
توی این بخش از کتاب، قراره با وضعیت فعلی تست واحد (unit testing) آشنا بشی و یه دید کلی و بهروز ازش پیدا کنی. تو فصل اول، هدف اصلی تست واحد رو تعریف میکنیم و یاد میگیریم چطور یه تست خوب رو از یه تست بد تشخیص بدیم. دربارهی معیارهای پوشش کد (coverage metrics) هم صحبت میکنیم و میریم سراغ ویژگیهایی که یه تست خوب باید داشته باشه.تو فصل دوم، تعریف دقیق تست واحد رو بررسی میکنیم. شاید بهنظر برسه این تعریف چیز کوچیکیه، ولی همین اختلافنظر کوچیک باعث شده دو مکتب فکری متفاوت تو دنیای تستنویسی شکل بگیره—که قراره با هر دوشون آشنا بشیم. و تو فصل سوم، یه مرور کلی داریم روی مفاهیم پایهای مثل ساختاردهی به تستها، استفادهی مجدد از fixtureها، و پارامتردهی تستها
۱ هدف تست واحد
این فصل شامل موضوعات زیره:
- وضعیت فعلی تست واحد تو صنعت نرم افزار
- هدف اصلی از تست واحد
- پیامدهای داشتن یه مجموعه تست ضعیف
- استفاده از معیارهای پوشش کد (coverage metrics) برای سنجش کیفیت تستها
- ویژگیهای یه مجموعه تست موفق
یاد گرفتن تست واحد فقط به تسلط روی بخشهای فنی مثل فریمورک مورد علاقهت، کتابخونهی mocking و از این جور چیزها ختم نمیشه. تست واحد خیلی فراتر از صرفاً نوشتن چند تا تست سادهست. همیشه باید دنبال این باشی که بیشترین بازده رو از زمانی که برای تستنویسی میذاری بگیری – یعنی با کمترین زحمت، بیشترین فایده رو از تستها دربیاری. و رسیدن به این تعادل اصلاً کار سادهای نیست.
دیدن پروژههایی که این تعادل رو پیدا کردن واقعاً لذتبخشه: بدون دردسر رشد میکنن، نیاز به نگهداری زیادی ندارن، و خیلی راحت خودشون رو با نیازهای همیشهدرحالتغییر مشتریها وفق میدن. اما در مقابل، پروژههایی که این تعادل رو از دست دادن، واقعاً آدم رو کلافه میکنن. با اینکه کلی تلاش براشون شده و حتی تعداد زیادی تست واحد دارن، ولی کند پیش میرن، پر از باگن، و هزینهی نگهداریشون بالاست.
این همون تفاوتیه که بین تکنیکهای مختلف تست واحد وجود داره. بعضیها نتیجههای خیلی خوبی میدن و کمک میکنن کیفیت نرمافزار حفظ بشه. بعضیهای دیگه نه—تستهایی تولید میکنن که خیلی به درد نمیخورن، زود به زود خراب میشن، و کلی هزینهی نگهداری دارن.
چیزی که تو این کتاب یاد میگیری، کمکت میکنه بتونی بین تکنیکهای خوب و بد تستنویسی فرق بذاری. یاد میگیری چطور یه تحلیل هزینه-فایده برای تستهات انجام بدی و تکنیکهای درست رو متناسب با شرایط خودت بهکار ببری. همچنین یاد میگیری چطور از الگوهای اشتباه رایج (anti-patternها) دوری کنی—الگوهایی که اولش منطقی بهنظر میرسن، ولی بعداً دردسر درست میکنن.
اما بیایم از پایه شروع کنیم. این فصل یه مرور سریع از وضعیت تست واحد تو صنعت نرمافزار ارائه میده، هدف پشت نوشتن و نگهداری تستها رو توضیح میده، و یه دید کلی میده از اینکه چی باعث میشه یه مجموعه تست واقعاً موفق باشه.
۱.۱ وضعیت فعلی تست واحد
توی دو دههی گذشته، یه موج جدی برای استفاده از تست واحد راه افتاده. این موج اونقدر موفق بوده که الان تست واحد تو بیشتر شرکتها تبدیل شده به یه الزام. اکثر برنامهنویسها تست واحد رو انجام میدن و اهمیتش رو هم خوب میدونن. دیگه کسی بحث نمیکنه که “آیا باید تست بنویسیم یا نه”— مگر اینکه داری روی یه پروژهی موقتی و دورریختنی کار میکنی، وگرنه جوابش واضحه: بله، باید بنویسی.
وقتی صحبت از توسعهی اپلیکیشنهای سازمانی (enterprise) میشه، تقریباً همهی پروژهها حداقل یه مقدار تست واحد دارن. اما درصد قابلتوجهی از این پروژهها خیلی فراتر میرن: پوشش کد خوبی دارن و پر از تستهای واحد و تستهای یکپارچهسازی (integration) هستن. نسبت بین کد اصلی (production code) و کد تست میتونه چیزی بین ۱:۱ تا ۱:۳ باشه— یعنی به ازای هر خط کد اصلی، یک تا سه خط کد تست نوشته شده. گاهی این نسبت خیلی بیشتر هم میشه، تا جایی که به عدد عجیب ۱:۱۰ میرسه.
مثل هر تکنولوژی جدید دیگه، تست واحد هم مدام در حال تکامل و تغییره. بحثها دیگه سر این نیست که “آیا باید تست واحد بنویسیم؟” بلکه رسیده به این سؤال مهمتر: “تست واحد خوب یعنی چی؟” و همینجاست که هنوز خیلیها گیج میشن.
نتیجهی این سردرگمی رو میتونی تو پروژههای نرمافزاری ببینی. خیلی از پروژهها تستهای خودکار دارن—حتی ممکنه تعدادشون هم زیاد باشه. ولی وجود این تستها معمولاً اون نتیجهای رو که برنامهنویسها انتظار دارن نمیده. پیشرفت تو این پروژهها هنوز هم برای برنامهنویسها سخت و زمانبره. اضافه کردن قابلیتهای جدید خیلی طول میکشه، باگهای تازه مدام تو بخشهایی ظاهر میشن که قبلاً پیادهسازی و تأیید شده بودن، و تستهای واحدی که قرار بوده کمککننده باشن، عملاً هیچ کمکی نمیکنن— حتی گاهی اوضاع رو بدتر هم میکنن.
این وضعیت برای هر کسی واقعاً آزاردهندهست و دلیلش اینه که تستهای واحد اونطور که باید، کار خودشون رو درست انجام نمیدن. تفاوت بین تست خوب و تست بد فقط یه مسئلهی سلیقه یا ترجیح شخصی نیست؛ بلکه یه تفاوت حیاتی بین موفق شدن یا شکست خوردن تو پروژهایه که داری روش کار میکنی.
اهمیت بحث در مورد اینکه «تست واحد خوب دقیقاً چیه» اونقدر زیاده که واقعاً نمیشه دستکم گرفتش. با این حال، این بحث هنوز اونطور که باید تو صنعت توسعهی نرمافزار جا نیفتاده. اینجا و اونجا چند تا مقاله یا ارائهی کنفرانسی پیدا میکنی، ولی هنوز منبعی که واقعاً جامع و کامل به این موضوع پرداخته باشه، ندیدم.
وضعیت کتابها هم بهتر نیست؛ بیشترشون فقط روی اصول اولیهی تست واحد تمرکز دارن و خیلی جلوتر نمیرن. البته سوءتفاهم نشه—همین کتابها هم ارزش خودشون رو دارن، مخصوصاً وقتی تازه میخوای با تست واحد آشنا بشی. ولی یادگیری با اصول پایه تموم نمیشه. یه مرحلهی بعدی هم هست: نه فقط نوشتن تست، بلکه تستنویسی به شکلی که بیشترین بازده رو از وقتی که براش میذاری بهت بده. وقتی به این نقطه میرسی، بیشتر کتابها دیگه ولت میکنن به حال خودت تا ببینی چطور باید به اون سطح بعدی برسی.
این کتاب تو رو به اون سطح بعدی میرسونه. یه تعریف دقیق و علمی از تست واحد ایدهآل ارائه میده، و نشون میده چطور میتونی این تعریف رو تو مثالهای واقعی و عملی بهکار ببری. امید من اینه که این کتاب کمک کنه بفهمی چرا ممکنه پروژهی خاصی که روش کار میکنی با وجود داشتن تعداد زیادی تست، مسیرش رو اشتباه رفته باشه و چطور میتونی این مسیر رو اصلاح کنی و به نتیجهی بهتر برسونی.
اگه تو حوزهی توسعهی اپلیکیشنهای سازمانی کار میکنی، بیشترین بهره رو از این کتاب میبری، ولی ایدههای اصلیش برای هر پروژهی نرمافزاری قابل استفادهست.
اپلیکیشن سازمانی (Enterprise Application) چی هست؟
اپلیکیشن سازمانی (Enterprise Application) اپلیکیشنیه که هدفش خودکارسازی یا کمک به انجام فرآیندهای داخلی یه سازمانه. این نوع نرمافزارها شکلهای مختلفی دارن، ولی معمولاً ویژگیهاشون ایناست:
- پیچیدگی بالای منطق تجاری (business logic)
- عمر طولانی پروژه
- حجم متوسط داده
- نیازهای عملکردی پایین یا متوسط (performance requirements)
۱.۲ هدف تست واحد
قبل از اینکه عمیق وارد موضوع تست واحد بشیم، یه قدم عقبتر برداریم و ببینیم اصلاً تست واحد قراره چه هدفی رو برامون محقق کنه. خیلی وقتها گفته میشه که تست واحد باعث طراحی بهتر میشه—و این حرف درسته: لزوم نوشتن تست برای یه کدبیس معمولاً منجر به طراحی تمیزتر و بهتر میشه. ولی این، هدف اصلی تست واحد نیست؛ فقط یه اثر جانبی خوشاینده.
رابطهی بین تست واحد و طراحی کد
میزان تستپذیری یه قطعه کد، معیار خوبی برای بررسی کیفیت طراحی کد هست—ولی فقط در یه جهت کار میکنه. یعنی بیشتر بهعنوان یه شاخص منفی عمل میکنه: با دقت نسبتاً بالا نشون میده که یه کد کیفیت پایینی داره. اگه دیدی تستنویسی برای یه بخش از کد سخته، این یه نشونهی قویه که اون کد نیاز به بهبود داره. این کیفیت پایین معمولاً خودش رو بهصورت coupling بالا نشون میده یعنی بخشهای مختلف کد تولیدی بهاندازهی کافی از هم جدا نیستن، و تست کردنشون بهصورت مستقل خیلی سخت میشه.
متأسفانه، تستپذیری یه قطعه کد شاخص مثبت خوبی نیست. اینکه بتونی راحت برای کدت تست واحد بنویسی، لزوماً به این معنی نیست که اون کد کیفیت بالایی داره. یه پروژه ممکنه از نظر decoupling هم خیلی خوب بهنظر برسه، ولی در عمل یه فاجعهی کامل باشه.
پس هدف تست واحد چیه؟ هدف اصلی اینه که رشد پروژهی نرمافزاری رو «پایدار» کنه. واژهی «پایدار» اینجا خیلی مهمه. رشد دادن یه پروژه، مخصوصاً وقتی از صفر شروع میکنی، کار سختی نیست. ولی اینکه بتونی این رشد رو در طول زمان حفظ کنی، اونجاست که چالش واقعی شروع میشه.
نمودار شکل ۱.۱ نشون میده که یه پروژهی معمولی بدون تست چطور رشد میکنه: اولش همهچیز سریع پیش میره، چون چیزی نیست که جلوی حرکتت رو بگیره. هنوز تصمیمات معماری اشتباه نگرفتی، و کدی هم وجود نداره که بخوای نگرانش باشی. اما هر چی زمان میگذره، برای اینکه همون مقدار پیشرفت اولیه رو داشته باشی، باید ساعتهای بیشتری کار کنی. در نهایت، سرعت توسعه بهشدت کم میشه – گاهی حتی به جایی میرسی که دیگه عملاً نمیتونی هیچ پیشرفتی داشته باشی.
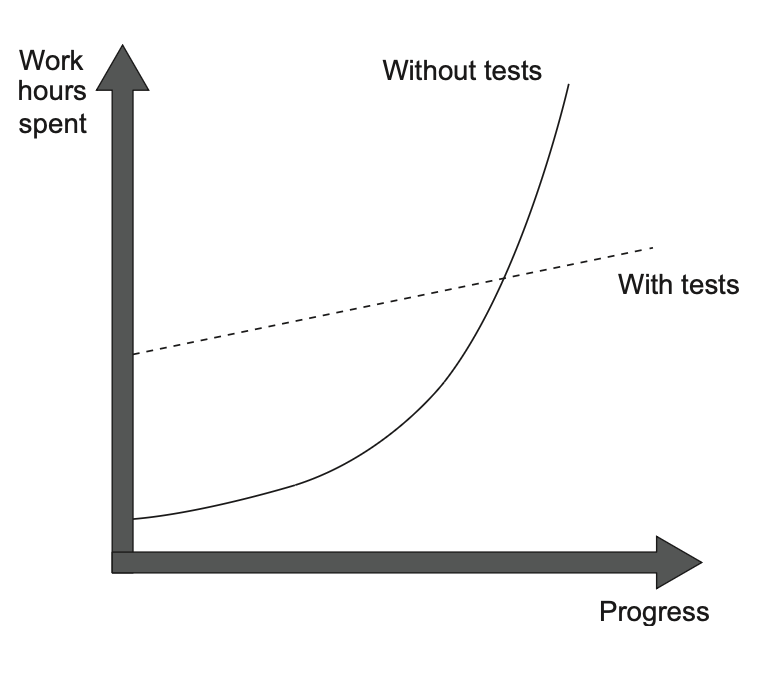
شکل ۱.۱
تفاوت دینامیک رشد بین پروژههایی که تست دارن و اونهایی که ندارن رو نشون میده: پروژهای که تست نداره، اولش با سرعت بالا شروع میکنه—چون چیزی نیست که مانعش بشه. ولی خیلی زود سرعتش کم میشه، تا جایی که پیشرفت کردن توش واقعاً سخت میشه.
این پدیدهی کاهش سریع سرعت توسعه، با یه اصطلاح علمی هم شناخته میشه: «آنتروپی نرمافزار» (software entropy). آنتروپی یعنی میزان بینظمی یا آشفتگی تو یه سیستم—یه مفهوم علمی و ریاضی که تو دنیای نرمافزار هم کاربرد داره. اگه به جنبههای علمی و ریاضی این موضوع علاقه داری، میتونی یه نگاهی بندازی به «قانون دوم ترمودینامیک»؛
در دنیای نرمافزار، آنتروپی خودش رو بهصورت کدی نشون میده که به مرور زمان رو به زوال میره. هر بار که چیزی رو توی کد تغییر میدی، میزان بینظمی یا همون آنتروپی بیشتر میشه. اگه این وضعیت رو به حال خودش رها کنی—بدون مراقبتهایی مثل تمیزکاری مداوم و بازسازی (refactoring)— سیستم کمکم پیچیدهتر و آشفتهتر میشه. یه باگ رو که درست میکنی، چند تا باگ جدید ظاهر میشن. یه بخش از نرمافزار رو که تغییر میدی، چند جای دیگه خراب میشن – مثل یه اثر دومینو، این بینظمی ادامه پیدا میکنه تا جایی که کل کدبیس دیگه قابل اعتماد نیست. و بدتر از همه، برگردوندن سیستم به حالت پایدار واقعاً سخت میشه.
تستها کمک میکنن جلوی این روند رو بگیری. مثل یه تور ایمنی عمل میکنن—یه ابزار که جلوی بیشتر خطاهای برگشتی (regressions) رو میگیره. تستها مطمئن میشن که قابلیتهای موجود هنوز هم درست کار میکنن، حتی وقتی داری ویژگیهای جدید اضافه میکنی یا کد رو بازسازی میکنی تا با نیازهای جدید هماهنگتر بشه.
تعریف: Regression یعنی وقتی یه قابلیت بعد از یه اتفاق—معمولاً تغییر در کد—دیگه اونطور که باید کار نمیکنه. اصطلاحهای regression و باگ نرمافزاری (software bug) در عمل مترادف هستن و میتونی بهجای هم استفادهشون کنی.
نکتهی منفی اینجاست که نوشتن تستها در ابتدا—و گاهی حتی بهطور قابلتوجهی—نیاز به صرف زمان و انرژی داره. ولی در بلندمدت، این تلاشها خودشون رو جبران میکنن؛ چون باعث میشن پروژه تو مراحل بعدی رشد کنه و از هم نپاشه. توسعهی نرمافزار بدون تستهایی که بهطور مداوم کدبیس رو بررسی کنن، اصلاً مقیاسپذیر نیست.
دو کلید اصلی موفقیت اینجا هستن: پایداری (sustainability) و مقیاسپذیری (scalability). اگه این دو رو داشته باشی، میتونی سرعت توسعه رو در بلندمدت حفظ کنی—بدون اینکه پروژه زیر بار پیچیدگی له بشه.
۱.۲.۱ تست خوب یا بد یعنی چی؟
درسته که تست واحد به رشد پروژه کمک میکنه، ولی صرفاً نوشتن تست کافی نیست—اگه تستها بد نوشته شده باشن، نتیجهی کلی همون میمونه.
طبق نمودار شکل ۱.۲، تستهای ضعیف در ابتدای کار یه مقدار جلوی افت کیفیت کد رو میگیرن: سرعت توسعه نسبت به حالتی که اصلاً تستی وجود نداره، کمتر افت میکنه. اما در تصویر کلی، چیزی تغییر نمیکنه. ممکنه ورود پروژه به فاز رکود کمی دیرتر اتفاق بیفته، ولی اون رکود در نهایت اجتنابناپذیره.
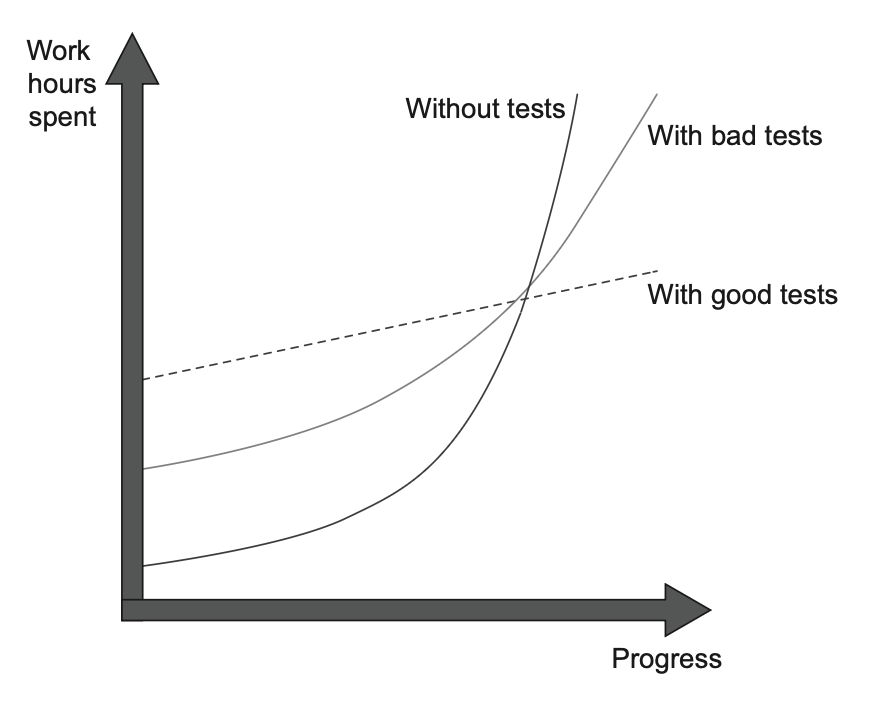
شکل ۱.۲ تفاوت در داینامیک رشد بین پروژههایی با تستهای خوب و تستهای بد را نشان میدهد. پروژهای با تستهای ضعیف در ابتدا ویژگیهای پروژهای با تستهای خوب را نشان میدهند اما در نهایت وارد مرحلهی رکود میشوند.
یادت باشه که همهی تستها ارزش یکسانی ندارن. بعضیها واقعاً مفیدن و به کیفیت کلی نرمافزار کمک زیادی میکنن، ولی بعضیهای دیگه اینطور نیستن—فقط هشدارهای اشتباه میدن، جلوی باگهای برگشتی رو نمیگیرن، و کندن و نگهداریشون سخت هست. خیلی راحت میتونی تو دام نوشتن تست واحد صرفاً بهخاطر «داشتن تست» بیفتی—بدون اینکه واقعاً بدونی آیا این تستها به پروژه کمک میکنن یا نه.
با زیاد کردن تعداد تستها بهتنهایی نمیتونی به هدف تست واحد برسی. باید هم ارزش تست رو در نظر بگیری، هم هزینهی نگهداریش. هزینهی نگهداری تست شامل زمانیه که صرف این کارها میشه:
- بازسازی تست وقتی که کد اصلی رو refactor میکنی
- اجرای تست بعد از هر تغییر در کد
- رسیدگی به هشدارهای اشتباه (false alarms)
- صرف زمان برای خوندن تست وقتی میخوای بفهمی کد اصلی چطور رفتار میکنه
خیلی راحت میشه تستهایی نوشت که ارزش خالصشون نزدیک به صفر باشه—یا حتی منفی باشه، بهخاطر هزینهی نگهداری بالا. برای اینکه رشد پروژه پایدار بمونه، باید فقط روی تستهای باکیفیت تمرکز کنی – چون فقط همین نوع تستها هستن که ارزش نگهداشتن تو مجموعهی تست رو دارن.
کد تولیدی (Production) در برابر کد تست
خیلیها فکر میکنن کد تولیدی (production code) و کد تست دو چیز کاملاً جدا هستن. تستها معمولاً بهعنوان یه افزونهی جانبی برای کد تولیدی در نظر گرفته میشن—بدون هیچ هزینهای برای نگهداری. و به همین دلیل، خیلیها باور دارن که «هر چی تست بیشتر، بهتر». ولی این تصور درست نیست.
کد یه تعهده، نه یه دارایی. هر چی کد بیشتری وارد پروژه کنی، سطح تماس نرمافزار با باگهای احتمالی بیشتر میشه، و هزینهی نگهداری پروژه هم بالاتر میره. همیشه بهتره مسائل رو با کمترین مقدار کد ممکن حل کنی.
تستها هم کدن. باید اونها رو بهعنوان بخشی از کدبیس ببینی که هدفش حل یه مسئلهی خاصه: اطمینان از درستی عملکرد برنامه. تستهای واحد، درست مثل هر کد دیگهای، ممکنه خودشون باگ داشته باشن و نیاز به نگهداری داشته باشن.
۱.۳ استفاده از معیارهای پوشش برای سنجش کیفیت مجموعه تست
در این بخش، دربارهی دو معیار پوشش محبوب صحبت میکنیم—پوشش کد (code coverage) و پوشش شاخهها (branch coverage)، نحوهی محاسبهشون، کاربردهاشون، و مشکلاتی که دارن.
نشون میدم چرا هدفگذاری برای رسیدن به یه عدد خاص در پوشش تست میتونه برای برنامهنویسها مضر باشه، و چرا نمیتونی فقط به این معیارها تکیه کنی تا کیفیت مجموعه تستهات رو بسنجی.
تعریف:
معیار پوشش (coverage metric) نشون میده که چه مقدار از کد منبع توسط مجموعه تست اجرا شده (تست شده) – از صفر تا صد درصد.
انواع مختلفی از معیارهای پوشش وجود دارن، و معمولاً برای ارزیابی کیفیت مجموعه تست استفاده میشن. باور رایج اینه که هر چی عدد پوشش بالاتر باشه، بهتره.
ولی متأسفانه قضیه به این سادگی نیست. معیارهای پوشش، با اینکه بازخورد مفیدی میدن، نمیتونن بهطور مؤثر کیفیت مجموعه تست رو اندازهگیری کنن. این دقیقاً مثل همون بحث تستپذیری کده: معیارهای پوشش (coverage metrics)، شاخص منفی خوبی هستن ولی شاخص مثبت خوبی نیستن.
اگه یه معیار نشون بده که پوشش تست خیلی پایینه—مثلاً فقط ۱۰٪ – این یه نشونهی خوبه که تست کافی برای کدت ننوشتی. ولی برعکسش درست نیست: حتی ۱۰۰٪ پوشش هم تضمین نمیکنه که مجموعه تستت باکیفیت باشه. ممکنه یه مجموعه تست با پوشش بالا داشته باشی، ولی همچنان کیفیت پایینی داشته باشه.
قبلاً اشاره کردم که چرا اینطور میشه – نمیتونی همینطوری تستهای تصادفی رو به پروژه اضافه کنی و انتظار داشته باشی که اوضاع بهتر بشه. حالا بیایم این مشکل رو با تمرکز روی معیار پوشش کد (code coverage) دقیقتر بررسی کنیم.
۱.۳.۱ درک معیار پوشش کد (Code Coverage)
اولین و پرکاربردترین معیار پوشش، پوشش کد (code coverage) یا همون پوشش تست (test coverage) هست؛ به شکل ۱.۳ نگاه کن. این معیار نسبت تعداد خطوطی از کد تولیدی رو که حداقل توسط یک تست اجرا شدن، به کل خطوط کد تولیدی نشون میده.
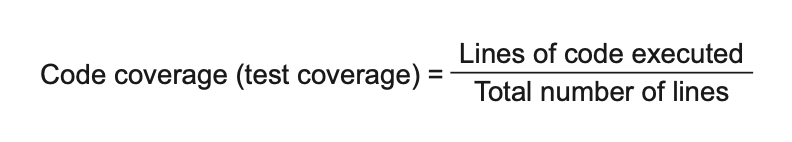
شکل ۱.۳ معیار پوشش کد (یا پوشش تست) را نشان میدهد که بهصورت نسبت بین تعداد خطوطی از کد که توسط مجموعه تست اجرا شدهاند و کل خطوط موجود در کد تولیدی محاسبه میشود.
public static bool IsStringLong(string input)
{
if (input.Length > 5)
return true;
return false;
}
public void Test()
{
bool result = IsStringLong("abc");
Assert.Equal(false, result);
}قطعه کد ۱.۱
بیایم یه مثال ببینیم تا بهتر بفهمیم این معیار چطور کار میکنه. در قطعهکد ۱.۱، متدی به نام IsStringLong داریم و یه تست که اون رو پوشش میده. این متد بررسی میکنه که آیا رشتهای که بهعنوان ورودی دریافت کرده، «طولانی» هست یا نه – در اینجا، «طولانی» یعنی رشتهای که طولش بیشتر از پنج کاراکتر باشه. تست این متد رو با ورودی "abc" اجرا میکنه و بررسی میکنه که این رشته بهعنوان رشتهی طولانی شناخته نشه.
محاسبهی پوشش کد در این مثال سادهست. تعداد کل خطوط در متد برابر با ۵ خطه (براکتهای باز و بسته هم حساب میشن). تست، ۴ خط از این ۵ خط رو اجرا میکنه—تنها خطی که اجرا نمیشه return true هست. بنابراین، پوشش کد برابر میشه با: ۸۰٪ = ۰.۸ = ۵ ÷ ۴ پوشش کد.
حالا اگه متد رو بازنویسی کنم و شرط اضافی رو بهصورت درونخطی (inline) بنویسم، مثل این:
public static bool IsStringLong(string input)
{
return input.Length > 5;
}
public void Test()
{
bool result = IsStringLong("abc");
Assert.Equal(false, result);
}آیا عدد پوشش کد تغییر میکنه؟ بله، تغییر میکنه. چون حالا تست هر سه خط کد رو اجرا میکنه (عبارت return و دو براکت)، پوشش کد به ۱۰۰٪ افزایش پیدا میکنه.
ولی آیا با این بازنویسی، مجموعه تست رو بهتر کردم؟ قطعاً نه. فقط کد داخل متد رو جابهجا کردم. تست هنوز همون تعداد خروجی ممکن رو بررسی میکنه.
این مثال ساده نشون میده که چقدر راحت میشه عدد پوشش رو دستکاری کرد. هر چی کدت فشردهتر باشه، عدد پوشش بهتر میشه—چون این معیار فقط تعداد خام خطوط رو حساب میکنه. در حالی که فشرده کردن کد، نه ارزش مجموعه تست رو تغییر میده، و نه نگهداری کدبیس رو آسونتر میکنه—و نباید هم اینطور باشه.
۱.۳.۲ درک معیار پوشش شاخهها (Branch Coverage)
یه معیار دیگه برای پوشش تست، پوشش شاخهها (branch coverage) نام داره. این معیار نسبت به پوشش کد دقیقتره، چون به محدودیتهای پوشش کد پاسخ میده. بهجای اینکه فقط تعداد خام خطوط کد رو بشماره، پوشش شاخهها تمرکزش روی ساختارهای کنترلیه—مثل if و switch. این معیار نشون میده که چه تعداد از این ساختارهای کنترلی توسط حداقل یک تست در مجموعه تست اجرا شدن، همونطور که در شکل ۱.۴ نشون داده شده.
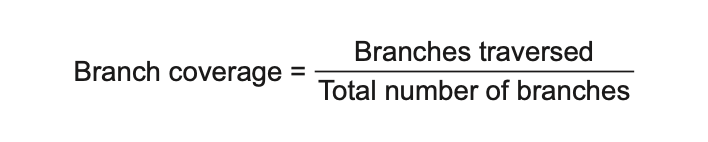
شکل ۱.۴ معیار پوشش شاخهها را نشان میدهد که بهصورت نسبت بین تعداد شاخههای کدی که توسط مجموعه تست اجرا شدهاند و کل شاخههای موجود در کد تولیدی محاسبه میشود.
برای محاسبهی معیار پوشش شاخهها (branch coverage)، باید همهی شاخههای ممکن در کد رو جمع بزنی و ببینی چندتاشون توسط تستها اجرا شدن. بیایم دوباره به مثال قبلیمون برگردیم:
public static bool IsStringLong(string input)
{
return input.Length > 5;
}
public void Test()
{
bool result = IsStringLong("abc");
Assert.Equal(false, result);
}در متد IsStringLong دو شاخه وجود داره: یکی برای حالتی که طول رشته ورودی بیشتر از پنج کاراکتره، و یکی برای حالتی که اینطور نیست. تست فقط یکی از این شاخهها رو پوشش میده، پس معیار پوشش شاخهها برابر میشه با: ۵۰٪ = ۰/۵ = ۱ ÷ ۲. و مهم نیست که کد رو چطور نوشتیم – چه با شرط if مثل قبل، چه با نوشتار کوتاهتر. معیار پوشش شاخهها فقط تعداد شاخهها رو حساب میکنه؛ و کاری نداره که برای پیادهسازی اون شاخهها چند خط کد نوشتیم.
شکل ۱.۵ یه روش مفید برای تصویرسازی این معیار رو نشون میده. میتونی همهی مسیرهای ممکن در کد رو بهصورت یه گراف نمایش بدی و ببینی چندتاشون توسط تستها طی شدن. در متد IsStringLong دو مسیر وجود داره، و تست فقط یکی از اونها رو اجرا میکنه.
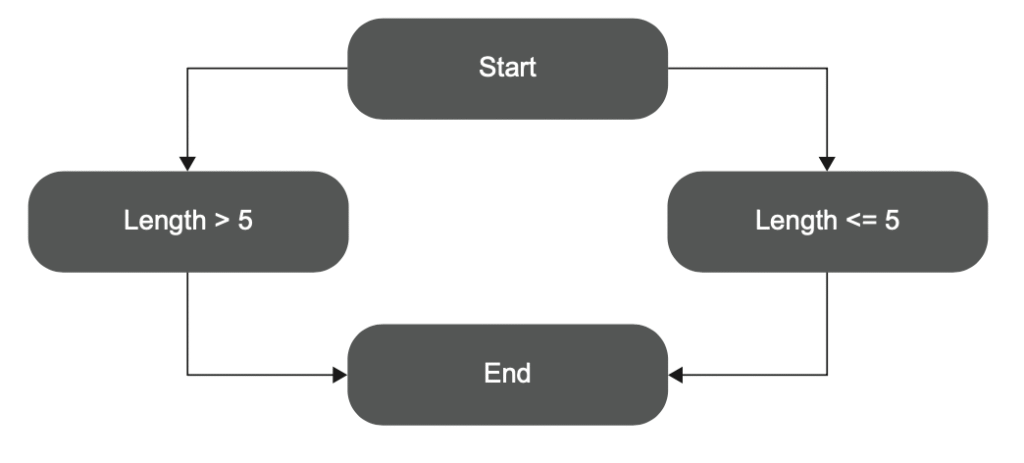
شکل ۱.۵ متد IsStringLong را بهصورت یک نمودار از مسیرهای ممکن در کد نشان میدهد.
تست فقط یکی از دو مسیر ممکن را پوشش میدهد، بنابراین پوشش شاخهها برابر با ۵۰٪ است.
۱.۳.۳ مشکلات معیارهای پوشش
با اینکه معیار پوشش شاخهها نسبت به پوشش کد نتایج دقیقتری میده، اما هنوز هم نمیتونی برای سنجش کیفیت مجموعه تستهات فقط به این معیارها تکیه کنی—به دو دلیل:
- نمیتونی مطمئن باشی که تست، همهی خروجیهای ممکن از سیستم تحت تست رو بررسی میکنه.
- هیچ معیار پوششی نمیتونه مسیرهای کد در کتابخانههای خارجی رو در نظر بگیره.
بیایم هر کدوم از این دلایل رو دقیقتر بررسی کنیم.
نمیتونی تضمین کنی که تست، همهی خروجیهای ممکن رو بررسی میکنه
برای اینکه مسیرهای کد واقعاً تست بشن (و نه فقط اجرا)، تستهای واحد باید شامل assertionهای مناسب باشن. بهعبارت دیگه، باید بررسی کنی که خروجیای که سیستم تحت تست تولید میکنه، دقیقاً همون چیزیه که انتظار داری. علاوه بر این، ممکنه این خروجی چند بخش مختلف داشته باشه و برای اینکه معیارهای پوشش واقعاً معنا داشته باشن، باید همهی این بخشها رو بررسی کنی.
در قطعهکد بعدی، نسخهی دیگهای از متد IsStringLong رو میبینیم که نتیجهی آخر رو در یک ویژگی عمومی به نام WasLastStringLong ذخیره میکنه.
public static bool WasLastStringLong { get; private set; }
public static bool IsStringLong(string input)
{
bool result = input.Length > 5;
WasLastStringLong = result; // اولین اثر متد
return result; // دومین اثر متد
}
public void Test()
{
bool result = IsStringLong("abc");
Assert.Equal(false, result); // تست فقط دومین اثر رو بررسی میکنه
}قطعه کد ۱.۲
متد IsStringLong حالا دو نوع خروجی داره: یکی خروجی صریح (explicit) که از طریق مقدار بازگشتی مشخص میشه، و یکی خروجی ضمنی (implicit) که مقدار جدید ویژگی WasLastStringLong هست. و با اینکه تست، اون خروجی ضمنی دوم رو بررسی نمیکنه، ولی معیارهای پوشش همچنان همون نتایج قبلی رو نشون میدن: ۱۰۰٪ برای پوشش کد و ۵۰٪ برای پوشش شاخهها. همونطور که میبینی، معیارهای پوشش تضمین نمیکنن که کد واقعاً تست شده – فقط نشون میدن که یهجایی، یهبار اجرا شده.
یه نسخهی افراطی از این وضعیت، تست بدون assertion هست – یعنی وقتی تستهایی مینویسی که هیچ عبارت بررسی (assertion) توشون وجود نداره. در ادامه، یه مثال از تست بدون assertion میبینیم.
public void Test()
{
bool result1 = IsStringLong("abc");
bool result2 = IsStringLong("abcdef");
}قطعه کد ۱.۳
این تست هم پوشش کد و هم پوشش شاخهها رو ۱۰۰٪ نشون میده. اما در عین حال، کاملاً بیفایدهست—چون هیچ چیزی رو بررسی نمیکنه.
روایتی از دل پروژهها
ممکنه مفهوم تست بدون assertion در نگاه اول احمقانه بهنظر برسه، اما در دنیای واقعی اتفاق میافته.
سالها پیش روی پروژهای کار میکردم که مدیریت یه الزام سختگیرانه گذاشته بود: تمام پروژههای در حال توسعه باید به پوشش کد ۱۰۰٪ میرسیدن. این تصمیم نیت خوبی داشت—اون زمان تست واحد به اندازهی امروز رایج نبود. تعداد کمی از افراد سازمان تست مینوشتن، و حتی کمتر از اونها بهصورت منظم این کار رو انجام میدادن.
یه گروه از توسعهدهندهها از یه کنفرانس برگشته بودن که توش سخنرانیهای زیادی دربارهی تست واحد برگزار شده بود. بعد از برگشت، تصمیم گرفتن دانش جدیدشون رو عملی کنن. مدیریت هم ازشون حمایت کرد، و موجی از تغییرات مثبت در تکنیکهای برنامهنویسی شروع شد. ارائههای داخلی برگزار شد، ابزارهای جدید نصب شدن، و مهمتر از همه، یه قانون سراسری در شرکت وضع شد: همهی تیمهای توسعه باید فقط روی نوشتن تست تمرکز کنن تا به عدد ۱۰۰٪ پوشش کد برسن. بعد از رسیدن به این هدف، هر کدی که باعث کاهش این عدد میشد، توسط سیستمهای build رد میشد.
همونطور که حدس میزنی، این سیاست نتیجهی خوبی نداشت. توسعهدهندهها زیر فشار این محدودیت شدید، شروع کردن به دور زدن سیستم. خیلیها به یه راهحل مشترک رسیدن: اگه همهی تستها رو با بلاکهای try/catch بنویسی و هیچ assertionی توشون نذاری، اون تستها همیشه موفق میشن. و این شد که افراد شروع کردن به نوشتن تستهای بیهدف، فقط برای اینکه به عدد ۱۰۰٪ برسن. طبیعتاً این تستها هیچ ارزشی برای پروژهها نداشتن. حتی به پروژهها آسیب زدن—هم بهخاطر زمانی که از فعالیتهای مفید منحرف شد، و هم بهخاطر هزینهی نگهداری این تستها در آینده.
در نهایت، اون الزام به ۹۰٪ کاهش پیدا کرد، بعد به ۸۰٪، و بعد از یه مدت، کلاً لغو شد (که تصمیم درستی بود!).
اما فرض کنیم که تمام خروجیهای کد تحت تست را بهطور کامل بررسی کرده باشی. آیا این کار، همراه با معیار پوشش شاخهها، یک مکانیزم قابلاعتماد برای تعیین کیفیت مجموعه تستها فراهم میکنه؟ متأسفانه نه.
هیچ معیار پوششی نمیتونه مسیرهای کد در کتابخانههای خارجی رو در نظر بگیره
دومین مشکل همهی معیارهای پوشش اینه که مسیرهای کدی رو که کتابخانههای خارجی طی میکنن، وقتی سیستم تحت تست متدی از اونها رو فراخوانی میکنه، در نظر نمیگیرن. بیایم مثال زیر رو بررسی کنیم:
public static int Parse(string input)
{
return int.Parse(input);
}
public void Test()
{
int result = Parse("5");
Assert.Equal(5, result);
}معیار پوشش شاخهها عدد ۱۰۰٪ رو نشون میده، و تست هم تمام اجزای خروجی متد رو بررسی میکنه—که در اینجا فقط یه جزء داره: مقدار بازگشتی. اما با این حال، این تست اصلاً جامع نیست.
چون مسیرهای کدی رو که متد int.Parse در چارچوب .NET ممکنه طی کنه، در نظر نمیگیره. و حتی در همین متد ساده، مسیرهای زیادی وجود دارن – همونطور که در شکل ۱.۶ میتونی ببینی.
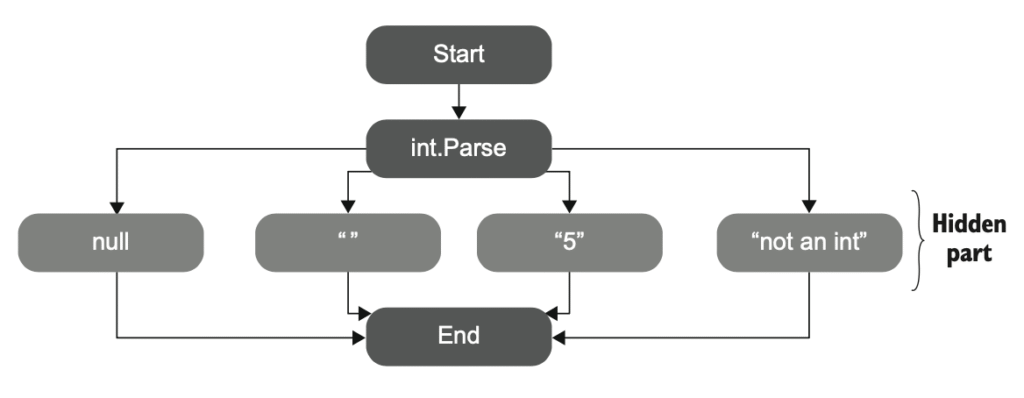
شکل ۱.۶ مسیرهای پنهان در کتابخانههای خارجی را نشان میدهد. معیارهای پوشش هیچ راهی برای دیدن تعداد این مسیرها یا اینکه تستهای شما چندتای آنها را اجرا کردهاند ندارند.
نوع integer موجود در داتنت شاخههای زیادی داره که از دید تست پنهان هستن و ممکنه با تغییر ورودی متد، به نتایج متفاوتی منجر بشن. در ادامه چند نمونه از ورودیهایی رو میبینی که نمیتونن به عدد صحیح تبدیل بشن:
- مقدار
null - رشتهی خالی (
"") - یک رشته
"Not an int" - رشتهای که عددی خیلی بزرگه
ممکنه با تعداد زیادی حالت مرزی (edge case) روبهرو بشی، و هیچ راهی وجود نداره که بفهمی آیا تستهات همهی اونها رو پوشش دادن یا نه.
این حرف به این معنی نیست که معیارهای پوشش باید مسیرهای کد در کتابخانههای خارجی رو در نظر بگیرن—نباید هم بگیرن. بلکه هدف اینه که بدونی نمیتونی برای سنجش خوب یا بد بودن تستهات فقط به این معیارها تکیه کنی. معیارهای پوشش نمیتونن بگن که آیا تستهات جامع هستن یا نه؛ و نمیتونن مشخص کنن که آیا تعداد تستهات کافی هست یا نه.
۱.۳.۴ هدفگذاری برای یک عدد خاص در پوشش تست
در این مرحله، امیدوارم متوجه شده باشی که تکیه بر معیارهای پوشش برای سنجش کیفیت مجموعه تست کافی نیست. حتی میتونه خطرناک هم باشه، مخصوصاً وقتی که یه عدد خاص رو بهعنوان هدف تعیین کنی – چه ۱۰۰٪ باشه، چه ۹۰٪، یا حتی یه مقدار متوسط مثل ۷۰٪. بهترین راه برای نگاهکردن به معیار پوشش اینه که اون رو یه نشانگر بدونی، نه یه هدف مستقل.
مثلاً یه بیمار رو در بیمارستان تصور کن. دمای بالای بدنش ممکنه نشونهی تب باشه و یه مشاهدهی مفید محسوب بشه. اما بیمارستان نباید دمای مناسب بدن اون بیمار رو به هر قیمتی تبدیل به یه هدف کنه. وگرنه ممکنه به یه راهحل سریع و «کارآمد» برسه: نصب یه کولر کنار بیمار و تنظیم دمای بدنش با جریان هوای سرد روی پوستش. طبیعتاً این روش اصلاً منطقی نیست.
بههمین شکل، هدفگذاری برای یه عدد خاص در پوشش تست، یه انگیزهی معیوب ایجاد میکنه که با هدف واقعی تست واحد در تضاده. بهجای تمرکز روی تست چیزهای مهم، افراد دنبال راههایی میگردن تا فقط به اون عدد مصنوعی برسن. تست واحد اصولی خودش بهاندازهی کافی سخت هست. تحمیل یه عدد اجباری برای پوشش، فقط حواس توسعهدهندهها رو پرت میکنه و رسیدن به تست اصولی رو سختتر میکنه.
نکته: خوبه که در بخشهای اصلی سیستم، پوشش بالایی داشته باشی. اما بده که این پوشش بالا تبدیل به یه الزام بشه. این تفاوت ظریفه، اما بسیار مهم.
اجازه بده دوباره تأکید کنم: معیارهای پوشش، نشانگر منفی خوبی هستن، اما اصلا نشانگر مثبت خوبی نیستن. عددهای پایین—مثلاً زیر ۶۰٪—قطعاً نشونهی مشکل هستن. یعنی بخش زیادی از کد تست نشده باقی مونده. اما عددهای بالا هیچ تضمینی نمیدن. بنابراین، اندازهگیری پوشش کد باید فقط اولین قدم در مسیر رسیدن به یه مجموعه تست باکیفیت باشه.
۱.۴ چه چیزی یک مجموعه تست موفق را میسازد؟
تا اینجای فصل، بیشتر دربارهی روشهای نادرست برای سنجش کیفیت مجموعه تست صحبت کردیم—یعنی استفاده از معیارهای پوشش. اما روش درست چیه؟ چطور باید کیفیت مجموعه تستهات رو بسنجی؟ تنها راه قابلاعتماد اینه که هر تست رو بهصورت جداگانه و دقیق ارزیابی کنی—تکبهتک. البته لازم نیست همهی تستها رو یکباره بررسی کنی، این کار ممکنه در ابتدا بسیار زمانبر و سنگین باشه، اما میتونی ارزیابی تستها رو بهصورت تدریجی انجام بدی. نکتهی اصلی اینه که هیچ راه خودکاری برای سنجش کیفیت مجموعه تست وجود نداره. باید از قضاوت شخصی خودت استفاده کنی.
بیایم یه نگاه کلی بندازیم به اینکه چه چیزی باعث موفقیت یک مجموعه تست میشه. (در فصل چهارم، بهطور دقیقتر دربارهی تفاوت تستهای خوب و بد صحبت میکنیم.) یه مجموعه تست موفق این ویژگیها رو داره:
- در چرخهی توسعه ادغام شده باشه.
- فقط بخشهای مهم کد رو هدف قرار بده.
- با کمترین هزینهی نگهداری، بیشترین ارزش رو ارائه بده.
۱.۴.۱ ادغامشدن در چرخهی توسعه
تنها زمانی تستهای خودکار ارزش دارن که بهطور مداوم ازشون استفاده بشه. همهی تستها باید در چرخهی توسعه ادغام شده باشن. در حالت ایدهآل، باید تستها رو با هر تغییر در کد اجرا کنی—حتی اگه اون تغییر خیلی جزئی باشه.
۱.۴.۲ تمرکز بر مهمترین بخشهای پایگاه کد
همانطور که همهی تستها ارزش یکسانی ندارند، همهی بخشهای پایگاه کد هم از نظر تست واحد، به یک اندازه مهم نیستند. ارزش تستها فقط در ساختار خودشان نیست، بلکه در کدی است که آنها بررسی میکنند.
مهمه که تلاشهای تست واحد را به حساسترین بخشهای سیستم اختصاص بدی، و سایر بخشها را فقط بهصورت مختصر یا غیرمستقیم بررسی کنی. در بیشتر برنامهها، مهمترین بخش، بخشی است که منطق تجاری (business logic) را در خود دارد—یعنی مدل دامنه (domain model). تستکردن منطق تجاری، بهترین بازده را برای سرمایهگذاری زمانیات فراهم میکنه.
سایر بخشها را میتوان به سه دسته تقسیم کرد:
- کد زیرساختی (Infrastructure code)
- سرویسها و وابستگیهای خارجی، مثل پایگاه داده و سیستمهای شخص ثالث
- کدی که اجزای مختلف را به هم متصل میکند
برخی از این بخشهای دیگر ممکنه همچنان نیاز به تست واحد دقیق داشته باشن. مثلاً کد زیرساختی ممکنه شامل الگوریتمهای پیچیده و مهمی باشه، پس منطقیه که اونها رو هم با تستهای متعدد پوشش بدی. اما بهطور کلی، بیشتر تمرکزت باید روی مدل دامنه باشه.
برخی از تستهات—مثل تستهای یکپارچهسازی (integration tests) – میتونن فراتر از مدل دامنه برن و بررسی کنن که کل سیستم چطور کار میکنه، حتی شامل بخشهایی از کد که چندان مهم نیستن. و این اشکالی نداره. اما تمرکز اصلی باید همچنان روی مدل دامنه باقی بمونه.
توجه داشته باش که برای پیروی از این راهنما، باید مدل دامنه رو از بخشهای غیرضروری پایگاه کد جدا کنی. باید مدل دامنه رو از سایر دغدغههای برنامه تفکیک کنی تا بتونی تلاشهای تست واحدت رو منحصراً روی همون مدل دامنه متمرکز کنی. در بخش دوم کتاب، همهی این موارد رو بهصورت مفصل بررسی میکنیم.
۱.۴.۳ ارائهی بیشترین ارزش با کمترین هزینهی نگهداری
سختترین بخش تست واحد اینه که بتونی بیشترین ارزش رو با کمترین هزینهی نگهداری بهدست بیاری. و این دقیقاً تمرکز اصلی این کتابه. اینکه تستها رو وارد build system کنی کافی نیست، و اینکه پوشش بالایی برای مدل دامنه داشته باشی هم کافی نیست. باید مطمئن بشی که فقط تستهایی رو نگهداری که ارزششون بهطور قابلتوجهی از هزینهی نگهداریشون بیشتره. این ویژگی آخر رو میشه به دو بخش تقسیم کرد:
- تشخیص تست ارزشمند (و در نتیجه، تست کمارزش)
- نوشتن تست ارزشمند
هرچند این دو مهارت ممکنه مشابه بهنظر برسن، اما ذاتاً با هم فرق دارن. برای تشخیص یه تست باارزش، باید یه چارچوب مرجع داشته باشی. اما برای نوشتن تست باارزش، باید تکنیکهای طراحی کد رو هم بلد باشی. تستهای واحد و کدی که تست میکنن، بهشدت به هم وابستهان. و نمیتونی تستهای باارزش بنویسی، مگر اینکه برای کدی که پوشش میدن هم تلاش قابلتوجهی کرده باشی.
میتونی این تفاوت رو مثل فرق بین تشخیص یه آهنگ خوب و آهنگسازی ببینی. تبدیلشدن به یه آهنگساز، بهمراتب تلاش بیشتری میطلبه نسبت به اینکه فقط بتونی بین موسیقی خوب و بد تفاوت بذاری. در مورد تست واحد هم همینطوره. نوشتن یه تست جدید، از بررسی یه تست موجود سختتره – چون تست رو در خلأ نمینویسی؛ باید کد زیربنایی رو هم در نظر بگیری. و به همین دلیل، با اینکه تمرکز کتاب روی تست واحده، بخش قابلتوجهی از اون به بحث طراحی کد اختصاص داده شده.
۱.۵ چه چیزهایی از این کتاب یاد میگیری؟
این کتاب یه چارچوب تحلیلی بهت آموزش میده که میتونی باهاش هر تستی رو در مجموعه تستهات بررسی کنی. این چارچوب، پایهای و بنیادینه. بعد از یادگیریش، میتونی با دیدی تازه به تستهات نگاه کنی و تشخیص بدی کدومها واقعاً به پروژه کمک میکنن و کدومها باید بازنویسی یا حذف بشن.
بعد از آمادهسازی این بستر (در فصل ۴)، کتاب میره سراغ تحلیل تکنیکها و روشهای موجود در تست واحد (در فصلهای ۴ تا ۶ و بخشی از فصل ۷). مهم نیست که قبلاً با این تکنیکها آشنا باشی یا نه. اگه آشنا باشی، اونها رو از زاویهای جدید خواهی دید. احتمالاً تا حالا بهصورت شهودی باهاشون کنار اومدی، اما این کتاب کمکت میکنه بفهمی چرا این تکنیکها و بهترینروشها واقعاً مفید هستن.
این مهارت رو دستکم نگیر. توانایی اینکه بتونی ایدههات رو بهوضوح برای همتیمیهات توضیح بدی، بینهایت ارزشمنده. یه توسعهدهنده—حتی اگه خیلی حرفهای باشه— معمولاً تا وقتی نتونه دقیقاً توضیح بده چرا یه تصمیم طراحی گرفته شده، اعتبار کامل اون تصمیم رو نمیگیره. این کتاب کمکت میکنه دانش فعلیت رو از حالت ناخودآگاه به چیزی تبدیل کنی که بتونی با هر کسی دربارهش صحبت کنی.
اگه تجربهی زیادی در تکنیکها و بهترینروشهای تست واحد نداری، مطالب زیادی از این کتاب یاد میگیری. علاوه بر چارچوب تحلیلیای که میتونی باهاش هر تستی رو در مجموعهت بررسی کنی، این کتاب بهت یاد میده:
- چطور مجموعه تست رو همراه با کد تولیدیای که پوشش میده، بازآرایی (refactor) کنی
- چطور سبکهای مختلف تست واحد رو بهکار ببری
- چطور از تستهای یکپارچهسازی (integration tests) برای بررسی رفتار کل سیستم استفاده کنی
- چطور الگوهای ضدتست (anti-patterns) رو در تستهای واحد شناسایی و ازشون پرهیز کنی
علاوه بر تستهای واحد، این کتاب کل موضوع تست خودکار رو پوشش میده، پس دربارهی تستهای یکپارچهسازی و سرتاسری (end-to-end) هم یاد میگیری. من در نمونهکدها از سیشارپ و داتنت استفاده میکنم، اما لازم نیست متخصص سیشارپ باشی تا بتونی این کتاب رو بخونی؛ سیشارپ فقط زبانیه که بیشتر باهاش کار میکنم. همهی مفاهیمی که مطرح میکنم، مستقل از زبان هستن و میتونن در هر زبان شیءگرا مثل Java یا ++C هم بهکار برن.
۱.۶ خلاصه
- کد بهمرور زمان دچار فرسایش میشه. هر بار که چیزی رو در پایگاه کد تغییر میدی، میزان بینظمی یا آنتروپی اون بیشتر میشه. بدون مراقبت مداوم—مثل پاکسازی و بازآرایی (refactoring)—سیستم پیچیدهتر و آشفتهتر میشه. تستها به مقابله با این روند کمک میکنن؛ مثل یه تور ایمنی هستن (Safety net) که جلوی بیشتر خطاهای برگشتی (regression) رو میگیرن.
- نوشتن تست واحد مهمه؛ نوشتن تست واحد خوب هم بههمون اندازه مهمه. نتیجهی نهایی در پروژههایی که تستهای بد یا بدون تست دارن یکیه: یا رکود، یا خطاهای برگشتی زیاد در هر نسخهی جدید.
- هدف تست واحد اینه که رشد پایدار پروژهی نرمافزاری رو ممکن کنه. یه مجموعه تست خوب کمک میکنه از مرحلهی رکود جلوگیری بشه و سرعت توسعه در طول زمان حفظ بشه. با چنین مجموعهای، مطمئن هستی که تغییراتت باعث خطای برگشتی نمیشن—و این باعث میشه ریفکتور کردن یا افزودن قابلیتهای جدید راحتتر بشه.
- همهی تستها ارزش یکسانی ندارن. هر تست یه هزینه و یه فایده داره، و باید این دو رو با دقت بسنجی. فقط تستهایی رو نگهدار که ارزش خالص مثبتی دارن، و بقیه رو حذف کن. هم کد برنامه و هم کد تست، دارایی نیستن—بلکه بدهی هستن.
- توانایی تستپذیری کد یه معیار خوبه، اما فقط در یه جهت. این یه نشانگر منفی خوبه (اگه نتونی برای کدت تست واحد بنویسی، کیفیتش پایینه)، ولی نشانگر مثبت بدیه (اینکه بتونی تست واحد بنویسی، تضمینی برای کیفیت کد نیست).
- همینطور، معیارهای پوشش تست هم نشانگر منفی خوبی هستن اما نشانگر مثبت بدی هستن. عددهای پایین قطعاً نشونهی مشکل هستن، ولی عددهای بالا لزوماً نشونهی کیفیت بالا نیستن.
- پوشش شاخهها (branch coverage) دید بهتری نسبت به کاملبودن مجموعه تست میده، اما باز هم نمیتونه تعیین کنه که آیا مجموعه تست بهاندازهی کافی خوب هست یا نه. این معیار وجود assertionها رو در نظر نمیگیره، و مسیرهای کد در کتابخانههای شخص ثالث رو هم نمیتونه پوشش بده.
- تحمیل یه عدد خاص برای پوشش تست، انگیزههای معیوب ایجاد میکنه. داشتن پوشش بالا در بخشهای اصلی سیستم خوبه، اما تبدیلکردن اون به یه الزام، اشتباهه.
- یه مجموعه تست موفق این ویژگیها رو داره:
- در چرخهی توسعه ادغام شده باشه
- فقط بخشهای مهم پایگاه کد رو هدف قرار بده
- با کمترین هزینهی نگهداری، بیشترین ارزش رو ارائه بده
- تنها راه رسیدن به هدف تست واحد (یعنی رشد پایدار پروژه) اینه که:
- یاد بگیری چطور بین تست خوب و بد تفاوت بذاری
- بتونی تست رو بازآرایی (refactor) کنی تا ارزشمندتر بشه