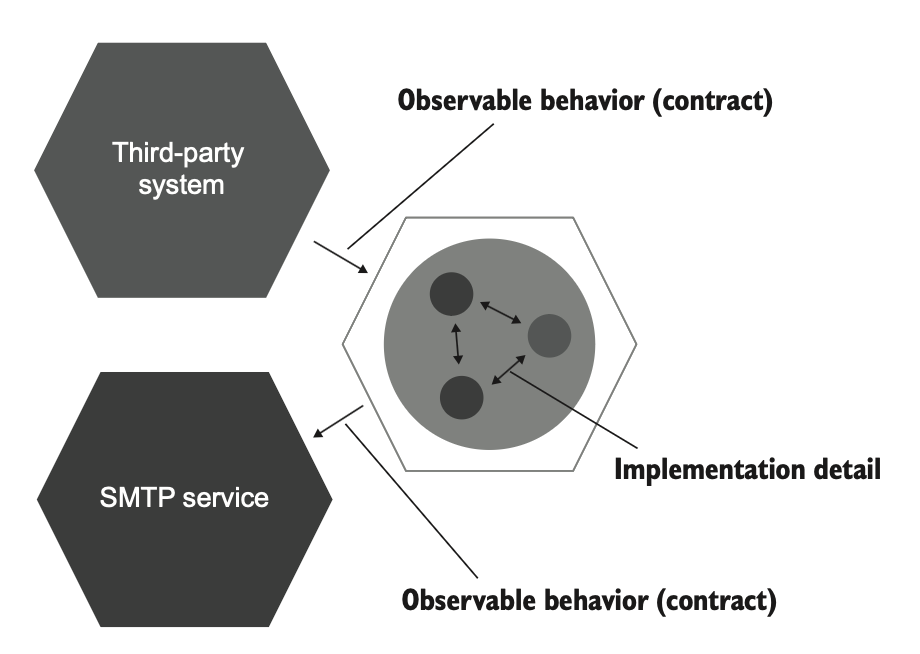
استفاده از mockها زمانی مفید است که بخواهیم الگوی ارتباط بین سیستم و اپلیکیشنهای خارجی را بررسی کنیم. در مقابل، استفاده از mock برای بررسی ارتباط بین کلاسهای داخل سیستم باعث میشود تستها به جزئیات پیادهسازی گره بخورند و در نتیجه در برابر بازآرایی (refactoring) مقاومت کافی نداشته باشند.
۵.۳.۳ ارتباطات درونسیستمی در مقابل ارتباطات بینسیستمی: یک مثال
برای روشن کردن تفاوت بین ارتباطات درونسیستمی و بینسیستمی، مثال کلاسهای Customer و Store که در فصل ۲ و همین فصل استفاده شده بود رو گسترش میدیم.
فرض کن یک سناریوی کسبوکار داریم:
- مشتری تلاش میکنه محصولی رو از فروشگاه بخره.
- اگر مقدار محصول در فروشگاه کافی باشه، آنگاه:
- موجودی از فروشگاه کم میشه.
- یک رسید ایمیلی برای مشتری ارسال میشه.
- یک تأییدیه برگردانده میشه.
همچنین فرض کنیم اپلیکیشن یک API بدون رابط کاربری است.
در کد بعدی، کلاس CustomerController یک سرویس اپلیکیشن است که کار بین کلاسهای دامنه (Customer, Product, Store) و اپلیکیشن خارجی (EmailGateway که پروکسی به سرویس SMTP است) رو هماهنگ میکنه.
public class CustomerController
{
public bool Purchase(int customerId, int productId, int quantity)
{
Customer customer = _customerRepository.GetById(customerId);
Product product = _productRepository.GetById(productId);
bool isSuccess = customer.Purchase(
_mainStore, product, quantity);
if (isSuccess)
{
_emailGateway.SendReceipt(
customer.Email, product.Name, quantity);
}
return isSuccess;
}
}کد ۵.۹
اعتبارسنجی پارامترهای ورودی برای اختصار حذف شده است. در متد Purchase، مشتری بررسی میکند که آیا موجودی کافی در فروشگاه وجود دارد یا نه و در صورت وجود، مقدار محصول کاهش مییابد.
عمل خرید یک سناریوی کسبوکار است که هم ارتباطات درونسیستمی و هم ارتباطات بینسیستمی دارد. ارتباطات بینسیستمی همانهایی هستند که بین سرویس اپلیکیشن CustomerController و دو سیستم خارجی رخ میدهند: اپلیکیشن شخص ثالث (که همان کلاینت آغازکنندهی سناریو است) و درگاه ایمیل. ارتباط درونسیستمی بین کلاسهای دامنهی Customer و Store اتفاق میافتد (شکل ۵.۱۳).
در این مثال، فراخوانی سرویس SMTP یک اثر جانبی است که برای دنیای بیرون قابل مشاهده بوده و بنابراین رفتار قابل مشاهدهی کل اپلیکیشن را شکل میدهد.
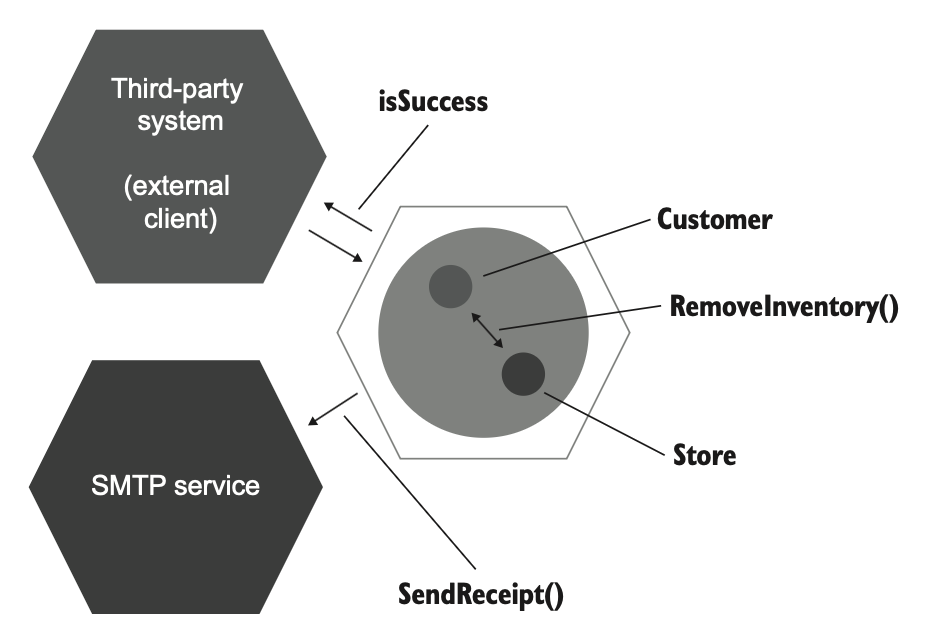
این موضوع همچنین ارتباط مستقیمی با اهداف کلاینت دارد. کلاینت اپلیکیشن یک سیستم شخص ثالث است. هدف این سیستم انجام خرید است و انتظار دارد مشتری بهعنوان بخشی از نتیجهی موفق، یک ایمیل تأیید دریافت کند.
فراخوانی سرویس SMTP یک دلیل مشروع برای استفاده از mock است. این کار باعث شکنندگی تستها نمیشود، چون میخواهید مطمئن شوید این نوع ارتباط حتی بعد از بازآرایی (refactoring) هم برقرار باقی بماند. استفاده از mock دقیقاً همین امکان را فراهم میکند.
کد بعدی مثالی از یک استفادهی بهجا از mockها را نشان میدهد.
[Fact]
public void Successful_purchase()
{
var mock = new Mock<IEmailGateway>();
var sut = new CustomerController(mock.Object);
bool isSuccess = sut.Purchase(
customerId: 1, productId: 2, quantity: 5);
Assert.True(isSuccess);
// Verifies that the
// system sent a receipt
// about the purchase
mock.Verify(
x => x.SendReceipt(
"customer@email.com", "Shampoo", 5),
Times.Once);
}کد ۵.۱۰
توجه داشته باش که فلگ isSuccess نیز برای کلاینت خارجی قابل مشاهده است و باید مورد بررسی قرار گیرد. این فلگ نیازی به استفاده از mock ندارد؛ یک مقایسهی سادهی مقدار کافی است.
حالا بیاییم نگاهی به تستی بیندازیم که ارتباط بین Customer و Store را mock میکند.
[Fact]
public void Purchase_succeeds_when_enough_inventory()
{
var storeMock = new Mock<IStore>();
storeMock
.Setup(x => x.HasEnoughInventory(Product.Shampoo, 5))
.Returns(true);
var customer = new Customer();
bool success = customer.Purchase(
storeMock.Object, Product.Shampoo, 5);
Assert.True(success);
storeMock.Verify(
x => x.RemoveInventory(Product.Shampoo, 5),
Times.Once);
}کد ۵.۱۱
برخلاف ارتباط بین CustomerController و سرویس SMTP، فراخوانی متد RemoveInventory از Customer به Store مرز اپلیکیشن را رد نمیکند؛ هم فراخواننده و هم گیرنده داخل اپلیکیشن قرار دارند. همچنین این متد نه یک عملیات و نه یک وضعیت است که به کلاینت در رسیدن به اهدافش کمک کند.
کلاینت این دو کلاسِ دامنه، CustomerController است که هدفش انجام خرید میباشد. تنها دو عضو که ارتباط مستقیم با این هدف دارند عبارتاند از:
- customer.Purchase() که خرید را آغاز میکند.
- store.GetInventory() که وضعیت سیستم را پس از تکمیل خرید نشان میدهد.
فراخوانی متد RemoveInventory یک گام میانی در مسیر رسیدن به هدف کلاینت است—یک جزئیات پیادهسازی.
۵.۴ مکتب کلاسیک در برابر مکتب لندن در تست واحد، بازنگری
یادآوری از فصل ۲ (جدول ۲.۱)، جدول زیر تفاوتهای بین مکتب کلاسیک و مکتب لندن در تست واحد را خلاصه میکند:
| مکتب | ایزولهسازی بر اساس | واحد تحت تست | استفاده از تست دابلها |
|---|---|---|---|
| مکتب لندن | واحد کد | یک کلاس | همهی وابستگیها به جز وابستگیهای تغییرناپذیر |
| مکتب کلاسیک | واحد تست | یک کلاس یا مجموعهای از کلاسها | وابستگیهای مشترک |
در فصل ۲ اشاره شد که ترجیح من مکتب کلاسیک است. مکتب لندن استفاده از mock را برای همهی وابستگیها (به جز موارد تغییرناپذیر) تشویق میکند و بین ارتباطات درونسیستمی و بینسیستمی تفاوتی قائل نمیشود. نتیجه این رویکرد، تستهایی است که به جزئیات پیادهسازی گره میخورند و در برابر بازآرایی مقاومت ندارند.
همانطور که در فصل ۴ یاد شد، معیار مقاومت در برابر بازآرایی یک انتخاب تقریباً دودویی است: تست یا مقاومت دارد یا ندارد. مصالحه روی این معیار تست را تقریباً بیارزش میکند.
مکتب کلاسیک در این زمینه بهتر عمل میکند، چون جایگزینی را فقط برای وابستگیهای مشترک بین تستها توصیه میکند؛ که تقریباً همیشه به وابستگیهای خارج از پروسه مثل سرویس SMTP یا message bus ترجمه میشود.
با این حال، مکتب کلاسیک هم در برخورد با ارتباطات بینسیستمی بینقص نیست؛ این مکتب نیز استفادهی بیش از حد از mockها را تشویق میکند، هرچند نه به اندازهی مکتب لندن.
۵.۴.۱ همهی وابستگیهای خارج از پروسه نباید mock شوند
قبل از اینکه دربارهی وابستگیهای خارج از پروسه و استفاده از mock صحبت کنیم، یک مرور سریع روی انواع وابستگیها داشته باشیم (برای جزئیات بیشتر به فصل ۲ مراجعه کنید):
- وابستگی مشترک (Shared dependency) — وابستگیای که بین تستها مشترک است (نه در کد تولیدی).
- وابستگی خارج از پروسه (Out-of-process dependency) — وابستگیای که توسط پروسهای غیر از پروسهی اجرای برنامه میزبانی میشود (برای مثال، پایگاه داده، message bus یا سرویس SMTP).
- وابستگی خصوصی (Private dependency) — هر وابستگیای که مشترک نیست.
مکتب کلاسیک میگه بهتره سراغ وابستگیهای مشترک نریم، چون این وابستگیها باعث میشن تستها روی هم اثر بذارن و دیگه نتونن مستقل و موازی اجرا بشن. این استقلال تستها، همون چیزییه که بهش ایزولهسازی تست میگیم.
حالا اگر وابستگی مشترک داخل پروسه باشه، خیلی راحت میشه برای هر تست یه نمونهی تازه ساخت و مشکل حل میشه. ولی وقتی پای وابستگیهای خارج از پروسه وسط باشه، داستان پیچیدهتر میشه. نمیتونی برای هر تست یه دیتابیس جدید یا یه message bus تازه راه بندازی؛ این کار کل مجموعه تست رو کند میکنه. معمولاً راهحل اینه که چنین وابستگیهایی رو با تست دابلها (مثل mock یا stub) جایگزین کنیم.
اما نکتهی مهم اینه که همهی وابستگیهای خارج از پروسه نباید mock بشن. اگر یه وابستگی فقط از طریق اپلیکیشن خودت قابل دسترسی باشه، ارتباط با اون جزو رفتار قابل مشاهدهی سیستم حساب نمیشه. در عمل، چنین وابستگیای بخشی از خود اپلیکیشن محسوب میشه (شکل ۵.۱۴).
یادت باشه، اینکه باید الگوی ارتباطی بین اپلیکیشن و سیستمهای خارجی رو همیشه حفظ کنیم، به خاطر نیاز به سازگاری عقبرو (backward compatibility) هست. چون نمیتونی همزمان با تغییر اپلیکیشن، اون سیستمهای خارجی رو هم تغییر بدی؛ ممکنه چرخهی انتشار متفاوتی داشته باشن یا اصلاً کنترلی روی اونها نداشته باشی.
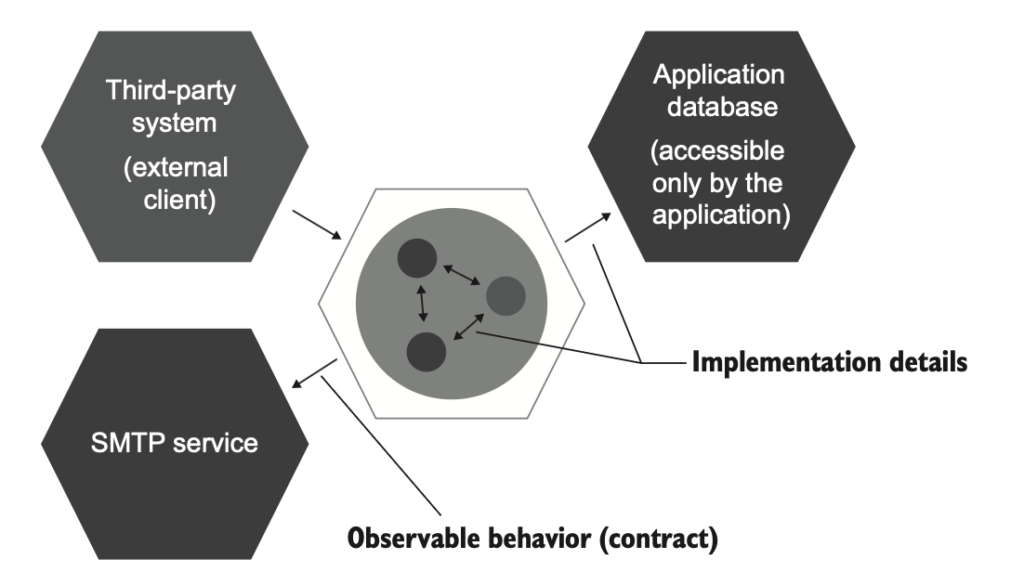
اما وقتی اپلیکیشن تو نقش یک پروکسی برای یک سیستم خارجی عمل میکنه و هیچ کلاینتی دسترسی مستقیم به اون نداره، الزام سازگاری عقبرو (backward compatibility) از بین میره. حالا میتونی اپلیکیشن رو همراه با اون سیستم خارجی منتشر کنی بدون اینکه روی کلاینتها اثری بذاره. الگوی ارتباطی با چنین سیستمی تبدیل به یک جزئیات پیادهسازی میشه.
یک مثال خوب اینجا پایگاه دادهی اپلیکیشن هست: دیتابیسی که فقط توسط اپلیکیشن خودت استفاده میشه. هیچ سیستم خارجی به این دیتابیس دسترسی نداره. بنابراین میتونی الگوی ارتباطی بین سیستم و دیتابیس اپلیکیشن رو هر طور که خواستی تغییر بدی، تا وقتی که عملکرد موجود خراب نشه. چون این دیتابیس کاملاً از دید کلاینتها پنهان شده، حتی میتونی اون رو با یک مکانیزم ذخیرهسازی کاملاً متفاوت جایگزین کنی و هیچکس متوجه نمیشه.
استفاده از mock برای وابستگیهای خارج از پروسهای که کنترل کامل روی اونها داری، باعث شکنندگی تستها میشه. نمیخوای هر بار که یک جدول رو در دیتابیس تقسیم میکنی یا نوع یکی از پارامترهای یک stored procedure رو تغییر میدی، تستهات قرمز بشن. دیتابیس و اپلیکیشن باید بهعنوان یک سیستم واحد در نظر گرفته بشن.
این موضوع البته یک چالش ایجاد میکنه: چطور میشه کار با چنین وابستگیای رو تست کرد بدون اینکه سرعت بازخورد (سومین ویژگی یک تست واحد خوب) قربانی بشه؟ این بحث رو بهطور کامل در دو فصل بعدی خواهی دید.
۵.۴.۲ استفاده از mock برای بررسی رفتار
خیلی وقتها گفته میشه mockها برای بررسی رفتار استفاده میشن. اما در بیشتر موارد اینطور نیست. نحوهی تعامل هر کلاس با کلاسهای همسایه برای رسیدن به یک هدف، هیچ ربطی به رفتار قابل مشاهده نداره؛ این فقط یک جزئیات پیادهسازی محسوب میشه.
بررسی ارتباطات بین کلاسها شبیه اینه که بخوای رفتار یک انسان رو از روی سیگنالهایی که نورونهای مغز به هم میفرستن تحلیل کنی. این سطح از جزئیات خیلی ریزه و ارزش چندانی نداره. چیزی که اهمیت داره، رفتاریه که میشه اون رو به اهداف کلاینت ربط داد. کلاینت اهمیتی نمیده کدوم نورونهای مغزت فعال میشن وقتی ازت کمک میخواد؛ تنها چیزی که براش مهمه خود کمک هست—اون هم به شکلی قابل اعتماد و حرفهای.
بنابراین mockها فقط زمانی به رفتار ربط پیدا میکنن که تعاملاتی رو بررسی کنن که از مرز اپلیکیشن عبور میکنن و اثرات جانبی اون تعاملات برای دنیای بیرون قابل مشاهده باشه.
خلاصه
- عبارت Test double یک اصطلاح کلی است که همهی وابستگیهای غیرواقعی را در تستها توصیف میکند. پنج نوع دارد: dummy، stub، spy، mock و fake که در نهایت به دو گروه تقسیم میشوند: mocks و stubs.
- دسته Spies از نظر کارکرد همان mock هستند.
- دسته Dummies و fakes همان نقش stubs را ایفا میکنند.
- دسته Mocks برای شبیهسازی و بررسی تعاملات خروجی استفاده میشوند: فراخوانیهای SUT به وابستگیها که وضعیت آنها را تغییر میدهد.
- دسته Stubs برای شبیهسازی تعاملات ورودی استفاده میشوند: فراخوانیهای SUT به وابستگیها برای دریافت داده.
- یک mock (ابزار) کلاسی از کتابخانهی mocking است که میتوان با آن mock (تست دابل) یا stub ساخت.
- بررسی تعاملات با stubs منجر به تستهای شکننده میشود، چون این تعاملات نتیجهی نهایی نیستند بلکه گامهای میانی و جزئیات پیادهسازیاند.
- اصل Command Query Separation (CQS) میگوید هر متد باید یا command باشد یا query، نه هر دو.
- تست دابلهایی که جایگزین command میشوند، mock هستند.
- تست دابلهایی که جایگزین query میشوند، stub هستند.
- کد تولیدی را میتوان در دو بعد دستهبندی کرد:
- رابط عمومی Public API در برابر رابط خصوصی Private API
- رفتار قابل مشاهده در برابر جزئیات پیادهسازی
- کدی جزو رفتار قابل مشاهده است اگر:
- یک عملیات را در اختیار کلاینت قرار دهد که به رسیدن به هدف کمک کند (محاسبه یا side effect).
- یک وضعیت را در اختیار کلاینت قرار دهد که به رسیدن به هدف کمک کند (شرایط جاری سیستم).
- کد خوب، کدی است که رفتار قابل مشاهدهاش با Public API منطبق باشد و جزئیات پیادهسازی پشت Private API پنهان شود.
- افشای جزئیات پیادهسازی معمولاً نقض کپسولهسازی یا encapsulation است، چون کلاینت میتواند با دور زدن این جزئیات، قواعد کد را بشکند.
- معماری ششضلعی (Hexagonal architecture) مجموعهای از اپلیکیشنهای در تعامل است که به شکل ششضلعی نمایش داده میشوند. هر ششضلعی دو لایه دارد:
- دامنه یا Domain
- سرویسهای اپلیکیشن یا Application services
این معماری سه اصل مهم را برجسته میکند: - جداسازی مسئولیتها بین لایهی دامنه و سرویسهای اپلیکیشن. دامنه مسئول منطق کسبوکار است و سرویسهای اپلیکیشن هماهنگی بین دامنه و سیستمهای خارجی را انجام میدهند.
- جریان یکطرفهی وابستگیها از سرویسهای اپلیکیشن به دامنه. کلاسهای دامنه فقط به هم وابستهاند، نه به سرویسهای اپلیکیشن.
- سیستمهای خارجی فقط از طریق یک رابط مشترک که توسط سرویسهای اپلیکیشن نگهداری میشود به اپلیکیشن وصل میشوند. هیچکس دسترسی مستقیم به دامنه ندارد.
- هر لایه در یک ششضلعی رفتار قابل مشاهده و مجموعهای از جزئیات پیادهسازی خودش را دارد.
- دو نوع ارتباط در اپلیکیشن وجود دارد:
- ارتباطات درونسیستمی (intra-system): بین کلاسهای داخل اپلیکیشن.
- ارتباطات بینسیستمی (inter-system): وقتی اپلیکیشن با سیستمهای خارجی صحبت میکند.
- ارتباطات درونسیستمی جزئیات پیادهسازیاند. ارتباطات بینسیستمی بخشی از رفتار قابل مشاهدهاند، مگر سیستمهای خارجیای که فقط از طریق اپلیکیشن شما قابل دسترسی باشند؛ در این حالت آنها هم جزئیات پیادهسازی محسوب میشوند.
- استفاده از mock برای بررسی ارتباطات درونسیستمی منجر به تستهای شکننده میشود. استفاده از mock فقط زمانی درست است که برای ارتباطات بینسیستمی به کار رود—ارتباطاتی که مرز اپلیکیشن را رد میکنند—و فقط زمانی که اثرات جانبی آنها برای دنیای بیرون قابل مشاهده باشد.