
این فصل شامل موارد زیر است:
- بررسی دوگانگیها بین جنبههای یک تست واحد خوب
- تعریف یک تست ایدهآل
- درک هرم تست (Test Pyramid)
- استفاده از تست جعبهسیاه (black-box) و جعبهسفید (white-box)
حالا به اصل موضوع میرسیم. در فصل ۱، ویژگیهای یک مجموعه تست واحد خوب را دیدید:
- این تستها در چرخهی توسعه ادغام شدهاند. تنها زمانی از تستها ارزش بهدست میآورید که آنها را فعالانه استفاده کنید؛ در غیر این صورت نوشتنشان بیفایده است.
- این تستها فقط بخشهای مهم کد پایهی شما را هدف قرار میدهند. همهی کدهای تولیدی شایستهی توجه یکسان نیستند. مهم است که قلب برنامه (مدل دامنهی آن) را از سایر بخشها متمایز کنید. این موضوع در فصل ۷ بررسی میشود.
- این تستها بیشترین ارزش را با کمترین هزینهی نگهداری فراهم میکنند. برای دستیابی به این ویژگی آخر، باید بتوانید:
– یک تست ارزشمند را تشخیص دهید (و بهطور ضمنی، تست کمارزش را هم)
– یک تست ارزشمند بنویسید
همونطور که تو فصل ۱ گفتیم، تشخیص یه تست ارزشمند و نوشتن یه تست ارزشمند دو مهارت جدا از هم هستن. البته دومی به اولی وابستهست؛ پس تو این فصل میخوام نشون بدم چطور میشه یه تست ارزشمند رو تشخیص داد. یه چارچوب کلی میبینی که باهاش میتونی هر تستی توی مجموعه رو تحلیل کنی. بعد با همین چارچوب میریم سراغ چند مفهوم معروف توی تست واحد: هرم تست (Test Pyramid) و تست جعبهسیاه در مقابل تست جعبهسفید. آماده باش، داریم شروع میکنیم.
۴.۱ پرداختن به چهار ستون یک تست واحد خوب
یک تست واحد خوب این چهار ویژگی رو داره:
- محافظت در برابر بازگشت خطاها (Protection against regressions)
- مقاومت در برابر بازآرایی (Resistance to refactoring)
- بازخورد سریع (Fast feedback)
- قابلیت نگهداری (Maintainability)
این چهار ویژگی پایهای هستن. میتونی ازشون برای تحلیل هر تست خودکار استفاده کنی، چه تست واحد باشه، چه یکپارچهسازی (integration) یا سرتاسر (end-to-end). هر تستی تا حدی این ویژگیها رو نشون میده. توی این بخش، دو ویژگی اول رو تعریف میکنم؛ و در بخش ۴.۲، ارتباط درونی بین اونها رو توضیح میدم.
۴.۱.۱ ستون اول: محافظت در برابر بازگشت خطاها
بیاییم با اولین ویژگی یک تست واحد خوب شروع کنیم: محافظت در برابر بازگشت خطاها. همونطور که از فصل ۱ میدونی، regression یعنی یک باگ نرمافزاری؛ وقتی یک قابلیت بعد از تغییر کد درست کار نمیکنه، معمولاً بعد از اضافه کردن یک قابلیت جدید.
این نوع خطاها آزاردهندهان، اما بدترین بخش ماجرا این نیست. مشکل اصلی اینه که هرچی قابلیتهای بیشتری توسعه بدی، احتمال بیشتری وجود داره که یکی از اونها با انتشار جدید خراب بشه. واقعیت ناخوشایند زندگی برنامهنویسی اینه که کد یک دارایی نیست، بلکه یک بدهی محسوب میشه. هرچی کدبیس بزرگتر باشه، بیشتر در معرض باگهای احتمالی قرار میگیره. به همین دلیل خیلی مهمه که محافظت خوبی در برابر regressions داشته باشی. بدون چنین محافظتی، نمیتونی رشد پروژه رو در بلندمدت حفظ کنی—زیر بار تعداد روزافزون باگها دفن میشی.
برای ارزیابی اینکه یک تست چقدر در محافظت در برابر regressions خوب عمل میکنه، باید این موارد رو در نظر بگیری:
- میزان کدی که در طول تست اجرا میشه
- پیچیدگی اون کد
- اهمیت دامنهای اون کد
به طور کلی، هرچی حجم بیشتری از کد اجرا بشه، احتمال بیشتری وجود داره که تست یک regression رو آشکار کنه. البته به شرطی که تست مجموعهی مناسبی از assertionها داشته باشه؛ چون فقط اجرای کد کافی نیست. اینکه بدونی کد بدون exception اجرا میشه خوبه، اما باید نتیجهای که تولید میکنه رو هم اعتبارسنجی کنی.
دقت کن که فقط حجم کد مهم نیست، بلکه پیچیدگی و اهمیت دامنهای اون هم اهمیت داره. کدی که منطق تجاری پیچیده رو نشون میده خیلی مهمتر از کدهای ساده و تکراریه—باگ توی قابلیتهای حیاتی کسبوکار بیشترین آسیب رو میزنه.
از طرف دیگه، تست کردن کدهای خیلی ساده معمولاً ارزش زیادی نداره. این جور کدها کوتاهن و منطق تجاری خاصی ندارن. تستهایی که چنین کدهایی رو پوشش میدن، شانس کمی برای پیدا کردن خطای regression دارن، چون جای زیادی برای اشتباه وجود نداره. نمونهی کد ساده میتونه یه property تکخطی باشه مثل:
public class User
{
public string Name { get; set; }
}همچنین علاوه بر کدی که خودت نوشتی، کدی که ننوشتی هم حساب میشه: مثل کتابخونهها، فریمورکها و سیستمهای خارجی که توی پروژه استفاده میشن. این کدها تقریباً به اندازهی کد خودت روی عملکرد نرمافزار تأثیر دارن. برای بهترین محافظت، تست باید این کتابخونهها، فریمورکها و سیستمهای خارجی رو هم در محدودهی تست قرار بده تا مطمئن بشه فرضیاتی که نرمافزار دربارهی این وابستگیها داره درست هستن.
نکته: برای بیشترین محافظت در برابر regressions، تست باید تا جای ممکن بخشهای بیشتری از کد رو اجرا کنه.
۴.۱.۲ ستون دوم: مقاومت در برابر بازآرایی
دومین ویژگی یک تست واحد خوب مقاومت در برابر بازآرایی است—یعنی اینکه تست بتونه بازآرایی کد اصلی رو تحمل کنه بدون اینکه خطا بده (fail بشه).
تعریف: بازآرایی یعنی تغییر کد موجود بدون دست زدن به رفتار قابل مشاهدهی اون. هدف معمولاً بهبود ویژگیهای غیرعملکردی کده: افزایش خوانایی و کاهش پیچیدگی. چند نمونهی بازآرایی میتونه تغییر نام یک متد یا استخراج بخشی از کد به یک کلاس جدید باشه.
این وضعیت رو تصور کن: یه قابلیت جدید توسعه دادی و همهچیز عالی کار میکنه. خود قابلیت وظیفهش رو درست انجام میده و همهی تستها هم پاس شدن. حالا تصمیم میگیری کد رو تمیز کنی. یه مقدار بازآرایی اینجا، یه تغییر کوچیک اونجا، و همهچیز حتی بهتر از قبل به نظر میرسه. به جز یه چیز—تستها fail شدن. دقیقتر نگاه میکنی ببینی دقیقاً چی رو با بازآرایی خراب کردی، اما معلوم میشه هیچ چیزی خراب نشده. قابلیت مثل قبل عالی کار میکنه. مشکل اینجاست که تستها طوری نوشته شدن که با هر تغییر در کد اصلی fail میشن. و این اتفاق میافته حتی اگر واقعاً هیچکدوم از قابلیتها خراب نشده باشه.
این وضعیت رو false positive میگن. false positive یعنی یه هشدار اشتباه؛ نتیجهای که نشون میده تست fail شده، در حالی که در واقعیت اون قابلیت درست کار میکنه. این اتفاق معمولاً وقتی میافته که کد رو بازآرایی میکنی—یعنی پیادهسازی رو تغییر میدی ولی رفتار قابل مشاهده همون میمونه. به همین دلیل اسم این ویژگی تست واحد خوب رو گذاشتن مقاومت در برابر بازآرایی.
برای ارزیابی اینکه یه تست چقدر در برابر بازآرایی مقاومه، باید ببینی چند تا false positive تولید میکنه. هرچی کمتر، بهتر.
چرا اینقدر روی false positive تأکید میشه؟ چون میتونه کل مجموعه تست رو نابود کنه. همونطور که از فصل ۱ یادت هست، هدف یونیت تست اینه که رشد پایدار پروژه رو ممکن کنه. مکانیزم این رشد پایدار اینه که تستها اجازه میدن قابلیتهای جدید اضافه کنی و مرتب بازآرایی انجام بدی بدون اینکه regression وارد بشه. اینجا دو مزیت مشخص وجود داره:
- تستها هشدار زودهنگام میدن وقتی یه قابلیت موجود رو خراب میکنی. به لطف این هشدارها میتونی مشکل رو خیلی قبلتر از رسیدن کد خراب به محیط تولید برطرف کنی، جایی که رفعش هزینهی خیلی بیشتری میطلبه.
- مطمئن میشی تغییرات کدت باعث regression نمیشن. بدون این اعتماد، خیلی بیشتر در بازآرایی مردد میشی و احتمال اینکه بذاری کدبیس به مرور خراب بشه زیاد میشه.
false positive هر دو مزیت رو خراب میکنه:
- وقتی تستها بیدلیل fail میشن، توانایی و انگیزهت برای واکنش به مشکلات کد کم میشه. کمکم به این خطاهای بیدلیل عادت میکنی و توجهت کمتر میشه. بعد از یه مدت حتی شروع میکنی خطاهای واقعی رو هم نادیده گرفتن و میذاری به محیط تولید برسن.
- از طرف دیگه، وقتی false positive زیاد باشه، کمکم اعتماد به مجموعه تست رو از دست میدی. دیگه بهش به چشم یه شبکهی ایمنی قابل اعتماد (Safety net) نگاه نمیکنی—این تصور با هشدارهای اشتباه خراب میشه. این بیاعتمادی باعث میشه کمتر بازآرایی کنی، چون سعی میکنی تغییرات کد رو به حداقل برسونی تا از regression جلوگیری کنی.
یه داستان از دل پروژهها
من یه بار روی پروژهای کار میکردم که تاریخچهی خاصی داشت. پروژه خیلی قدیمی نبود، شاید دو سه سال؛ ولی توی اون مدت مدیریت چند بار مسیر پروژه رو عوض کرد و توسعه هم مجبور شد همونطور تغییر جهت بده. وسط این تغییرات یه مشکل پیش اومد: کدبیس پر شد از تکههای کدی که دیگه کسی جرئت حذف یا بازآراییشون رو نداشت. شرکت دیگه به اون قابلیتها نیاز نداشت، اما بعضی بخشهاش توی قابلیتهای جدید استفاده میشد، پس نمیشد کامل از شر کدهای قدیمی خلاص شد.
پروژه پوشش تست خوبی داشت. ولی هر بار کسی میخواست قابلیتهای قدیمی رو بازآرایی کنه و بخشهای مورد استفاده رو از بقیه جدا کنه، تستها fail میشدن. و نه فقط تستهای قدیمی—اونها مدتها قبل غیرفعال شده بودن—بلکه تستهای جدید هم همینطور. بعضی از خطاها واقعی بودن، اما بیشترشون نه؛ بیشترشون false positive بودن.
اولش توسعهدهندهها سعی کردن با خطاهای تست کنار بیان. اما چون بیشترشون هشدارهای اشتباه بودن، اوضاع به جایی رسید که دیگه این خطاها رو نادیده گرفتن و تستهای fail شده رو غیرفعال کردن. نگرش غالب این بود: «اگه به خاطر اون تکه کد قدیمیه، تست رو غیرفعال کن؛ بعداً بهش سر میزنیم.»
یه مدت همهچیز خوب پیش رفت—تا اینکه یه باگ بزرگ وارد شد. یکی از تستها درست اون باگ رو شناسایی کرده بود، ولی کسی توجه نکرد؛ اون تست هم مثل بقیه غیرفعال شده بود. بعد از اون اتفاق، توسعهدهندهها دیگه کلاً دست به کدهای قدیمی نزدن.
این داستان نمونهی رایجی از بیشتر پروژههایی با تستهای شکنندهست. اولش توسعهدهندهها خطاهای تست رو جدی میگیرن و مطابقش عمل میکنن. اما بعد از یه مدت آدمها خسته میشن و کمکم شروع میکنن به نادیده گرفتنشون. در نهایت، لحظهای میرسه که یه عالمه باگ واقعی وارد محیط تولید میشه، چون توسعهدهندهها خطاها رو همراه با همهی false positiveها نادیده گرفتن.
واکنش درست به چنین وضعیتی این نیست که کلاً بازآرایی رو متوقف کنی. پاسخ درست اینه که مجموعه تست رو دوباره ارزیابی کنی و شروع کنی به کاهش شکنندگی اون. من این موضوع رو توی فصل ۷ توضیح میدم.
۴.۱.۳ چه چیزی باعث false positive میشود؟
خب، چه چیزی باعث false positive میشود؟ و چطور میتوان از آنها جلوگیری کرد؟
تعداد false positiveهایی که یک تست تولید میکند مستقیماً به نحوهی ساختار تست بستگی دارد. هرچه تست بیشتر به جزئیات پیادهسازی سیستم تحت تست (SUT) وابسته باشد، هشدارهای اشتباه بیشتری تولید میکند. تنها راه کاهش احتمال false positive اینه که تست رو از اون جزئیات پیادهسازی جدا کنی. باید مطمئن بشی تست نتیجهی نهاییای رو که SUT ارائه میدهد بررسی میکند: رفتار قابل مشاهده، نه مراحل داخلی برای رسیدن به آن. تستها باید از دید کاربر نهایی به بررسی SUT نگاه کنند و فقط خروجیای رو بررسی کنند که برای کاربر معنا دارد. هر چیز دیگری باید نادیده گرفته شود (بیشتر در فصل ۵ توضیح داده میشود).
بهترین روش برای ساختار یک تست اینه که اون تست داستانی دربارهی دامنهی مسئله تعریف کنه. اگر چنین تستی fail بشه، اون شکست یعنی بین داستان و رفتار واقعی برنامه یک تفاوتی وجود داره. این تنها نوع خطای تستیه که به درد میخوره—چون همیشه دقیق و بهجا هست و کمک میکنه سریع بفهمی مشکل کجاست. بقیهی خطاها فقط نویز هستن و توجهت رو از چیزهای مهم منحرف میکنن.
یه مثال ببین: کلاس MessageRenderer یک HTML تولید میکنه که شامل header، body و footer هست.
public class Message
{
public string Header { get; set; }
public string Body { get; set; }
public string Footer { get; set; }
}
public interface IRenderer
{
string Render(Message message);
}
public class MessageRenderer : IRenderer
{
public IReadOnlyList<IRenderer> SubRenderers { get; }
public MessageRenderer()
{
SubRenderers = new List<IRenderer>
{
new HeaderRenderer(),
new BodyRenderer(),
new FooterRenderer()
};
}
public string Render(Message message)
{
return SubRenderers
.Select(x => x.Render(message))
.Aggregate("", (str1, str2) => str1 + str2);
}
}کد ۴.۱
کلاس MessageRenderer چند تا زیرمجموعه داره که کار اصلی رو روی بخشهای مختلف پیام انجام میدن. بعد خروجی رو ترکیب میکنه و یه سند HTML میسازه. زیرمجموعهها متن خام رو با تگهای HTML هماهنگ میکنن. برای مثال:
public class BodyRenderer : IRenderer
{
public string Render(Message message)
{
return $"<b>{message.Body}</b>";
}
}چطور میشه کلاس MessageRenderer رو تست کرد؟
یکی از راهها اینه که الگوریتمی رو که این کلاس دنبال میکنه بررسی کنیم.
[Fact]
public void MessageRenderer_uses_correct_sub_renderers()
{
var sut = new MessageRenderer();
IReadOnlyList<IRenderer> renderers = sut.SubRenderers;
Assert.Equal(3, renderers.Count);
Assert.IsAssignableFrom<HeaderRenderer>(renderers[0]);
Assert.IsAssignableFrom<BodyRenderer>(renderers[1]);
Assert.IsAssignableFrom<FooterRenderer>(renderers[2]);
}کد ۴.۲
این تست بررسی میکنه که زیرمجموعهها همون نوعهای مورد انتظار باشن و به ترتیب درست قرار گرفته باشن، که در واقع فرض میکنه روش پردازش پیامها توسط MessageRenderer هم باید درست باشه. تست در نگاه اول خوب به نظر میاد، اما آیا واقعاً رفتار قابل مشاهدهی MessageRenderer رو بررسی میکنه؟
اگه زیرمجموعهها رو جابهجا کنی یا یکیشون رو با یه زیرمجموعه جدید جایگزین کنی چی؟ آیا این باعث باگ میشه؟
نه لزوماً. میتونی ترکیب زیرمجموعهها رو طوری تغییر بدی که خروجی HTML همون بمونه. مثلاً میتونی BodyRenderer رو با BoldRenderer جایگزین کنی که دقیقاً همون کار رو انجام میده. یا حتی میتونی همهی زیرمجموعهها رو حذف کنی و رندرینگ رو مستقیم داخل MessageRenderer پیادهسازی کنی.
با این حال، تست در هر کدوم از این تغییرات fail میشه، حتی وقتی نتیجهی نهایی تغییر نکرده باشه. دلیلش اینه که تست به جزئیات پیادهسازی SUT وابستهست، نه به خروجیای که SUT تولید میکنه. این تست الگوریتم رو بررسی میکنه و انتظار داره یک پیادهسازی خاص رو ببینه، بدون اینکه به پیادهسازیهای جایگزین که به همون اندازه درست هستن توجهی داشته باشه.
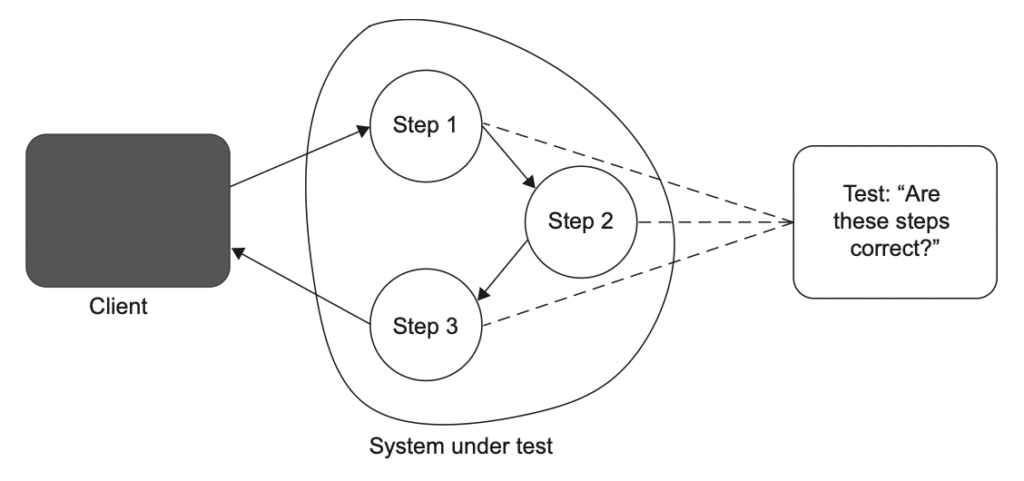
هر بازآرایی اساسی در کلاس MessageRenderer باعث میشه تست fail بشه.
یادت باشه، بازآرایی یعنی تغییر پیادهسازی بدون اینکه رفتار قابل مشاهده تحت تأثیر قرار بگیره. و دقیقاً به همین دلیله که تست به جزئیات پیادهسازی حساسه، هر بار این جزئیات رو تغییر بدی، تست قرمز میشه.
بنابراین تستهایی که به جزئیات پیادهسازی SUT وابسته هستند، در برابر بازآرایی مقاوم نیستند.
چنین تستهایی همهی ضعفهایی رو که قبلاً توضیح دادم نشون میدن:
- هشدار زودهنگام در صورت بروز regression نمیدن—چون این هشدارها بیارتباط هستن و نادیده گرفته میشن.
- توانایی و تمایل به بازآرایی رو محدود میکنن. جای تعجب نیست—چه کسی دوست داره بازآرایی کنه وقتی تستها نمیتونن درست تشخیص بدن که کجا باگ وجود داره؟
لیست بعدی بدترین نمونهی شکنندگی در تستها رو نشون میده که من تا حالا دیدم؛ جایی که تست کد منبع کلاس MessageRenderer رو میخونه و اون رو با پیادهسازی «درست» مقایسه میکنه.
[Fact]
public void MessageRenderer_is_implemented_correctly()
{
string sourceCode = File.ReadAllText(@"[path]\MessageRenderer.cs");
Assert.Equal(@"
public class MessageRenderer : IRenderer
{
public IReadOnlyList<IRenderer> SubRenderers { get; }
public MessageRenderer()
{
SubRenderers = new List<IRenderer>
{
new HeaderRenderer(),
new BodyRenderer(),
new FooterRenderer()
};
}
}", sourceCode);
public string Render(Message message) { /* ... */ }
}کد ۴.۳
البته این تست واقعاً بیمعنیه؛ با کوچکترین تغییری در کلاس MessageRenderer شکست میخوره. در اصل خیلی فرق زیادی با تست قبلی نداره. هر دو روی یک پیادهسازی خاص گیر میکنن و کاری به رفتار قابل مشاهدهی سیستم ندارن. برای همین هم هر بار که پیادهسازی تغییر کنه، تست قرمز میشه. البته باید گفت تستی که در کد ۴.۳ هست خیلی شکنندهتر از تست کد ۴.۲ هست.
۴.۱.۴ هدف گرفتن نتیجهی نهایی به جای جزئیات پیادهسازی
همونطور که قبلاً گفتم، تنها راه برای جلوگیری از شکنندگی تستها و بالا بردن مقاومتشون در برابر بازآرایی اینه که اونها رو از جزئیات پیادهسازی جدا کنیم. یعنی تا حد ممکن فاصله بین تست و سازوکار درونی کد رو حفظ کنیم و به جای اون، نتیجهی نهایی رو بررسی کنیم.
بیاییم همین کار رو انجام بدیم: تست کد ۴.۲ رو بازآرایی کنیم تا خیلی کمتر شکننده باشه.
اول باید از خودمون بپرسیم: خروجی نهایی MessageRenderer چیه؟ جوابش واضحه—نمایش HTML یک پیام. این تنها چیزیه که منطقیه بررسی بشه، چون تنها نتیجهی قابل مشاهدهایه که این کلاس تولید میکنه. تا وقتی این HTML ثابت بمونه، دیگه مهم نیست دقیقاً چطور ساخته شده. جزئیات پیادهسازی در اینجا بیاهمیت هستن.
کد زیر نسخهی جدید تست رو نشون میده.
[Fact]
public void Rendering_a_message()
{
var sut = new MessageRenderer();
var message = new Message
{
Header = "h",
Body = "b",
Footer = "f"
};
string html = sut.Render(message);
Assert.Equal("<h1>h</h1><b>b</b><i>f</i>", html);
}کد ۴.۴
این تست با MessageRenderer مثل یک جعبهسیاه رفتار میکنه و فقط به رفتار قابل مشاهدهی اون اهمیت میده. نتیجه اینه که تست خیلی مقاومتر در برابر بازآرایی میشه—دیگه مهم نیست چه تغییراتی در SUT انجام بدی، تا وقتی خروجی HTML همون باشه، تست سبز میمونه (شکل ۴.۲).
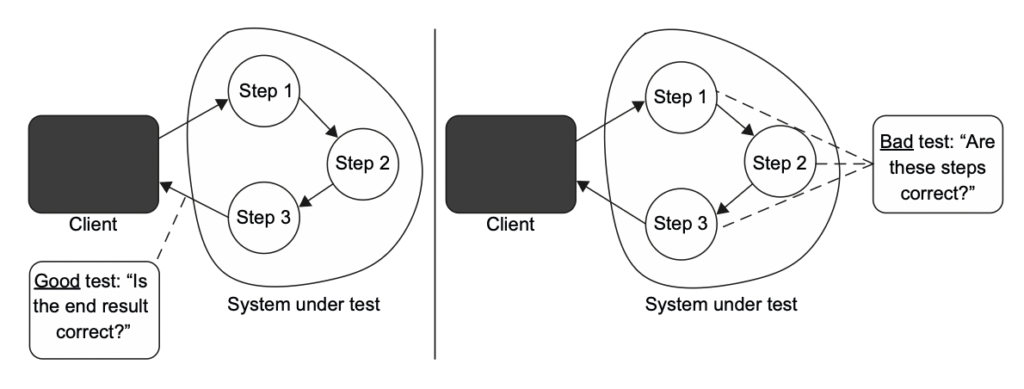
بهبود چشمگیری که این تست نسبت به نسخهی قبلی داره واضحه. خودش رو با نیازهای کسبوکار هماهنگ میکنه چون تنها نتیجهای رو بررسی میکنه که برای کاربر نهایی معنا داره—اینکه پیام چطور در مرورگر نمایش داده میشه. شکست چنین تستی همیشه دقیق و بهجا است: نشون میده رفتار برنامه تغییر کرده و ممکنه روی مشتری اثر بذاره، پس باید توجه توسعهدهنده رو جلب کنه. این تست تعداد خیلی کمی خطای مثبت کاذب تولید میکنه، اگر اصلاً تولید کنه.
چرا گفتیم «کم» و نه «هیچ»؟ چون هنوز ممکنه تغییراتی در MessageRenderer باعث شکستن تست بشه. مثلاً اگه پارامتر جدیدی به متد Render() اضافه کنی، خطای کامپایل رخ میده. از نظر فنی این هم یک خطای مثبت کاذب حساب میشه، چون تست به خاطر تغییر در رفتار برنامه شکست نخورده.
ولی این نوع مثبت کاذب خیلی راحت برطرف میشه. کافیه طبق راهنمای کامپایلر عمل کنی و پارامتر جدید رو به همهی تستهایی که Render() رو صدا میزنن اضافه کنی. مشکل اصلی اون مثبتهای کاذبی هستن که به خطای کامپایل منجر نمیشن. اینها سختترین نوع هستن چون ظاهراً شبیه یک باگ واقعی به نظر میان و زمان زیادی برای بررسی لازم دارن.
۴.۲ ارتباط درونی بین دو ویژگی اول
همانطور که قبلاً گفتم، بین دو ستون اصلی یک تست واحد خوب—محافظت در برابر regression و مقاومت در برابر بازآرایی—یک ارتباط درونی وجود دارد. هر دو به دقت مجموعه تست کمک میکنند، هرچند از زاویههای متفاوت. این دو ویژگی همچنین در طول زمان تأثیر متفاوتی روی پروژه میگذارند: در حالی که داشتن محافظت خوب در برابر regression خیلی زود بعد از شروع پروژه اهمیت پیدا میکند، نیاز به مقاومت در برابر بازآرایی فوری نیست.
در این بخش دربارهی موارد زیر صحبت میکنم:
- بیشینه کردن دقت تستها
- اهمیت مثبتهای کاذب و منفیهای کاذب
۴.۲.۱ بیشینه کردن دقت تستها
بیاییم کمی عقب بریم و تصویر کلی نتایج تست رو ببینیم. وقتی صحبت از درستی کد و نتایج تست میشه، چهار حالت ممکن وجود داره (همونطور که در شکل ۴.۳ نشون داده شده). تست میتونه پاس بشه یا شکست بخوره (سطرهای جدول). و خودِ قابلیت میتونه درست باشه یا خراب (ستونهای جدول).
وقتی تست پاس میشه و قابلیت همونطور که باید کار میکنه، این یک استنتاج درست محسوب میشه: تست وضعیت سیستم رو درست تشخیص داده (هیچ باگی وجود نداره). اصطلاح دیگه برای این ترکیبِ قابلیت درست و تست پاسشده، منفیِ درست هست.
به همین شکل، وقتی قابلیت خراب باشه و تست شکست بخوره، باز هم یک استنتاج درست داریم. چون انتظار داریم وقتی قابلیت درست کار نمیکنه، تست fail بشه. این دقیقاً هدف تست واحده. اصطلاح مربوط به این حالت، مثبتِ درست هست.
اما وقتی تست خطا رو نمیگیره، مشکل پیش میاد. این حالت در بخش بالا-راست جدول قرار میگیره و بهش منفیِ کاذب میگن. و این همون چیزیه که ویژگی اول یک تست خوب—محافظت در برابر regression—کمک میکنه ازش دوری کنیم. تستهایی که محافظت خوبی در برابر regression دارن، تعداد منفیهای کاذب (خطاهای نوع دوم) رو به حداقل میرسونن.
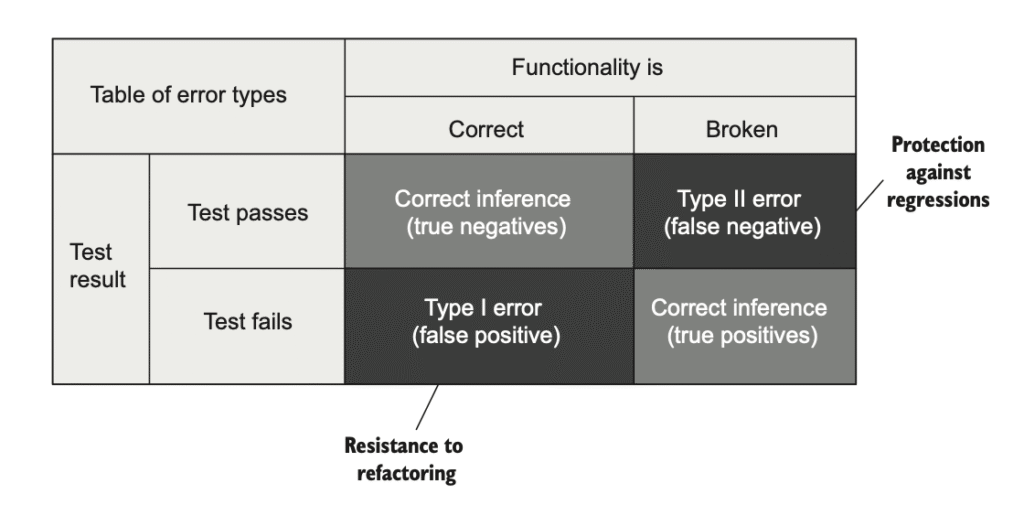
از طرف دیگه، یک وضعیت متقارن هم وجود داره: وقتی قابلیت درست کار میکنه اما تست همچنان شکست میخوره. این همون مثبت کاذب یا هشدار اشتباهه. و این دقیقاً چیزیه که ویژگی دوم—مقاومت در برابر بازآرایی— کمکتون میکنه.
تمام این اصطلاحها (مثل مثبت کاذب، خطای نوع اول و غیره) ریشه در آمار دارن، اما میشه اونها رو برای تحلیل مجموعه تستها هم به کار برد. بهترین راه برای درک این مفاهیم اینه که به یک تست آنفلوآنزا فکر کنیم. تست آنفلوآنزا وقتی مثبت میشه که فرد واقعاً آنفلوآنزا داشته باشه. اصطلاح «مثبت» کمی گیجکنندهست، چون داشتن آنفلوآنزا چیز خوبی نیست. اما تست کل وضعیت رو ارزیابی نمیکنه. در زمینهی تست، «مثبت» یعنی مجموعهای از شرایط برقرار شده. این شرایط همون چیزیه که سازندگان تست تعیین کردن تا بهش واکنش نشون بده. در این مثال خاص، وجود آنفلوآنزا اون شرایطه. برعکس، نبود آنفلوآنزا باعث میشه تست منفی باشه.
حالا وقتی میخوای دقت یک تست آنفلوآنزا رو بسنجی، اصطلاحهایی مثل مثبت کاذب یا منفی کاذب مطرح میشن. احتمال رخ دادن این خطاها نشون میده تست چقدر خوبه: هرچی این احتمال کمتر باشه، تست دقیقتره.
این همون چیزیه که دو ستون اول یک تست واحد خوب بهش مربوط میشن. محافظت در برابر regression و مقاومت در برابر بازآرایی هدفشون بیشینه کردن دقت مجموعه تستهاست.
خودِ معیار دقت از دو بخش تشکیل میشه:
- اینکه تست چقدر خوب وجود باگ رو نشون میده (نبود منفیهای کاذب، حوزهی محافظت در برابر regression)
- اینکه تست چقدر خوب نبود باگ رو نشون میده (نبود مثبتهای کاذب، حوزهی مقاومت در برابر بازآرایی)
راه دیگهای برای نگاه کردن به مثبتهای کاذب و منفیهای کاذب اینه که اونها رو به شکل نسبت سیگنال به نویز در نظر بگیریم. همونطور که فرمول شکل ۴.۴ نشون میده، دو راه برای بهتر کردن دقت تست وجود داره:
- اولی بالا بردن صورت، یعنی سیگنال: اینکه تست توانایی بیشتری در پیدا کردن regression داشته باشه.
- دومی پایین آوردن مخرج، یعنی نویز: اینکه تست کمتر هشدار اشتباه بده.
هر دو بخش خیلی مهم هستن. تستی که هیچ باگی رو پیدا نمیکنه—حتی اگر هشدار اشتباه هم نده—عملاً بیفایدهست. از طرف دیگه، وقتی تست نویز زیادی تولید کنه، دقتش صفر میشه—حتی اگر همهی باگهای کد رو پیدا کنه. چون نتیجههای درست وسط انبوه اطلاعات بیربط گم میشن.
دقت تست = سیگنال (تعداد باگهای پیدا شده) ÷ نویز (تعداد هشدارهای اشتباه داده شده)

۴.۲.۲ اهمیت مثبتهای کاذب و منفیهای کاذب: پویاییها
در کوتاهمدت، مثبتهای کاذب به اندازهی منفیهای کاذب مشکلساز نیستند. در ابتدای یک پروژه، دریافت یک هشدار اشتباه آنقدر جدی نیست، در مقایسه با اینکه هیچ هشداری دریافت نشود و خطر ورود یک باگ به محیط تولید وجود داشته باشد. اما با رشد پروژه، مثبتهای کاذب بهتدریج اثر بزرگتری روی مجموعه تستها میگذارند (شکل ۴.۵).
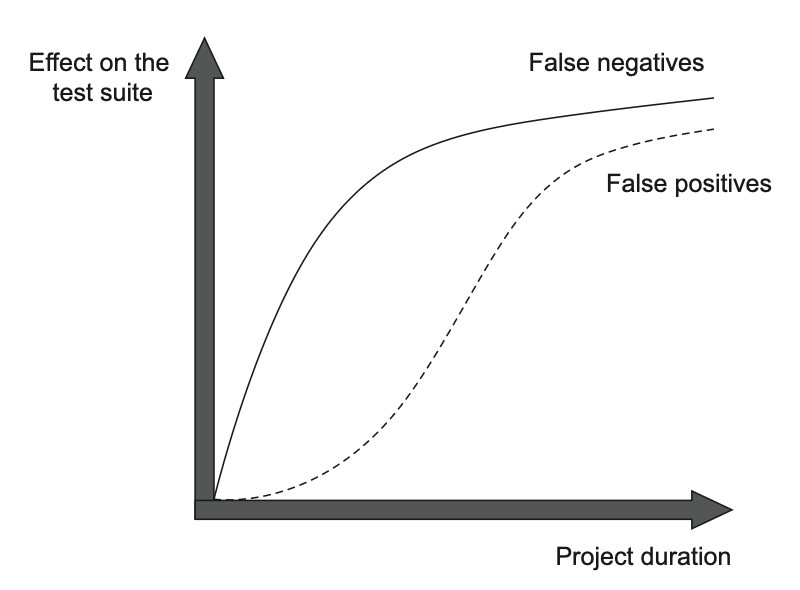
چرا مثبتهای کاذب در ابتدا اونقدر مهم نیستن؟ چون اهمیت بازآرایی هم فوری نیست و بهمرور زمان بیشتر میشه. در شروع پروژه، نیاز چندانی به پاکسازی کد وجود نداره. کدی که تازه نوشته شده معمولاً تمیز و بینقصه. علاوه بر این، هنوز توی ذهن تازهست، بنابراین حتی اگر تستها هشدار اشتباه بدن، باز هم میتونی راحت بازآراییش کنی.
اما با گذشت زمان، کدبیس فرسوده میشه. پیچیدهتر و بینظمتر میشه. بنابراین باید شروع کنی به بازآراییهای منظم تا جلوی این روند رو بگیری. در غیر این صورت، هزینهی اضافه کردن قابلیتهای جدید در نهایت خیلی زیاد میشه.
هرچی نیاز به بازآرایی بیشتر بشه، اهمیت مقاومت در برابر بازآرایی در تستها هم بیشتر میشه. همونطور که قبلاً گفتم، وقتی تستها مدام «گرگ» صدا میکنن و هشدار باگهایی رو میدن که وجود ندارن، دیگه نمیتونی بازآرایی کنی. خیلی زود اعتماد به این تستها رو از دست میدی و دیگه بهعنوان منبع بازخورد قابل اعتماد بهشون نگاه نمیکنی.
با وجود اینکه محافظت در برابر مثبتهای کاذب—بهخصوص در مراحل بعدی پروژه—خیلی مهمه، تعداد کمی از توسعهدهندهها این موضوع رو اینطور میبینن. بیشتر افراد فقط روی بهبود ویژگی اول یک تست خوب تمرکز میکنن: محافظت در برابر regression. اما این بهتنهایی کافی نیست تا یک مجموعه تست دقیق و ارزشمند بسازه که بتونه رشد پروژه رو پایدار نگه داره.
دلیلش هم واضحه: خیلی کم پیش میاد پروژهها به اون مراحل پایانی برسن، چون اغلب کوچک هستن و توسعه قبل از بزرگ شدن پروژه تموم میشه. بنابراین توسعهدهندهها بیشتر با مشکل باگهای نادیده مواجه میشن تا هشدارهای اشتباهی که پروژه رو پر کنه و بازآرایی رو مختل کنه. و به همین خاطر، بهینهسازیهاشون رو بر اساس همین مشکل انجام میدن. با این حال، اگر روی یک پروژهی متوسط یا بزرگ کار میکنی، باید به هر دو توجه برابر داشته باشی: هم منفیهای کاذب (باگهای نادیده) و هم مثبتهای کاذب (هشدارهای اشتباه).
۴.۳ ستون سوم و چهارم: بازخورد سریع و قابلیت نگهداری
در این بخش، دربارهی دو ستون باقیماندهی یک تست واحد خوب صحبت میکنم:
- بازخورد سریع
- قابلیت نگهداری
همونطور که از فصل ۲ یادت هست، بازخورد سریع یکی از ویژگیهای اساسی تست واحده. هرچی تستها سریعتر باشن، میتونی تعداد بیشتری از اونها رو در مجموعه داشته باشی و دفعات بیشتری اجراشون کنی.
وقتی تستها سریع اجرا میشن، چرخهی بازخورد بهشدت کوتاه میشه، تا جایی که تستها تقریباً همون لحظهای که کد رو خراب میکنی بهت هشدار میدن. این باعث میشه هزینهی رفع اون باگها تقریباً به صفر برسه. از طرف دیگه، تستهای کند بازخورد رو به تأخیر میندازن و ممکنه مدت زمانی که باگها نادیده میمونن طولانیتر بشه، و در نتیجه هزینهی رفعشون بالا بره. دلیلش اینه که تستهای کند باعث میشن کمتر سراغ اجرای مکرر تستها بری و همین باعث میشه زمان بیشتری رو در مسیر اشتباه تلف کنی.
در نهایت، ستون چهارم تستهای واحد خوب، معیار قابلیت نگهداری است که هزینههای نگهداری را ارزیابی میکند. این معیار از دو بخش اصلی تشکیل میشود:
- سختی درک تست — این بخش به اندازهی تست مربوط میشود. هرچه خطوط کد تست کمتر باشه، خوانایی تست بیشتره. همچنین تغییر یک تست کوچک در صورت نیاز راحتتره. البته این به شرطیه که کد تست رو بهطور مصنوعی فقط برای کم کردن تعداد خطوط، فشرده نکنی. کیفیت کد تست به اندازهی کد تولیدی اهمیت داره. در نوشتن تستها میانبر نزن؛ کد تست رو مثل یک شهروند درجهیک در نظر بگیر.
- سختی اجرای تست — اگر تست با وابستگیهای خارج از فرآیند کار کنه، باید زمان صرف کنی تا اون وابستگیها رو عملیاتی نگه داری: راهاندازی دوبارهی سرور دیتابیس، حل مشکلات اتصال شبکه و موارد مشابه.
۴.۴ در جستجوی یک تست ایدهآل
اینجا دوباره چهار ویژگی یک تست واحد خوب رو مرور میکنیم:
- محافظت در برابر regression
- مقاومت در برابر بازآرایی
- بازخورد سریع
- قابلیت نگهداری
این چهار ویژگی وقتی در هم ضرب بشن، ارزش یک تست رو تعیین میکنن. و منظور از ضرب، معنای ریاضی اون هست؛ یعنی اگر تست در یکی از ویژگیها نمرهی صفر بگیره، ارزشش هم صفر میشه:
ارزش تخمینی = [۰..۱] × [۰..۱] × [۰..۱] × [۰..۱]
نکته: برای اینکه تست ارزشمند باشه، باید در هر چهار دسته حداقل امتیازی کسب کنه.
البته، اندازهگیری دقیق این ویژگیها غیرممکنه. هیچ ابزار تحلیل کدی وجود نداره که بتونی تست رو بهش وصل کنی و عدد دقیق بگیری. اما همچنان میتونی تست رو بهطور نسبتاً دقیق ارزیابی کنی تا ببینی جایگاهش نسبت به این چهار ویژگی کجاست. این ارزیابی در نهایت ارزش تخمینی تست رو بهت میده، که میتونی ازش برای تصمیمگیری در مورد نگه داشتن یا حذف تست از مجموعه استفاده کنی.
یادت باشه، همهی کدها—از جمله کد تست—یک بدهی محسوب میشن. پس باید آستانهی نسبتاً بالایی برای حداقل ارزش مورد نیاز تعیین کنی و فقط تستهایی رو در مجموعه نگه داری که این آستانه رو برآورده کنن. تعداد کمی تست با ارزش بالا خیلی بهتر از تعداد زیادی تست متوسط میتونن رشد پروژه رو پایدار نگه دارن.
بهزودی چند مثال نشون میدم. فعلاً بیایم بررسی کنیم که آیا میشه یک تست ایدهآل ساخت یا نه.
۴.۴.۱ آیا میتوان یک تست ایدهآل ساخت؟
یک تست ایدهآل تستیه که در هر چهار ویژگی بیشترین امتیاز رو بگیره. اگر حداقل و حداکثر رو برای هر ویژگی ۰ و ۱ در نظر بگیریم، تست ایدهآل باید در همهی اونها نمرهی ۱ بگیره.
متأسفانه ساخت چنین تستی غیرممکنه. دلیلش اینه که سه ویژگی اول—محافظت در برابر regression، مقاومت در برابر بازآرایی، و بازخورد سریع—با هم ناسازگارن. نمیشه همهی اونها رو به حداکثر رسوند؛ باید یکی رو قربانی کنی تا دو تای دیگه رو به حداکثر برسونی.
علاوه بر این، به خاطر اصل ضرب (همون محاسبهی ارزش تخمینی در بخش قبلی)، حفظ تعادل حتی سختتر میشه. نمیتونی یکی از ویژگیها رو کاملاً کنار بذاری و فقط روی بقیه تمرکز کنی. همونطور که قبلاً گفتم، تستی که در یکی از چهار دسته نمرهی صفر بگیره، بیارزشه. بنابراین باید این ویژگیها رو طوری بیشینه کنی که هیچکدوم بیش از حد تضعیف نشه.
بیایم چند مثال از تستهایی ببینیم که تلاش میکنن دو ویژگی از سه ویژگی رو به حداکثر برسونن و سومی رو قربانی کنن، و در نتیجه ارزشی نزدیک به صفر پیدا میکنن.
۴.۴.۲ حالت افراطی شماره ۱: تستهای End-to-End
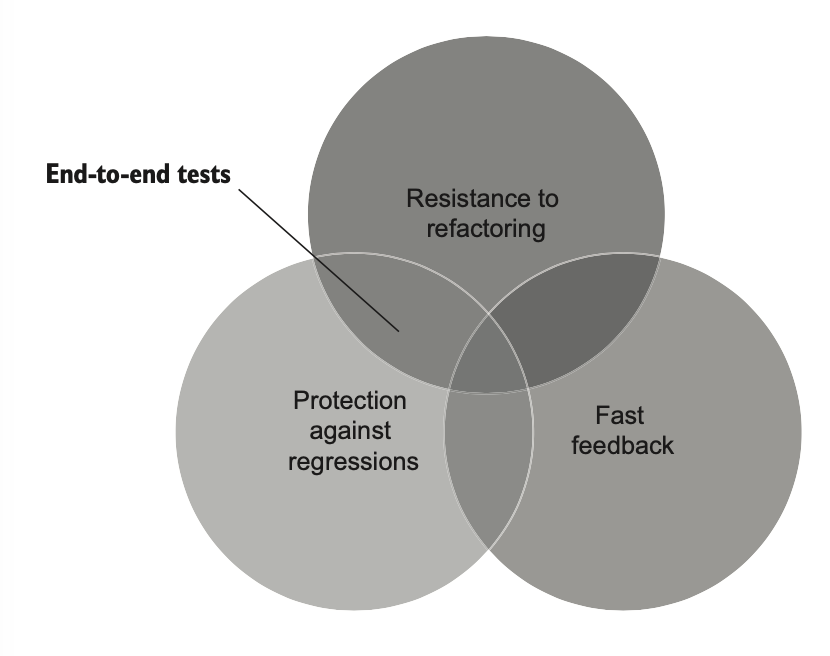
اولین مثال، تستهای End-to-End هستن. همونطور که از فصل ۲ یادت هست، این تستها سیستم رو از دید کاربر نهایی بررسی میکنن. معمولاً همهی اجزای سیستم رو طی میکنن، از رابط کاربری گرفته تا پایگاه داده و برنامههای خارجی.
چون تستهای End-to-End حجم زیادی از کد رو اجرا میکنن، بهترین محافظت رو در برابر regression فراهم میکنن. در واقع، بین همهی انواع تستها، این تستها بیشترین میزان کد رو پوشش میدن—هم کدی که خودت نوشتی و هم کدی که ننوشتی ولی در پروژه استفاده میکنی، مثل کتابخانهها، فریمورکها و برنامههای شخص ثالث.
این تستها همچنین در برابر مثبتهای کاذب مصون هستن و بنابراین مقاومت خوبی در برابر بازآرایی دارن. بازآرایی، اگر درست انجام بشه، رفتار قابل مشاهدهی سیستم رو تغییر نمیده و در نتیجه روی تستهای End-to-End اثری نداره. این یکی دیگه از مزیتهای این تستهاست: هیچ پیادهسازی خاصی رو تحمیل نمیکنن. تنها چیزی که بررسی میکنن اینه که یک قابلیت از دید کاربر نهایی چطور رفتار میکنه. به همین دلیل، تا حد ممکن از جزئیات پیادهسازی فاصله دارن.
اما با وجود این مزایا، تستهای End-to-End یک ایراد بزرگ دارن: کند هستن. هر سیستمی که فقط به این تستها تکیه کنه، برای گرفتن بازخورد سریع دچار مشکل میشه. و این برای خیلی از تیمهای توسعه یک مانع جدی محسوب میشه. به همین دلیل، عملاً غیرممکنه که کل کدبیس رو فقط با تستهای End-to-End پوشش بدی.
شکل ۴.۶ نشون میده که تستهای End-to-End نسبت به سه معیار اول تست واحد در چه جایگاهی قرار دارن. این تستها محافظت عالی در برابر خطاهای regression و مثبتهای کاذب فراهم میکنن، اما سرعت ندارن.
۴.۴.۲ حالت افراطی شماره ۲: تستهای ساده (Trivial Tests)
مثال دیگه از بیشینه کردن دو ویژگی از سه ویژگی به قیمت قربانی کردن سومی، تستهای ساده هستن. این تستها بخش خیلی سادهای از کد رو پوشش میدن—چیزی که احتمال خراب شدنش خیلی کمه چون بیش از حد پیشپاافتادهست، همونطور که در کد بعدی نشون داده شده.
public class User
{
public string Name { get; set; } // یکخطی مثل این معمولاً بعیده باگی داشته باشن.
}
[Fact]
public void Test()
{
var sut = new User();
sut.Name = "John Smith";
Assert.Equal("John Smith", sut.Name);
}کد ۴.۵
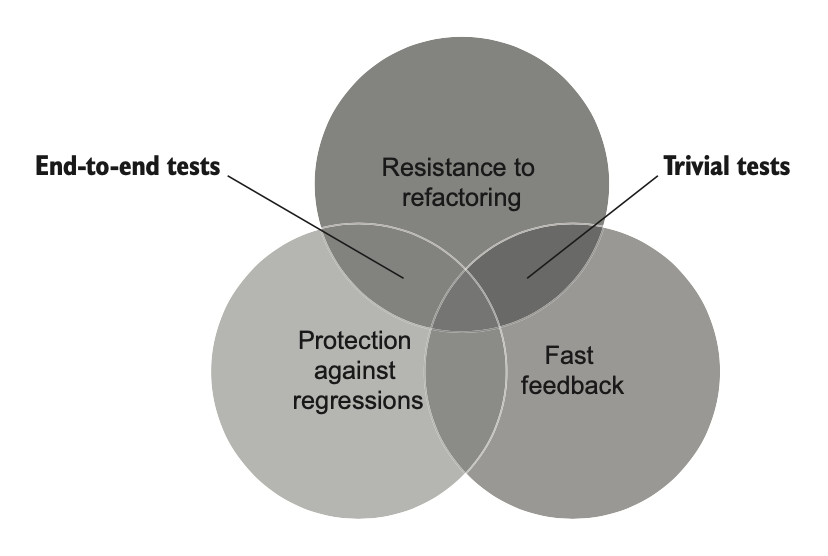
برخلاف تستهای End-to-End، تستهای ساده بازخورد سریع فراهم میکنن—خیلی سریع اجرا میشن. همچنین احتمال کمی برای تولید مثبت کاذب دارن، بنابراین در برابر بازآرایی مقاومت خوبی دارن. با این حال، تستهای ساده بهندرت میتونن regression رو آشکار کنن، چون در کد زیربنایی فضای زیادی برای خطا وجود نداره.
وقتی تستهای ساده به حالت افراطی برسن، تبدیل به تستهای تکراری (Tautology Tests) میشن. این تستها عملاً هیچ چیزی رو آزمایش نمیکنن، چون طوری تنظیم شدن که همیشه موفق بشن یا شامل assertionهایی باشن که بیمعنی هستن.
۴.۴.۲ حالت افراطی شماره ۳: تستهای شکننده (Brittle Tests)
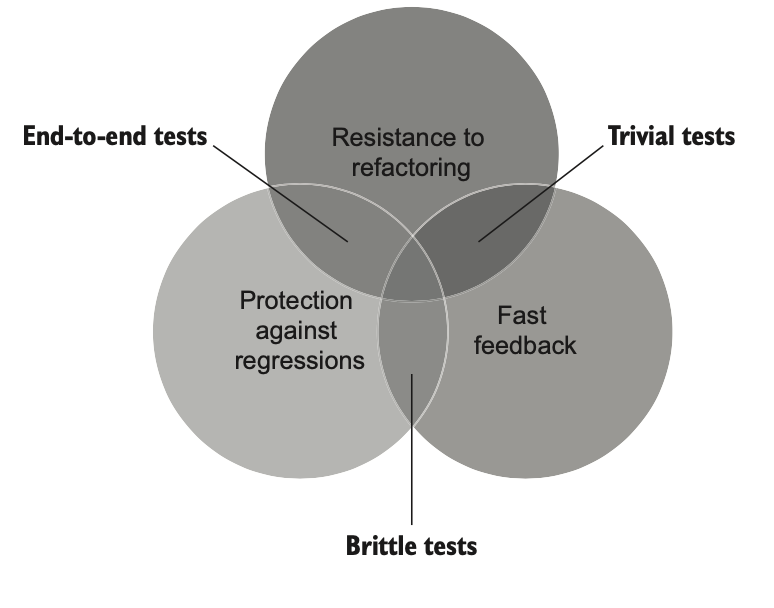
به همین شکل، نوشتن تستی که سریع اجرا بشه و شانس خوبی برای پیدا کردن regression داشته باشه اما همراه با تعداد زیادی مثبت کاذب باشه، کار راحتیه. چنین تستی رو تست شکننده میگن: این تست در برابر بازآرایی مقاوم نیست و فارغ از اینکه عملکرد اصلی خراب شده یا نه، قرمز میشه.
قبلاً در کد ۴.۲ یک نمونه از تست شکننده رو دیدی. اینجا یک نمونهی دیگه آورده شده.
public class UserRepository
{
public User GetById(int id)
{
/* ... */
}
public string LastExecutedSqlStatement { get; set; }
}
[Fact]
public void GetById_executes_correct_SQL_code()
{
var sut = new UserRepository();
User user = sut.GetById(5);
Assert.Equal(
"SELECT * FROM dbo.[User] WHERE UserID = 5",
sut.LastExecutedSqlStatement);
}کد ۴.۶
این تست مطمئن میشه که کلاس UserRepository هنگام واکشی یک کاربر از پایگاه داده، یک دستور SQL درست تولید کنه. آیا این تست میتونه باگ رو پیدا کنه؟ بله. مثلاً اگر توسعهدهنده در تولید SQL اشتباه کنه و بهجای UserID از ID استفاده کنه، تست با شکست به این موضوع اشاره میکنه.
اما آیا این تست مقاومت خوبی در برابر بازآرایی داره؟ قطعاً نه. چون تغییرات مختلفی در اسکریپت SQL میتونن همون نتیجه رو بدن، مثل:
SELECT * FROM dbo.[User] WHERE UserID = 5
SELECT * FROM dbo.User WHERE UserID = 5
SELECT UserID, Name, Email FROM dbo.[User] WHERE UserID = 5
SELECT * FROM dbo.[User] WHERE UserID = @UserIDتست در کد ۴.۶ با هرکدوم از این تغییرات قرمز میشه، حتی اگر عملکرد اصلی همچنان درست باشه. این دوباره مثالی از وابستگی تست به جزئیات داخلی SUT هست. تست روی چگونگی تمرکز کرده نه چیستی، و همین باعث میشه جزئیات پیادهسازی در تست تثبیت بشن و جلوی بازآراییهای بعدی گرفته بشه.
شکل ۴.۸ نشون میده که تستهای شکننده در دستهی سوم قرار میگیرن: این تستها سریع اجرا میشن و محافظت خوبی در برابر regression دارن، اما مقاومت کمی در برابر بازآرایی نشون میدن.
۴.۴.۵ در جستجوی یک تست ایدهآل: نتایج
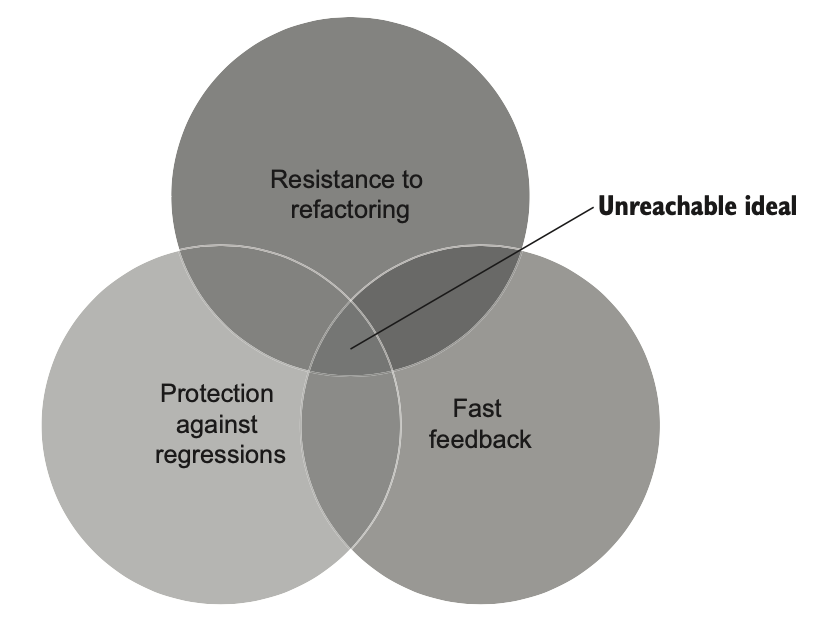
سه ویژگی اول یک تست واحد خوب (محافظت در برابر regression، مقاومت در برابر بازآرایی، و بازخورد سریع) با هم ناسازگار هستن. درسته که خیلی راحت میشه تستی نوشت که دو تا از این سه ویژگی رو به حداکثر برسونه، اما این کار همیشه به قیمت قربانی کردن ویژگی سوم انجام میشه. با این حال، چنین تستی به خاطر قانون ضرب، ارزشی نزدیک به صفر خواهد داشت.
متأسفانه، ساخت یک تست ایدهآل که در هر سه ویژگی نمرهی کامل بگیره غیرممکنه (شکل ۴.۹).
ویژگی چهارم، یعنی قابلیت نگهداری، با سه ویژگی اول ارتباط مستقیمی نداره—بهجز در مورد تستهای End-to-End. تستهای End-to-End معمولاً بزرگتر هستن چون لازمه همهی وابستگیهایی که بهشون دسترسی دارن راهاندازی بشه. همچنین نیازمند تلاش اضافه برای عملیاتی نگه داشتن اون وابستگیها هستن. به همین دلیل، هزینهی نگهداری این تستها معمولاً بالاتر از بقیهست.
حفظ تعادل بین ویژگیهای یک تست خوب کار سختیه. هیچ تستی نمیتونه در هر سه ویژگی اول نمرهی کامل بگیره، و در عین حال باید مراقب باشی که از نظر قابلیت نگهداری هم تست کوتاه و ساده باقی بمونه. بنابراین، باید معاملهها (trade-offs) رو بپذیری.
نکتهی مهم اینه که این معاملهها باید طوری انجام بشن که هیچ ویژگی به صفر نرسه. قربانی کردن باید جزئی و راهبردی باشه، نه کامل.
این قربانیها باید چه شکلی باشن؟ به خاطر ناسازگاری بین سه ویژگی محافظت در برابر regression، مقاومت در برابر بازآرایی، و بازخورد سریع، ممکنه فکر کنی بهترین راهبرد اینه که کمی از هرکدوم کوتاه بیای تا برای همهشون جا باز بشه.
اما در واقعیت، مقاومت در برابر بازآرایی غیرقابل مذاکرهست. باید تا جای ممکن این ویژگی رو به دست بیاری، به شرطی که تستها همچنان بهاندازهی کافی سریع بمونن و فقط به تستهای End-to-End متکی نباشی.
بنابراین معاملهی اصلی بین این دو ویژگی شکل میگیره:
- اینکه تستها چقدر در پیدا کردن باگها خوب عمل کنن (محافظت در برابر regression)
- و اینکه چقدر سریع این کار رو انجام بدن (بازخورد سریع)
میتونی این انتخاب رو مثل یک اسلایدر در نظر بگیری که آزادانه بین محافظت در برابر regression و بازخورد سریع حرکت میکنه. هرچه در یکی بیشتر به دست بیاری، در دیگری بیشتر از دست میدی (شکل ۴.۱۰).
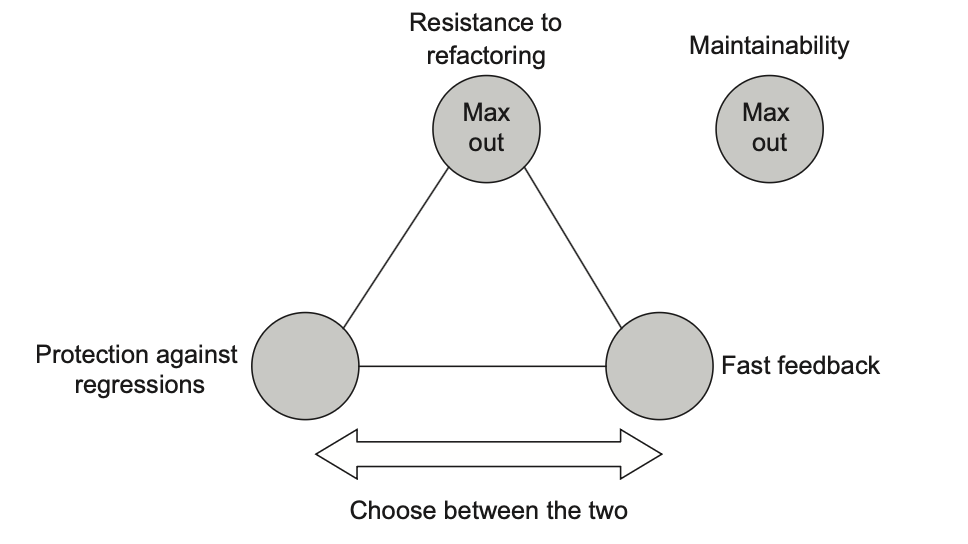
دلیل اینکه مقاومت در برابر بازآرایی غیرقابل مذاکرهست اینه که داشتن این ویژگی تقریباً یک انتخاب دودویی محسوب میشه: تست یا مقاومت در برابر بازآرایی داره یا نداره. حالتهای میانی زیادی بین این دو وجود نداره. بنابراین نمیتونی فقط کمی از مقاومت در برابر بازآرایی کوتاه بیای چون در این صورت کاملاً از دستش میدی.
از طرف دیگه، معیارهای محافظت در برابر regression و بازخورد سریع انعطافپذیرتر هستن. در بخش بعدی میبینی چه نوع معاملههایی ممکنه پیش بیاد وقتی یکی رو به نفع دیگری انتخاب کنی.
💡 نکته: از بین بردن شکنندگی (مثبتهای کاذب) در تستها اولین اولویت در مسیر ساخت یک مجموعه تست مقاومه.
قضیهی CAP
معاملهی بین سه ویژگی اول یک تست واحد خوب شبیه به قضیهی CAP هست. قضیهی CAP بیان میکنه که برای یک پایگاه داده توزیعشده، غیرممکنه که همزمان بیش از دو مورد از سه تضمین زیر برقرار باشه:
- یکپارچگی (Consistency): هر خواندن یا آخرین مقدار نوشتهشده رو دریافت میکنه یا با خطا مواجه میشه.
- دسترسپذیری (Availability): هر درخواست پاسخی دریافت میکنه (بهجز در زمانهایی که همهی گرههای سیستم دچار قطعی بشن).
- تحمل پارتیشن (Partition tolerance): سیستم علیرغم تقسیمبندی شبکه (قطع ارتباط بین گرههای شبکه) همچنان به کار خودش ادامه میده.
شباهت بین تستهای واحد و قضیهی CAP دو جنبه داره:
- اول، معاملهی دو-از-سه وجود داره.
- دوم، مؤلفهی تحمل پارتیشن در سیستمهای توزیعشدهی بزرگ غیرقابل مذاکرهست. یک اپلیکیشن بزرگ مثل وبسایت آمازون نمیتونه روی یک ماشین واحد اجرا بشه. انتخاب بین یکپارچگی (Consistency) و دسترسپذیری (Availability) به قیمت از دست دادن تحمل پارتیشن (Partition Tolerance) اصلاً مطرح نیست—آمازون دادههای خیلی زیادی داره که روی یک سرور واحد، هرچقدر هم بزرگ باشه، قابل ذخیره نیست.
بنابراین انتخاب اصلی به معامله بین یکپارچگی و دسترسپذیری برمیگرده:
- در بعضی بخشهای سیستم، بهتره کمی از یکپارچگی کوتاه بیای تا دسترسپذیری بیشتری داشته باشی. مثلاً در نمایش کاتالوگ محصولات، معمولاً مشکلی نداره اگر بعضی بخشها قدیمی باشن؛ در این سناریو دسترسپذیری اولویت بالاتری داره.
- اما در بهروزرسانی توضیحات محصول، یکپارچگی مهمتر از دسترسپذیریه: گرههای شبکه باید روی آخرین نسخهی توضیحات توافق داشته باشن تا از بروز conflict در ادغام جلوگیری بشه.
۴.۵ بررسی مفاهیم شناختهشدهی تست خودکار
چهار ویژگی یک تست واحد خوب پایهای هستن. همهی مفاهیم شناختهشدهی تست خودکار به این چهار ویژگی برمیگردن. در این بخش، به دو مفهوم مهم نگاه میکنیم: هرم تست و تست جعبه سفید در برابر تست جعبه سیاه.
۴.۵.۱ تجزیهی هرم تست (Breaking down the Test Pyramid)
هرم تست مفهومیست که نسبت مشخصی از انواع مختلف تستها در مجموعهی تست پیشنهاد میکنه (شکل ۴.۱۱):
- تستهای واحد (Unit tests)
- تستهای یکپارچهسازی (Integration tests)
- تستهای End-to-End
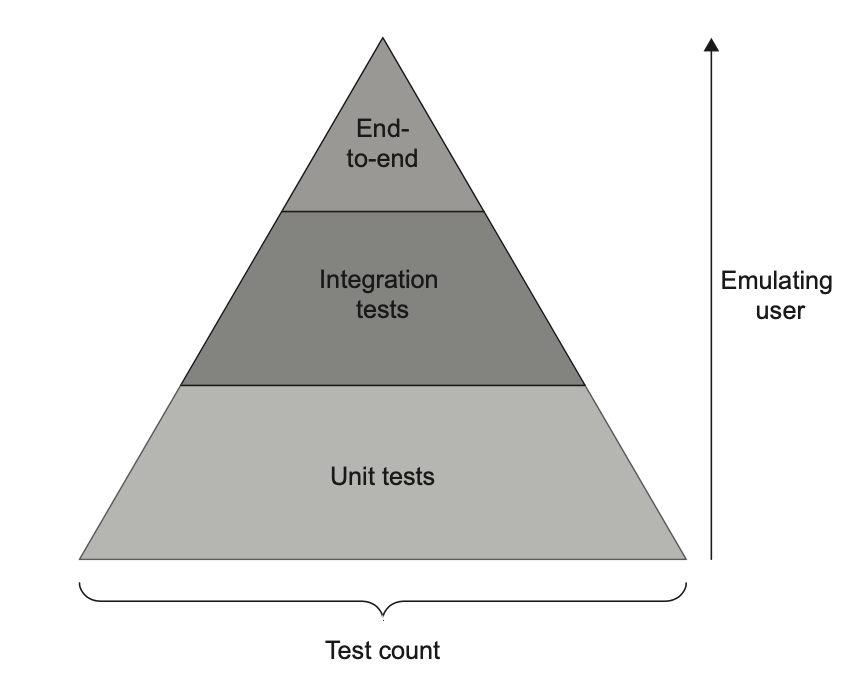
هرم تست معمولاً بهصورت یک هرم نمایش داده میشه که شامل سه نوع تست هست. عرض هر لایه نشاندهندهی میزان فراوانی اون نوع تست در مجموعهی تستهاست؛ هرچه لایه پهنتر باشه، تعداد تستها بیشتره. ارتفاع لایه هم نشون میده که این تستها چقدر به شبیهسازی رفتار کاربر نهایی نزدیک هستن.
تستهای End-to-End در بالای هرم قرار دارن—اونها نزدیکترین تستها به تجربهی کاربر هستن. انواع مختلف تست در هرم انتخابهای متفاوتی در معامله بین بازخورد سریع و محافظت در برابر regression انجام میدن. تستهای لایههای بالاتر بیشتر به محافظت در برابر regression گرایش دارن، در حالی که تستهای لایههای پایینتر بر سرعت اجرا تأکید میکنن (شکل ۴.۱۲).
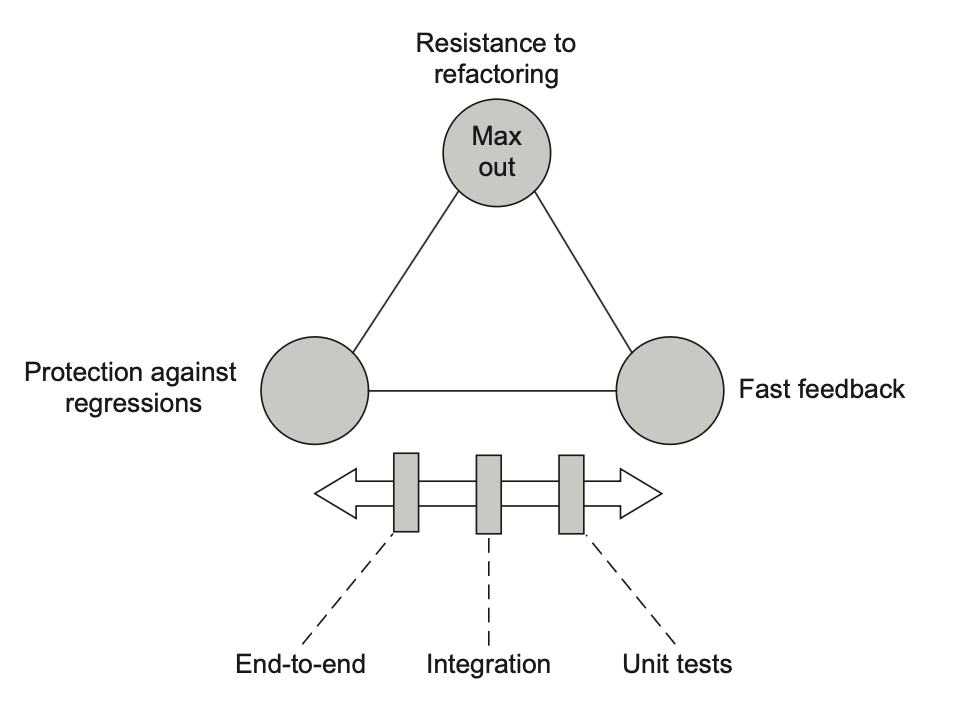
هیچکدوم از لایهها مقاومت در برابر بازآرایی رو از دست نمیدن. بهطور طبیعی، تستهای End-to-End و یکپارچهسازی در این معیار امتیاز بیشتری میگیرن، اما فقط بهعنوان یک اثر جانبیِ جدا بودن بیشتر از کد تولید. با این حال، حتی تستهای واحد هم نباید مقاومت در برابر بازآرایی رو قربانی کنن. همهی تستها باید هدفشون تولید کمترین تعداد مثبت کاذب باشه، حتی زمانی که مستقیماً با کد تولید کار میکنن. (چگونگی انجام این کار موضوع فصل بعده.)
ترکیب دقیق انواع تستها برای هر تیم و پروژه متفاوت خواهد بود. اما بهطور کلی باید شکل هرم رو حفظ کنه: تستهای End-to-End در اقلیت باشن، تستهای واحد در اکثریت، و تستهای یکپارچهسازی جایی در میانه قرار بگیرن.
دلیل اینکه تستهای End-to-End در اقلیت هستن، دوباره به قانون ضرب در بخش ۴.۴ برمیگرده. این تستها در معیار بازخورد سریع امتیاز بسیار پایینی دارن. همچنین از نظر قابلیت نگهداری ضعیف هستن: معمولاً بزرگترن و نیاز به تلاش بیشتری برای نگهداری وابستگیهای خارج از فرآیند دارن. بنابراین تستهای End-to-End فقط زمانی معنا پیدا میکنن که روی حیاتیترین قابلیتها اعمال بشن—ویژگیهایی که به هیچوجه نمیخوای در اونها باگی دیده بشه—و فقط وقتی که نتونی همون سطح محافظت رو با تستهای واحد یا یکپارچهسازی به دست بیاری. استفاده از تستهای End-to-End برای هر چیز دیگهای نباید از حداقل آستانهی ارزش مورد نیازت عبور کنه. تستهای واحد معمولاً متعادلتر هستن و به همین دلیل تعداد خیلی بیشتری از اونها وجود داره.
استثناهایی برای هرم تست وجود دارن. برای مثال، اگر کل اپلیکیشن فقط عملیات سادهی CRUD (ایجاد، خواندن، بهروزرسانی و حذف) رو انجام بده و قوانین تجاری یا پیچیدگی خاصی نداشته باشه، «هرم تست» بیشتر شبیه یک مستطیل خواهد بود: تعداد تستهای واحد و تستهای یکپارچهسازی برابر و بدون تست End-to-End.
در محیطی بدون پیچیدگی الگوریتمی یا تجاری، تستهای واحد خیلی زود به تستهای پیشپاافتاده تبدیل میشن. در عین حال، تستهای یکپارچهسازی همچنان ارزش خودشون رو حفظ میکنن—حتی برای کدی که سادهست، مهمه بررسی بشه که در یکپارچگی با زیرسیستمهایی مثل پایگاه داده درست کار میکنه. در نتیجه، ممکنه تعداد تستهای واحد کمتر و تستهای یکپارچهسازی بیشتر بشه. در سادهترین مثالها، حتی تعداد تستهای یکپارچهسازی میتونه بیشتر از تستهای واحد باشه.
استثنای دیگه مربوط به یک API هست که فقط با یک وابستگی خارج از فرآیند (مثل پایگاه داده) کار میکنه. در چنین اپلیکیشنی داشتن تستهای End-to-End بیشتر میتونه گزینهی مناسبی باشه. چون رابط کاربری وجود نداره، این تستها نسبتاً سریع اجرا میشن. هزینهی نگهداری هم زیاد نیست، چون فقط با یک وابستگی خارجی (پایگاه داده) سروکار داری. در این محیط، تستهای End-to-End عملاً از تستهای یکپارچهسازی قابل تشخیص نیستن؛ تنها تفاوت در نقطهی ورود هست: تستهای End-to-End نیاز دارن اپلیکیشن جایی میزبانی بشه تا کاربر نهایی رو بهطور کامل شبیهسازی کنن، در حالی که تستهای یکپارچهسازی معمولاً اپلیکیشن رو در همان فرآیند اجرا میکنن.
به هرم تست در فصل ۸ دوباره برمیگردیم، زمانی که دربارهی تستهای یکپارچهسازی صحبت خواهیم کرد.
۴.۵.۲ انتخاب بین تست جعبه سیاه و جعبه سفید
مفهوم شناختهشدهی دیگه در تست خودکار، تست جعبه سیاه در برابر تست جعبه سفید هست. در این بخش توضیح داده میشه که چه زمانی باید از هر رویکرد استفاده کرد:
- تست جعبه سیاه (Black-box testing): روشی برای تست نرمافزار که عملکرد سیستم رو بدون اطلاع از ساختار داخلی بررسی میکنه. این نوع تست معمولاً بر اساس مشخصات و نیازمندیها ساخته میشه: اینکه برنامه باید چه کاری انجام بده، نه اینکه چطور انجامش بده.
- تست جعبه سفید (White-box testing): نقطهی مقابل تست جعبه سیاهه. روشی برای تست که کارکردهای داخلی برنامه رو بررسی میکنه. این تستها از روی کد منبع استخراج میشن، نه از روی نیازمندیها یا مشخصات.
هر دو روش مزایا و معایب خودشون رو دارن. تست جعبه سفید معمولاً جامعتره؛ با تحلیل کد منبع میتونی خطاهای زیادی رو کشف کنی که در صورت اتکا فقط به مشخصات بیرونی ممکنه از دست برن. از طرف دیگه، تستهای حاصل از جعبه سفید اغلب شکننده هستن، چون بهطور محکم به پیادهسازی خاص کد وابسته میشن. این تستها مثبتهای کاذب زیادی تولید میکنن و در نتیجه در معیار مقاومت در برابر بازآرایی ضعیف عمل میکنن. همچنین اغلب نمیشه اونها رو به رفتاری که برای یک فرد تجاری معنا داشته باشه ربط داد، که نشانهی محکمیه از شکنندگی و کمارزش بودن این تستها. تست جعبه سیاه مجموعهی معکوسی از مزایا و معایب رو ارائه میده.
| نوع تست | محافظت در برابر regression | مقاومت در برابر بازآرایی |
|---|---|---|
| تست جعبه سفید | خوب | بد |
| تست جعبه سیاه | بد | خوب |
همانطور که در بخش ۴.۴.۵ یادآوری شد، نمیتوان روی مقاومت در برابر بازآرایی مصالحه کرد: تست یا این ویژگی را دارد یا ندارد. بنابراین، بهطور پیشفرض تست جعبه سیاه را به جای تست جعبه سفید انتخاب کن. همهی تستها—چه واحد، چه یکپارچهسازی، چه End-to-End—باید سیستم را بهصورت یک جعبه سیاه ببینند و رفتاری معنادار برای دامنهی مسئله را بررسی کنند. اگر نتوانی یک تست را به یک نیازمندی تجاری ربط بدهی، نشانهی شکنندگی آن تست است. این تست را یا بازنویسی کن یا حذف؛ اجازه نده به همان شکل وارد مجموعه شود. تنها استثنا زمانی است که تست کدی کمکی با پیچیدگی الگوریتمی بالا را پوشش دهد (بیشتر در فصل ۷).
توجه داشته باش که هرچند تست جعبه سیاه هنگام نوشتن تستها ترجیح داده میشود، همچنان میتوان از روش جعبه سفید هنگام تحلیل تستها استفاده کرد. از ابزارهای پوشش کد استفاده کن تا ببینی کدام شاخههای کد اجرا نشدهاند، اما سپس آنها را طوری تست کن که انگار هیچ اطلاعی از ساختار داخلی کد نداری. چنین ترکیبی از روشهای جعبه سفید و جعبه سیاه بهترین نتیجه را میدهد.
خلاصه
- یک تست واحد خوب چهار ویژگی پایهای داره که میتونی برای تحلیل هر تست خودکار (واحد، یکپارچهسازی یا End-to-End) ازشون استفاده کنی:
– محافظت در برابر regression
– مقاومت در برابر بازآرایی
– بازخورد سریع
– قابلیت نگهداری - محافظت در برابر regression معیاریه برای اینکه تست چقدر در نشان دادن وجود باگها خوب عمل میکنه. هرچه کد بیشتری اجرا بشه (چه کد خودت و چه کتابخانهها و فریمورکهای پروژه)، احتمال کشف باگ بیشتره.
- مقاومت در برابر بازآرایی درجهایه که تست میتونه بازآرایی کد برنامه رو بدون تولید مثبت کاذب تحمل کنه.
- مثبت کاذب یعنی هشدار اشتباه—نتیجهای که نشون میده تست شکست خورده، در حالی که عملکرد پوشش دادهشده درست کار میکنه. مثبتهای کاذب اثرات مخربی روی مجموعه تست دارن:
– باعث میشن توانایی و تمایل به واکنش به مشکلات کد کاهش پیدا کنه، چون به هشدارهای اشتباه عادت میکنی و دیگه توجه نمیکنی.
– اعتماد به تستها بهعنوان یک شبکهی ایمنی قابل اتکا رو کم میکنن و باعث از دست رفتن اعتماد به مجموعه تست میشن. - مثبتهای کاذب نتیجهی اتصال محکم بین تستها و جزئیات داخلی پیادهسازی هستن. برای جلوگیری از این اتصال، تست باید نتیجهی نهایی تولیدشده توسط SUT رو بررسی کنه، نه مراحل داخلی رسیدن به اون.
- محافظت در برابر regression و مقاومت در برابر بازآرایی به دقت تست کمک میکنن. تست دقیق تستیه که سیگنال قوی (توانایی پیدا کردن باگها) رو با کمترین نویز (مثبتهای کاذب) تولید کنه.
- مثبتهای کاذب در ابتدای پروژه اثر منفی زیادی ندارن، اما با رشد پروژه اهمیتشون بیشتر میشه و بهاندازهی مثبتهای منفی (باگهای کشفنشده) مهم میشن.
- بازخورد سریع معیاریه برای اینکه تست چقدر سریع اجرا میشه.
- قابلیت نگهداری شامل دو بخشه:
– میزان سختی درک تست. هرچه تست کوچکتر باشه، خوانایی بیشتره.
– میزان سختی اجرای تست. هرچه وابستگیهای خارج از فرآیند کمتر باشه، نگهداری راحتتره. - ارزش یک تست حاصل ضرب امتیازهاییست که در هر چهار ویژگی میگیره. اگر در یکی از ویژگیها امتیاز صفر بگیره، ارزش تست هم صفر میشه.
- ایجاد تستی که در هر چهار ویژگی امتیاز کامل بگیره غیرممکنه، چون سه ویژگی اول—محافظت در برابر regression، مقاومت در برابر بازآرایی و بازخورد سریع—متناقض هستن. تست فقط میتونه دو تا از این سه رو به حداکثر برسونه.
- مقاومت در برابر بازآرایی غیرقابل مصالحهست، چون داشتن یا نداشتن این ویژگی تقریباً انتخابی دودویی هست. معامله بین ویژگیها به انتخاب بین محافظت در برابر regression و بازخورد سریع برمیگرده.
- هرم تست نسبت مشخصی از تستهای واحد، یکپارچهسازی و End-to-End رو توصیه میکنه: تستهای End-to-End در اقلیت، تستهای واحد در اکثریت و تستهای یکپارچهسازی در میانه.
- انواع مختلف تست در هرم انتخابهای متفاوتی بین بازخورد سریع و محافظت در برابر regression انجام میدن. تستهای End-to-End بیشتر به محافظت در برابر regression گرایش دارن، در حالی که تستهای واحد بر بازخورد سریع تأکید میکنن.
- هنگام نوشتن تستها از روش جعبه سیاه استفاده کن. هنگام تحلیل تستها از روش جعبه سفید بهره ببر.