
این فصل شامل موارد زیر است:
- تعریف تست واحد
- تفاوت بین وابستگیهای مشترک (shared)، خصوصی (private)، و ناپایدار (volatile)
- دو مکتب تست واحد: کلاسیک و لندن
- تفاوت بین تست واحد، تست یکپارچهسازی (integration)، و تست سرتاسری (end-to-end)
همونطور که تو فصل قبل گفته شد، تعریف تست واحد اونقدرها هم ساده نیست. یهسری تفاوتهای ظریف داره که بیشتر از چیزی که فکر میکنی مهمن— تا جایی که همین تفاوتها باعث شده دو سبک کاملاً متفاوت برای تست واحد شکل بگیره.
یکی سبک کلاسیکه، همون روشی که اول همه باهاش تست واحد و TDD رو شروع کردن. یکی هم سبک لندن، که از جامعهی برنامهنویسی لندن ریشه گرفته. این فصل قراره تفاوتهای این دو سبک رو بررسی کنه، و برای فصل پنجم زمینهسازی کنه، جایی که مفصل دربارهی mockها و شکنندگی تستها صحبت میکنیم.
بیایم از تعریف تست واحد شروع کنیم—با همهی ظرافتها و تبصرههایی که همراهشه. چون همین تعریف، کلید تفاوت بین سبک کلاسیک و سبک لندن در تست واحده.
۲.۱ تعریف تست واحد (Unit Test)
تعریفهای زیادی برای تست واحد وجود داره. اما اگه بخشهای غیرضروریشون رو کنار بذاریم، همهی اونها به سه ویژگی اصلی میرسن:
تست واحد، یه تست خودکاره که:
- یه بخش کوچک از کد رو بررسی میکنه (که بهش unit هم گفته میشه)
- این کار رو سریع انجام میده
- و بهصورت ایزوله انجامش میده
دو ویژگی اول معمولاً محل بحث نیستن. ممکنه دربارهی اینکه دقیقاً چه تستی «سریع» حساب میشه اختلاف نظر باشه، چون سرعت یه معیار کاملاً نسبیه. ولی در کل، اونقدرها مهم نیست – اگه زمان اجرای مجموعه تستهات برای خودت قابلقبوله، یعنی تستهات بهاندازهی کافی سریع هستن.
اما چیزی که واقعاً اختلافنظر زیادی دربارهش وجود داره، همون ویژگی سومه: ایزولهبودن. مسئلهی ایزولهسازی، ریشهی تفاوت بین سبک کلاسیک و سبک لندن در تست واحده. همونطور که در بخش بعدی خواهی دید، همهی تفاوتهای دیگه بین این دو سبک، از همین اختلاف دربارهی معنی دقیق «ایزولهبودن» سرچشمه میگیرن. من خودم طرفدار سبک کلاسیکم—دلایلش رو در بخش ۲.۳ توضیح میدم.
مکتبهای کلاسیک و لندن در تست واحد
سبک کلاسیک، گاهی با نام دیترویت (Detroit) یا کلاسیکیست (classicist) هم شناخته میشه. احتمالاً معروفترین کتابی که این سبک رو نمایندگی میکنه، کتاب Test-Driven Development: By Example نوشتهی Kent Beck هست (انتشارات Addison-Wesley، سال ۲۰۰۲).
سبک لندن گاهی با عنوان mockist هم شناخته میشه. هرچند این اصطلاح رایجه، ولی خیلی از طرفدارهای این سبک باهاش راحت نیستن – برای همین، توی این کتاب من بهش میگم سبک لندن. دو نفر از چهرههای شاخص این رویکرد، Steve Freeman و Nat Pryce هستن. کتابشون با عنوان Growing Object-Oriented Software, Guided by Tests (انتشارات Addison-Wesley، سال ۲۰۰۹) منبع خوبی برای آشنایی با این سبک محسوب میشه.
۲.۱.۱ مسئلهی ایزولهسازی: دیدگاه لندن
ایزولهبودن یعنی چی؟ یعنی وقتی میخوای یه بخش از کد—یه unit—رو تست کنی، اون رو از بقیهی اجزای سیستم جدا کنی. سبک لندن اینطور تعریفش میکنه: باید سیستم تحت تست رو از همکارهاش جدا کنی. یعنی اگه یه کلاس به کلاسهای دیگه وابسته باشه – چه یکی، چه چندتا – باید همهی اون وابستگیها رو با test doubleها جایگزین کنی. با این کار، میتونی فقط روی همون کلاس تمرکز کنی، بدون اینکه رفتارش تحت تأثیر عوامل خارجی قرار بگیره.
تعریف:
یک Test Double (جایگزین تست) شیئ هست که ظاهر و رفتارش شبیه نسخهی واقعیایه که قراره در محصول نهایی استفاده بشه، اما در واقع یه نسخهی سادهشدهست که پیچیدگی رو کم میکنه و تستکردن رو آسونتر میکنه. این اصطلاح رو Gerard Meszaros توی کتاب xUnit Test Patterns: Refactoring Test Code (انتشارات Addison-Wesley، سال ۲۰۰۷) معرفی کرده. خود اسمش هم از دنیای سینما گرفته شده—جایی که stunt doubleها (بدلکارها) نقش نسخهی جایگزین بازیگر اصلی رو دارن.
شکل ۲.۱ نشون میده که ایزولهسازی معمولاً چطور انجام میشه. تستی که در حالت عادی قراره سیستم تحت تست رو همراه با همهی وابستگیهاش بررسی کنه، حالا میتونه این کار رو جدا از اون وابستگیها انجام بده.
یکی از مزیتهای این رویکرد اینه که اگه تست fail بشه، کاملاً مشخصه که مشکل از کجاست: از خود سیستم تحت تست. هیچ مظنون دیگهای وجود نداره، چون همهی کلاسهای اطراف با test double جایگزین شدن.
یه مزیت دیگهش اینه که میتونی گراف اشیاء رو جدا کنی – همون شبکهای از کلاسهایی که با هم ارتباط دارن و دارن یه مسئلهی مشترک رو حل میکنن. این شبکه ممکنه خیلی پیچیده بشه: هر کلاس ممکنه چندتا وابستگی مستقیم داشته باشه، و هر کدوم از اون وابستگیها هم خودشون به چیزهای دیگه وابسته باشن، و همینطور ادامه پیدا کنه. حتی ممکنه کلاسها وابستگیهای حلقهای ایجاد کنن – جایی که زنجیرهی وابستگی در نهایت دوباره برمیگرده به نقطهی شروع.
تستکردن یه پایگاه کد درهمتنیده، بدون استفاده از test doubleها واقعاً سخت میشه. تقریباً تنها راهی که برات میمونه اینه که کل گراف اشیاء رو توی تست بازسازی کنی – که اگه تعداد کلاسها زیاد باشه، اصلاً کار عملیای نیست.
اما با test doubleها میتونی جلوی این مشکل رو بگیری. میتونی وابستگیهای مستقیم یه کلاس رو جایگزین کنی؛ و در نتیجه، دیگه لازم نیست با وابستگیهای اون وابستگیها هم درگیر بشی – و همینطور تا پایین مسیر بازگشتی. در واقع داری گراف رو تکهتکه میکنی – و این میتونه مقدار آمادگیای که برای نوشتن یه تست واحد لازم داری رو بهشدت کم کنه.
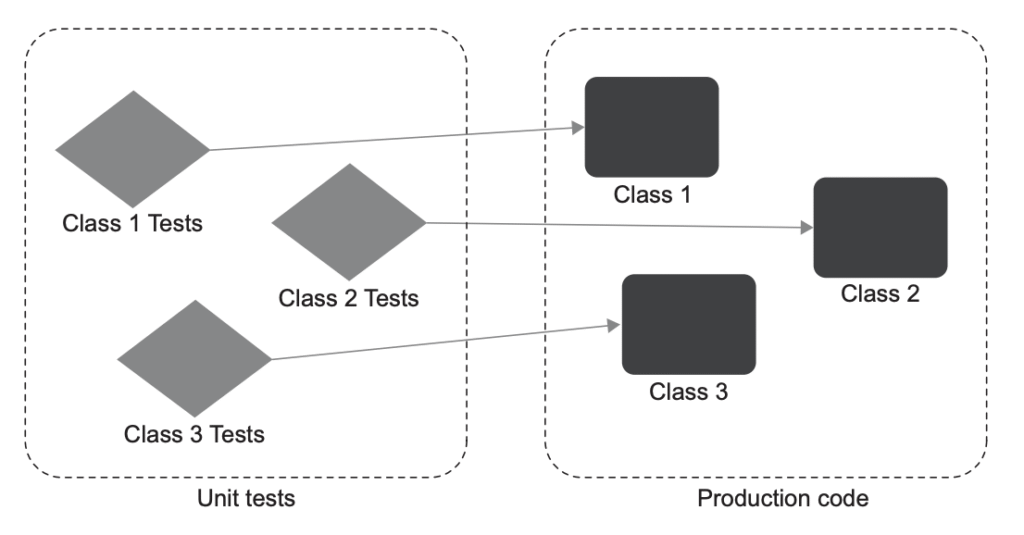
و یه نکتهی کوچیک ولی خوشایند دیگه از این رویکرد ایزولهسازی: میتونی یه قانون سادهی سراسری برای پروژه تعریف کنی: هر بار فقط یه کلاس رو تست کن. این باعث میشه ساختار مجموعه تستهات ساده و قابلپیشبینی بشه. دیگه لازم نیست زیاد فکر کنی که چطور باید پایگاه کدت رو با تست پوشش بدی. یه کلاس داری؟ یه کلاس تست براش بساز! شکل ۲.۲ نشون میده که این ساختار معمولاً چه شکلیه.
بیایم چند مثال ببینیم. چون سبک کلاسیک برای بیشتر آدمها آشناتر به نظر میرسه، اول چند تست نمونه با همین سبک نشون میدم، و بعد همونها رو با رویکرد لندن بازنویسی میکنم.
فرض کنیم یه فروشگاه آنلاین داریم. توی اپلیکیشن نمونهمون فقط یه سناریوی ساده وجود داره: مشتری میتونه یه محصول رو بخره. اگه موجودی کافی توی فروشگاه باشه، خرید موفق حساب میشه و مقدار محصول موجود بهاندازهی خرید کم میشه. اگه موجودی کافی نباشه، خرید ناموفق میشه و هیچ تغییری در فروشگاه اتفاق نمیافته.
کد ۲.۱ دو تست رو نشون میده که بررسی میکنن خرید فقط وقتی موفقه که موجودی کافی وجود داشته باشه. این تستها با سبک کلاسیک نوشته شدن و از ساختار سهمرحلهای معروف استفاده میکنن: آمادهسازی، اجرا، و بررسی نتیجه (که بهش Arrange, Act, Assert یا به اختصار AAA هم میگن—توی فصل ۳ بیشتر دربارهش صحبت میکنم).
[Fact]
public void Purchase_succeeds_when_enough_inventory()
{
// Arrange
var store = new Store();
store.AddInventory(Product.Shampoo, 10);
var customer = new Customer();
// Act
bool success = customer.Purchase(store, Product.Shampoo, 5);
// Assert
Assert.True(success);
Assert.Equal(5, store.GetInventory(Product.Shampoo)); // تعداد محصول در انبار ۵ تا کم میشه
}
[Fact]
public void Purchase_fails_when_not_enough_inventory()
{
// Arrange
var store = new Store();
store.AddInventory(Product.Shampoo, 10);
var customer = new Customer();
// Act
bool success = customer.Purchase(store, Product.Shampoo, 15);
// Assert
Assert.False(success);
Assert.Equal(10, store.GetInventory(Product.Shampoo)); // تعداد محصول در انبار بدون تغییر باقی می مونه
}
public enum Product
{
Shampoo,
Book
}کد ۲.۱ – تست به سبک طرز فکر کلاسیک نوشته شده
همونطور که میبینی، بخش arrange جاییه که تستها همهی وابستگیها و خود سیستم تحت تست رو آماده میکنن. فراخوانی متد customer.Purchase() میشه مرحلهی act—جایی که رفتاری رو اجرا میکنی که میخوای بررسیش کنی. و در نهایت، دستورات assert مرحلهی assert هستن—جایی که بررسی میکنی آیا نتیجهی رفتار با چیزی که انتظار داشتی یکی بوده یا نه.
توی مرحلهی arrange، تستها دو نوع شیء رو کنار هم میذارن:
- سیستم تحت تست (SUT)، که اینجا کلاس
Customerهست - و یه همکار (collaborator)، که اینجا کلاس
Storeمحسوب میشه
ما به این همکار به دو دلیل نیاز داریم:
- اول اینکه متد
customer.Purchase()برای کامپایلشدن نیاز به یه نمونه ازStoreداره - دوم اینکه توی مرحلهی assert، یکی از نتایج مورد انتظار اینه که مقدار محصول توی فروشگاه کم بشه— پس باید بتونیم وضعیت فروشگاه رو بررسی کنیم
در ضمن،Product.Shampooو عددهای ۵ و ۱۵ هم ثابتهایی هستن که توی تست استفاده میشن.
تعریف:
یک Method Under Test (MUT) یا «متد تحت تست»، همون متدیه که توی تست فراخوانی میشه و متعلق به سیستم تحت تست System Under Test (SUT) هست.
اصطلاحهای MUT و SUT گاهی بهجای هم استفاده میشن، ولی بهطور دقیقتر، MUT به یه متد اشاره داره، در حالی که SUT کل کلاس رو شامل میشه.
این کد یه نمونه از سبک کلاسیک در تست واحده: تست، کلاس همکار (Store) رو با test double جایگزین نمیکنه، بلکه از یه نمونهی واقعی و آماده برای تولید استفاده میکنه. یکی از پیامدهای طبیعی این سبک اینه که تست، در عمل داره هم Customer رو بررسی میکنه و هم Store رو—نه فقط Customer. اگه توی پیادهسازی داخلی Store مشکلی باشه که روی Customer تأثیر بذاره، تست fail میشه حتی اگر Customer خودش درست کار کنه. یعنی این دو کلاس توی تستها از هم ایزوله نیستن.
حالا بیایم همین مثال رو به سبک لندن بازنویسی کنیم. تستها همون هستن، فقط این بار بهجای استفاده از نمونهی واقعی Store، از test double استفاده میکنیم—بهطور خاص، از mockها. برای ساخت mock از فریمورک Moq استفاده میکنم. البته گزینههای خوب دیگهای هم هستن، مثل NSubstitute. تقریباً همهی زبانهای شیگرا فریمورکهای مشابهی دارن. مثلاً توی دنیای Java میتونی از Mockito، JMock یا EasyMock استفاده کنی.
تعریف: Mock نوع خاصی از test double هست که بهت اجازه میده تعاملات بین سیستم تحت تست (SUT) و همکارهاش رو بررسی کنی.
ما توی فصلهای بعدی دوباره به موضوع mock، stub و تفاوتهاشون برمیگردیم. اما فعلاً چیزی که باید یادت بمونه اینه که mock فقط یکی از انواع test doubleهاست. خیلی وقتها این دو اصطلاح بهجای هم استفاده میشن، ولی از نظر فنی، یکی نیستن (توی فصل ۵ بیشتر توضیح میدم):
- اصطلاح Test double یه اصطلاح کلیه که به هر نوع وابستگی غیرواقعی و غیرقابلاستفاده در محیط تولید اشاره داره—چیزی که فقط برای تست ساخته شده
- تکنیکMock فقط یکی از این نوع وابستگیهاست
در ادامه، کدی رو میبینی که همون تستها رو نشون میده، اما این بار Customer از همکارش (Store) ایزوله شده.
[Fact]
public void Purchase_succeeds_when_enough_inventory()
{
// Arrange
var storeMock = new Mock();
storeMock.Setup(x => x.HasEnoughInventory(Product.Shampoo, 5)).Returns(true);
var customer = new Customer();
// Act
bool success = customer.Purchase( storeMock.Object, Product.Shampoo, 5);
// Assert
Assert.True(success);
storeMock.Verify(x => x.RemoveInventory(Product.Shampoo, 5), Times.Once);
}
[Fact]
public void Purchase_fails_when_not_enough_inventory()
{
// Arrange
var storeMock = new Mock();
storeMock.Setup(x => x.HasEnoughInventory(Product.Shampoo, 5)) .Returns(false);
var customer = new Customer();
// Act
bool success = customer.Purchase( storeMock.Object, Product.Shampoo, 5);
// Assert
Assert.False(success);
storeMock.Verify( x => x.RemoveInventory(Product.Shampoo, 5), Times.Never);
}کد ۲.۲ – تست به سبک طرز فکر لندن نوشته شده
توجه کن که این تستها چقدر با تستهای سبک کلاسیک فرق دارن. توی مرحلهی arrange، دیگه از نمونهی واقعی Store استفاده نمیکنیم، بلکه با استفاده از کلاس داخلی Mock<T> در فریمورک Moq، یه جایگزین براش میسازیم.
علاوه بر این، بهجای اینکه وضعیت Store رو تغییر بدیم – مثلاً با اضافهکردن موجودی شامپو – مستقیماً به mock میگیم که وقتی متد HasEnoughInventory() صدا زده شد، چه پاسخی بده. mock دقیقاً همونطور که تستها نیاز دارن واکنش نشون میده، بدون توجه به وضعیت واقعی کلاس Store. در واقع، دیگه اصلاً از خود Store استفاده نمیکنیم – یه interface به اسم IStore معرفی کردیم و حالا داریم اون رو mock میکنیم، نه کلاس Store رو.
توی فصل ۸ مفصل دربارهی کار با interfaceها صحبت میکنم. فعلاً فقط این نکته رو بهخاطر بسپار: برای اینکه سیستم تحت تست رو از همکارهاش ایزوله کنی، استفاده از interfaceها ضروریه. (البته میتونی یه کلاس واقعی رو هم mock کنی، ولی این کار یه anti-pattern محسوب میشه—توی فصل ۱۱ بیشتر دربارهش توضیح میدم.)
مرحلهی assert هم تغییر کرده—و همینجاست که تفاوت اصلی بین سبک کلاسیک و لندن خودش رو نشون میده. ما هنوز خروجی متد customer.Purchase() رو بررسی میکنیم، اما نحوهی تأیید اینکه آیا Customer رفتار درستی نسبت به Store داشته، فرق کرده. قبلاً این کار رو با بررسی وضعیت نهایی Store انجام میدادیم—مثلاً اینکه موجودی محصول کم شده یا نه. اما حالا داریم تعامل بین Customer و Store رو بررسی میکنیم. تستها چک میکنن که آیا Customer متد درست رو روی Store صدا زده یا نه. برای این کار، مشخص میکنیم که:
- کدوم متد باید صدا زده بشه (مثلاً
x.RemoveInventory) - و چند بار باید این اتفاق بیفته
اگه خرید موفق باشه، انتظار داریم کهRemoveInventoryیک بار صدا زده بشه (Times.Once)
اگه خرید ناموفق باشه، نباید اصلاً صدا زده بشه (Times.Never)
۲.۱.۲ مسئلهی ایزولهسازی: برداشت کلاسیک
برای یادآوری، سبک لندن نیاز به ایزولهسازی رو اینطور برآورده میکنه: با جدا کردن قطعهی کد تحت تست از همکارهاش، به کمک test doubleها—بهطور خاص، mockها. جالب اینجاست که این دیدگاه، روی برداشتت از اینکه «بخش کوچک از کد» یا همون unit دقیقاً چیه هم تأثیر میذاره. بیایم ویژگیهای یه تست واحد رو دوباره مرور کنیم:
- تست واحد یه بخش کوچک از کد رو بررسی میکنه (unit)
- این کار رو سریع انجام میده
- و بهصورت ایزوله انجامش میده
علاوه بر اینکه ویژگی سوم (ایزولهسازی) جای تفسیر داره، ویژگی اول هم میتونه برداشتهای مختلفی داشته باشه. اون «بخش کوچک از کد» دقیقاً چقدر باید کوچک باشه؟ همونطور که توی بخش قبلی دیدی، اگه دیدگاهت این باشه که هر کلاس باید بهتنهایی ایزوله بشه، طبیعیه که بپذیری بخش تحت تست هم باید یه کلاس باشه—یا یه متد داخل اون کلاس. بیشتر از این نمیتونه باشه، چون نوع نگاهت به مسئلهی ایزولهسازی این محدودیت رو ایجاد میکنه. توی بعضی موارد ممکنه چند کلاس رو با هم تست کنی؛ اما در حالت کلی، همیشه سعی میکنی این اصل رو حفظ کنی: تست واحد برای هر بار فقط یه کلاس.
همونطور که قبلاً اشاره کردم، یه برداشت دیگه هم از ویژگی ایزولهسازی وجود داره – برداشت کلاسیک. توی رویکرد کلاسیک، این خود کد نیست که باید بهصورت ایزوله تست بشه. بلکه تستهای واحد باید از همدیگه ایزوله باشن. با این کار، میتونی تستها رو به هر شکلی که خواستی اجرا کنی – بهصورت موازی، پشتسرهم، یا با هر ترتیبی که برات مناسبتره – و همچنان مطمئن باشی که نتیجهی هیچ تستی روی تستهای دیگه تأثیر نمیذاره.
ایزولهکردن تستها از همدیگه یعنی اشکالی نداره چند کلاس رو همزمان تست کنی، بهشرطی که همهشون فقط توی حافظه باشن و به یه وضعیت مشترک (shared state) دسترسی نداشته باشن – وضعیتی که از طریقش تستها بتونن با هم ارتباط برقرار کنن یا روی زمینهی اجرای همدیگه تأثیر بذارن. نمونههای رایج از این وضعیتهای مشترک، وابستگیهای خارج از فرآیند هستن – مثل پایگاه داده، سیستم فایل، و موارد مشابه.
مثلاً یه تست ممکنه توی مرحلهی arrange خودش، یه مشتری توی پایگاه داده بسازه؛ و یه تست دیگه، قبل از اینکه تست اول کامل اجرا بشه، همون مشتری رو توی مرحلهی arrange خودش حذف کنه. اگه این دو تست رو بهصورت موازی اجرا کنی، تست اول fail میشه – نه بهخاطر اینکه کد اصلی مشکل داره، بلکه بهخاطر اینکه تست دوم توی اجرای تست اول اختلال ایجاد کرده.
وابستگیهای مشترک (Shared)، خصوصی (private)، و خارج از فرآیند (out-of-process)
- وابستگی مشترک (Shared Dependency):
وابستگیایه که بین تستها مشترکه و باعث میشه تستها بتونن روی نتیجهی همدیگه تأثیر بذارن. یه مثال رایجش، فیلدstaticقابل تغییره—هر تغییری توی این فیلد برای همهی تستهایی که توی یه فرآیند اجرا میشن قابل مشاهدهست. پایگاه داده هم یه نمونهی دیگه از وابستگی مشترکه. - وابستگی خصوصی (Private Dependency):
وابستگیایه که بین تستها مشترک نیست—یعنی هر تست نسخهی خودش رو داره و نمیتونه روی تستهای دیگه تأثیر بذاره. - وابستگی خارج از فرآیند (Out-of-Process Dependency):
وابستگیایه که خارج از فرآیند اجرایی اپلیکیشن اجرا میشه—در واقع یه واسطهست برای دادههایی که هنوز وارد حافظهی برنامه نشدن. بیشتر وقتها، وابستگیهای خارج از فرآیند، وابستگیهای مشترک هم هستن؛ اما نه همیشه. مثلاً پایگاه داده هم خارج از فرآینده و هم مشترک. ولی اگه قبل از هر اجرای تست، اون پایگاه داده رو توی یه کانتینر Docker راهاندازی کنی، اون وابستگی دیگه مشترک نیست—چون تستها دیگه با یه نمونهی واحد کار نمیکنن. بهطور مشابه، یه پایگاه دادهی فقطخواندنی هم خارج از فرآینده ولی مشترک نیست، حتی اگه بین تستها باز استفاده بشه—چون تستها نمیتونن دادههاش رو تغییر بدن و بنابراین نمیتونن روی نتیجهی همدیگه تأثیر بذارن.
این برداشت از مسئلهی ایزولهسازی، دید خیلی متواضعتری نسبت به استفاده از mockها و سایر test doubleها ارائه میده. هنوز هم میتونی ازشون استفاده کنی، اما معمولاً فقط برای اون دسته از وابستگیهایی که یه وضعیت مشترک بین تستها ایجاد میکنن. یعنی فقط وقتی از test double استفاده میکنی که اون وابستگی ممکنه باعث بشه تستها روی نتیجهی همدیگه تأثیر بذارن. شکل ۲.۳ نشون میده این ساختار چطور به نظر میرسه.
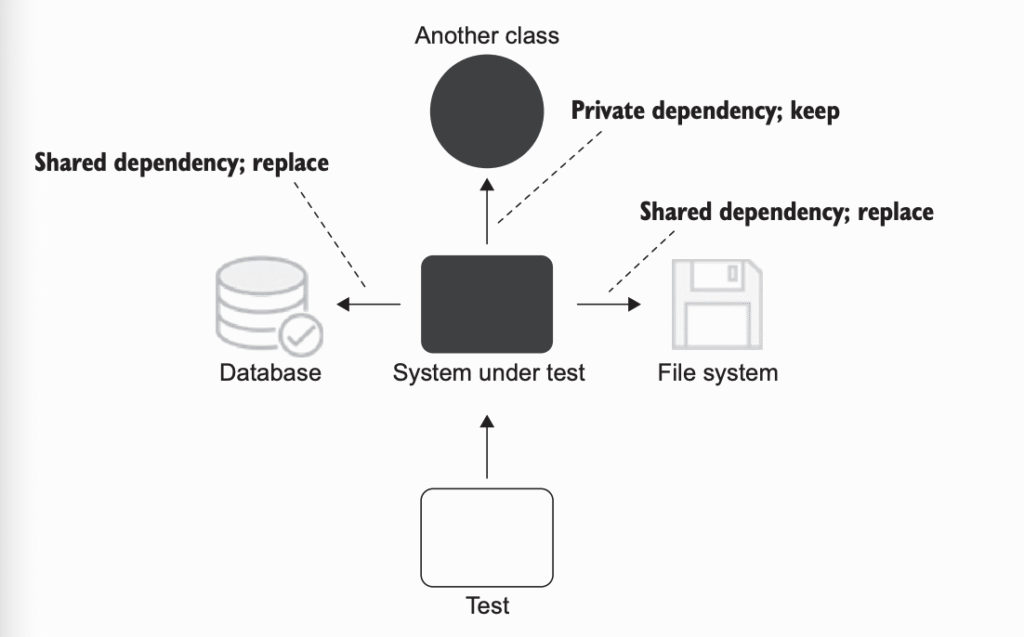
دقت کن که وابستگی مشترک، بین تستهای واحد مشترکه، نه بین کلاسهای تحت تست. از این منظر، یه وابستگی singleton لزوماً مشترک محسوب نمیشه – بهشرطی که توی هر تست بتونی یه نمونهی جدید ازش بسازی. درسته که توی کد تولیدی فقط یه نمونه از singleton وجود داره، اما تستها لزوماً مجبور نیستن از همون الگو پیروی کنن یا اون singleton رو بازاستفاده کنن. در نتیجه، چنین وابستگیای توی تستها خصوصی (private) حساب میشه، چون بین تستها به اشتراک گذاشته نشده.
مثلاً معمولاً فقط یه نمونه از کلاس پیکربندی (configuration) وجود داره که توی کل کد تولیدی (production) استفاده میشه. اما اگه این کلاس مثل بقیهی وابستگیها—مثلاً از طریق constructor—به سیستم تحت تست تزریق بشه، میتونی توی هر تست یه نمونهی جدید ازش بسازی؛ لزومی نداره توی کل تستها از یه نمونهی واحد استفاده کنی. در مقابل، نمیتونی برای هر تست یه فایلسیستم یا پایگاه دادهی جدید بسازی؛ این نوع وابستگیها یا باید بین تستها مشترک باشن، یا باید با test doubleها جایگزین بشن.
وابستگیهای مشترک در برابر وابستگیهای ناپایدار (volatile)
یه اصطلاح دیگه هم هست که معنای مشابهی داره، ولی دقیقاً یکی نیست:
وابستگی ناپایدار (volatile dependency) برای درک بهتر این موضوع، کتاب زیر رو پیشنهاد میکنم:
Dependency Injection: Principles, Practices, Patterns نوشتهی Steven van Deursen و Mark Seemann (انتشارات Manning، سال ۲۰۱۸)
وابستگی ناپایدار، وابستگیایه که یکی از ویژگیهای زیر رو داشته باشه:
- نیاز به راهاندازی و پیکربندی محیط اجرایی داره، فراتر از چیزهایی که بهطور پیشفرض روی سیستم توسعهدهنده نصب شده. پایگاه دادهها و سرویسهای API مثالهای خوبی هستن—چون نیاز به تنظیمات اضافه دارن و معمولاً بهصورت پیشفرض روی سیستمهای سازمان نصب نیستن.
- رفتار غیرقطعی (nondeterministic) داره. مثلاً تولیدکنندهی عدد تصادفی یا کلاسی که تاریخ و زمان فعلی رو برمیگردونه. این نوع وابستگیها غیرقطعی هستن چون هر بار خروجی متفاوتی تولید میکنن.
همونطور که میبینی، بین وابستگیهای مشترک و ناپایدار یه همپوشانی وجود داره. مثلاً وابستگی به پایگاه داده هم مشترکه و هم ناپایدار. اما این موضوع برای فایلسیستم صدق نمیکنه – فایلسیستم ناپایدار نیست چون روی همهی سیستمهای توسعه نصب شده و در اکثر موارد رفتار قطعی داره. با این حال، فایلسیستم یه راه ارتباطی بین تستها فراهم میکنه که میتونه باعث تداخل در زمینهی اجرای تستها بشه؛ پس همچنان یه وابستگی مشترک محسوب میشه. از طرف دیگه، تولیدکنندهی عدد تصادفی ناپایدار هست، اما چون میتونی برای هر تست یه نمونهی جداگانه ازش بسازی، مشترک نیست.
یه دلیل دیگه برای جایگزینکردن وابستگیهای مشترک، افزایش سرعت اجرای تستهاست. وابستگیهای مشترک تقریباً همیشه خارج از فرآیند اجرایی برنامه قرار دارن، در حالی که وابستگیهای خصوصی معمولاً از اون مرز عبور نمیکنن. به همین خاطر، فراخوانی وابستگیهای مشترک – مثل پایگاه داده یا فایلسیستم – زمان بیشتری میبره نسبت به فراخوانی وابستگیهای خصوصی. و چون سریعبودن دومین ویژگی تعریف تست واحده، این نوع فراخوانیها باعث میشن تستهایی که وابستگی مشترک دارن از حوزهی تست واحد خارج بشن و وارد قلمرو تستهای یکپارچه (integration testing) بشن. توی ادامهی این فصل، بیشتر دربارهی تستهای یکپارچه صحبت میکنم.
این برداشت متفاوت از ایزولهسازی، تعریف متفاوتی هم از «unit» یا همون «بخش کوچک از کد» ارائه میده. یه unit لزوماً نباید فقط یه کلاس باشه. میتونی یه گروه از کلاسها رو هم بهعنوان یه واحد تست کنی – بهشرطی که هیچکدوم از اونها وابستگی مشترک نداشته باشن
۲.۲ مکتبهای کلاسیک و لندن در تست واحد
همونطور که میبینی، ریشهی تفاوت بین مکتب کلاسیک و مکتب لندن، به برداشتشون از ویژگی ایزولهسازی برمیگرده. مکتب لندن ایزولهسازی رو بهمعنای جدا کردن سیستم تحت تست از همکارهاش میدونه، در حالی که مکتب کلاسیک ایزولهسازی رو بهمعنای جدا بودن خود تستهای واحد از همدیگه تفسیر میکنه.
این تفاوت ظاهراً جزئی، باعث اختلاف نظر گستردهای در نحوهی برخورد با تست واحد شده – و همونطور که تا اینجا دیدی، به شکلگیری دو مکتب فکری متفاوت منجر شده. در مجموع، این اختلاف نظر سه حوزهی اصلی رو در بر میگیره:
- تعریف ایزولهسازی
- اینکه «بخش تحت تست» (unit) دقیقاً چیه
- نحوهی مدیریت وابستگیها
در جدول زیر، تفاوتهای اصلی بین دو مکتب لندن و کلاسیک در تست واحد خلاصه شده – بر اساس نوع ایزولهسازی، اندازهی unit، و نحوهی استفاده از test doubleها:
| مکتب | ایزولهسازی روی | unit چیست؟ | استفاده از test doubleها برای |
|---|---|---|---|
| لندن | سیستم تحت تست | یک کلاس | همهی وابستگیها بهجز موارد تغییرناپذیر (immutable) |
| کلاسیک | خود تستها | یک کلاس یا مجموعهای از کلاسها | فقط وابستگیهای مشترک (shared dependencies) |
۲.۲.۱ نحوهی برخورد مکتب کلاسیک و مکتب لندن با وابستگیها
با اینکه استفاده از test doubleها توی مکتب لندن خیلی رایجه، اما این مکتب همچنان اجازه میده بعضی از وابستگیها بدون جایگزینی توی تستها استفاده بشن. معیار اصلی اینه که آیا اون وابستگی قابل تغییر (mutable) هست یا نه. اگه یه شیء تغییرناپذیر (immutable) باشه، نیازی نیست جایگزینش کنی – استفاده از نسخهی واقعی اون توی تست مشکلی نداره.
و همونطور که توی مثالهای قبلی دیدی، وقتی تستها رو به سبک لندن بازنویسی کردم، نمونههای Product رو با mock جایگزین نکردم، بلکه از خودِ شیء واقعی استفاده کردم – همونطور که توی کد زیر (برگرفته از لیست ۲.۲) نشون داده شده.
[Fact]
public void Purchase_fails_when_not_enough_inventory()
{
// Arrange
var storeMock = new Mock();
storeMock.Setup(x => x.HasEnoughInventory(Product.Shampoo, 5)).Returns(false); var customer = new Customer();
// Act
bool success = customer.Purchase(storeMock.Object, Product.Shampoo, 5);
// Assert
Assert.False(success);
storeMock.Verify( x => x.RemoveInventory(Product.Shampoo, 5), Times.Never);
}
از بین دو وابستگی کلاس Customer، فقط Store وضعیت داخلیای داره که ممکنه در طول زمان تغییر کنه. نمونههای Product تغییرناپذیر هستن—چون خود Product یه enum در C# محسوب میشه. برای همین، فقط نمونهی Store رو با test double جایگزین کردم.
اگه دقیقتر فکر کنی، این کار کاملاً منطقیه. تو هم برای عدد ۵ توی تست قبلی از test double استفاده نمیکردی، درسته؟ چون اون عدد هم تغییرناپذیره—اصلاً نمیتونی مقدارش رو تغییر بدی. دقت کن که منظورم متغیری که عدد رو نگه میداره نیست، بلکه خودِ عدد ۵ منظورمه.
توی عبارت RemoveInventory(Product.Shampoo, 5) حتی از متغیر هم استفاده نشده؛ عدد ۵ مستقیماً نوشته شده. و همین موضوع برای Product.Shampoo هم صدق میکنه.
چنین اشیایی که تغییرناپذیر هستن، بهشون value object یا بهطور ساده value گفته میشه. ویژگی اصلیشون اینه که هویت مستقل ندارن؛ یعنی فقط بر اساس محتواشون شناخته میشن. در نتیجه، اگه دو تا از این اشیا محتوای یکسانی داشته باشن، مهم نیست با کدومشون کار میکنی – چون این نمونهها قابل جایگزینی هستن. مثلاً اگه دو عدد صحیح ۵ داشته باشی، میتونی هرکدوم رو جای اون یکی استفاده کنی. همین موضوع برای محصولات توی مثال ما هم صدق میکنه: میتونی یه نمونه از Product.Shampoo رو بازاستفاده کنی یا چند تا نمونهی جداگانه تعریف کنی – هیچ فرقی نمیکنه. چون همهی این نمونهها محتوای یکسانی دارن و بنابراین میتونن بهجای همدیگه استفاده بشن.
دقت کن که مفهوم value object وابسته به زبان برنامهنویسی یا فریمورک خاصی نیست – یه مفهوم زبان-بیطرف (language-agnostic) محسوب میشه. یعنی فارغ از اینکه با C#، Java، Python یا هر زبان دیگهای کار میکنی، میتونی از این الگو استفاده کنی. برای مطالعهی بیشتر دربارهی تفاوتهای بین Entity و Value Object، میتونی مقالهی زیر رو مطالعه کنی
“Entity vs. Value Object: The ultimate list of differences”
شکل ۲.۴ دستهبندی وابستگیها و نحوهی برخورد دو مکتب تست واحد با اونها رو نشون میده. هر وابستگی میتونه یکی از دو حالت زیر باشه:
- وابستگی مشترک (shared dependency)
- وابستگی خصوصی (private dependency)
وابستگیهای خصوصی خودشون به دو دسته تقسیم میشن: - قابل تغییر (mutable)
- تغییرناپذیر (immutable) — که بهشون value object هم گفته میشه.
برای مثال:
- پایگاه داده (database) یه وابستگی مشترکه، چون وضعیت داخلیش بین همهی تستهای خودکار مشترکه (مگر اینکه با test double جایگزین بشه).
- نمونهی Store یه وابستگی خصوصیه که قابل تغییره.
- نمونهی Product (یا حتی عدد ۵) مثالی از وابستگی خصوصی تغییرناپذیره—یعنی یه value object محسوب میشه.
نکتهی مهم اینه که همهی وابستگیهای مشترک، قابل تغییر هستن. اما برای اینکه یه وابستگی قابل تغییر بهعنوان «مشترک» در نظر گرفته بشه، باید بین چند تست بازاستفاده بشه.
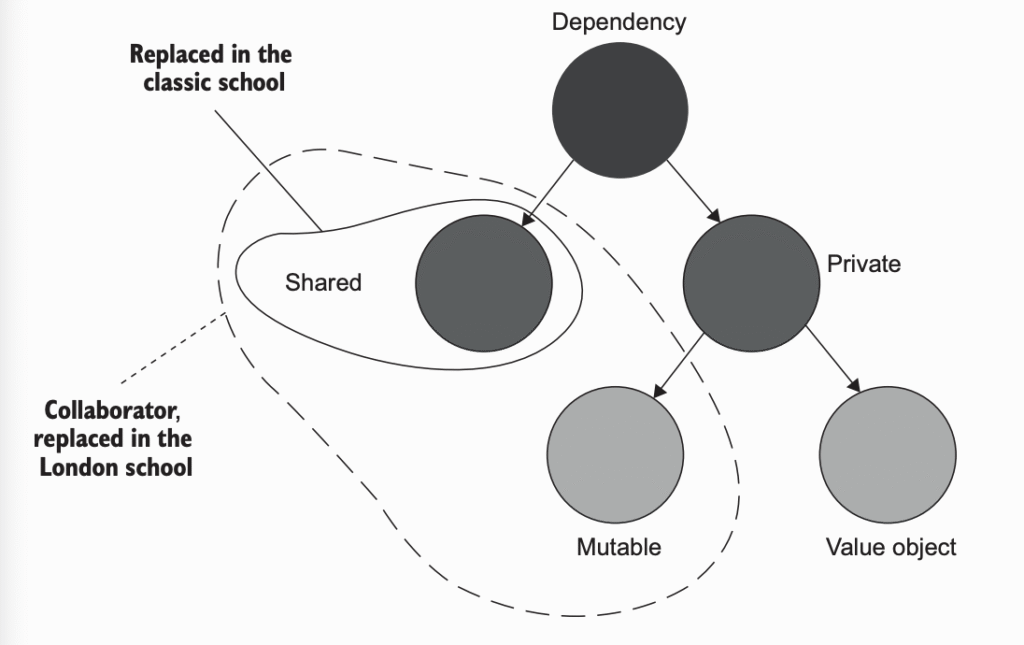
مکتب کلاسیک طرفدار جایگزینی وابستگیهای مشترک با test double است. مکتب لندن طرفدار جایگزینی وابستگیهای خصوصی نیز هست، تا زمانی که آنها قابل تغییر باشند.
همکار (Collaborator) در برابر وابستگی (Dependency)
همکار به وابستگیای گفته میشه که یا مشترک باشه یا قابل تغییر. برای مثال، کلاسی که به پایگاه داده دسترسی میده، یه همکاره—چون پایگاه داده یه وابستگی مشترکه. کلاس Store هم همکاره، چون وضعیت داخلیش در طول زمان تغییر میکنه.
اما Product و عدد ۵ هم وابستگی هستن، ولی همکار محسوب نمیشن. اونا value یا value object هستن.
یه کلاس معمولی ممکنه با هر دو نوع وابستگی کار کنه: هم با همکارها و هم با valueها.
به این فراخوانی متد نگاه کن:
customer.Purchase(store, Product.Shampoo, 5)اینجا سه تا وابستگی داریم:
یکی از اونها (store) یه همکاره،
و دوتای دیگه (Product.Shampoo و ۵) همکار نیستن.
و اجازه بده یه نکته رو دربارهی انواع وابستگیها دوباره تأکید کنم: همهی وابستگیهای خارج از فرآیند (out-of-process) لزوماً در دستهی وابستگیهای مشترک (shared) قرار نمیگیرن. درسته که یه وابستگی مشترک تقریباً همیشه خارج از فرآیند برنامه قرار داره، اما عکس این قضیه درست نیست. برای اینکه یه وابستگی خارج از فرآیند واقعاً «مشترک» محسوب بشه، باید امکانی برای ارتباط بین تستها از طریق اون وابستگی فراهم کنه. این ارتباط معمولاً از طریق تغییر وضعیت داخلی اون وابستگی انجام میشه. از این منظر، اگه یه وابستگی خارج از فرآیند تغییرناپذیر (immutable) باشه، چنین امکانی رو فراهم نمیکنه – تستها نمیتونن چیزی رو توش تغییر بدن، و بنابراین نمیتونن روی زمینهی اجرایی (execution context) همدیگه تأثیر بذارن.
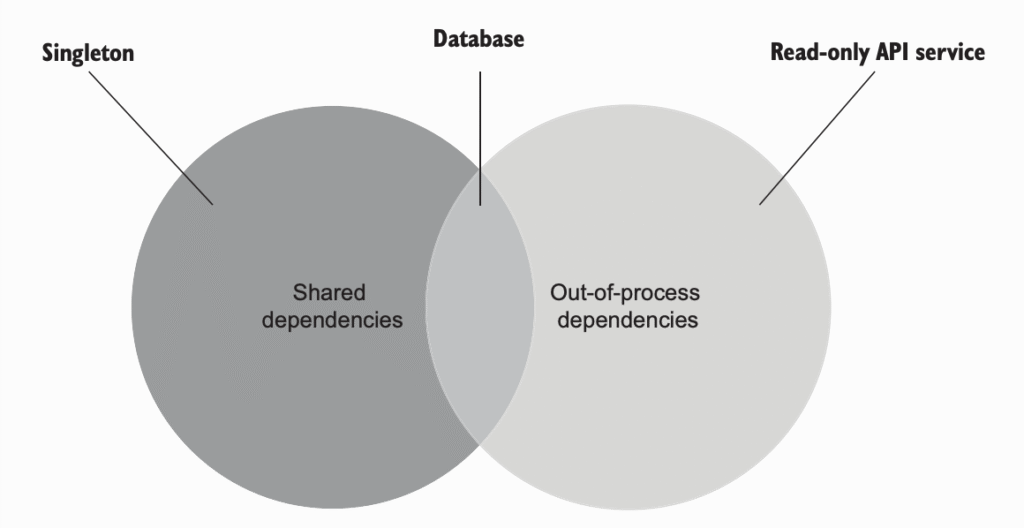
مثالی از وابستگیای که مشترک هست ولی خارج از فرآیند نیست، میتونه یه singleton باشه (نمونهای که بین همهی تستها استفاده میشه) یا یه فیلد static در یک کلاس.
پایگاه داده (database) هم وابستگیایه که هم مشترک هست و هم خارج از فرآیند – چون خارج از فرآیند اصلی قرار داره و قابل تغییره.
یه API فقطخواندنی (read-only API) مثالی از وابستگیایه که خارج از فرآیند هست ولی مشترک نیست، چون تستها نمیتونن وضعیتش رو تغییر بدن و بنابراین نمیتونن روی اجرای همدیگه تأثیر بذارن.
برای مثال، اگر APIای وجود داشته باشه که فهرست تمام محصولات سازمان رو برمیگردونه، تا زمانی که اون API امکان تغییر فهرست رو فراهم نکنه، وابستگی مشترک محسوب نمیشه. درسته که چنین وابستگیای ناپایدار (volatile) هست و خارج از مرزهای اپلیکیشن قرار داره، اما چون تستها نمیتونن دادههای برگشتی اون رو تغییر بدن، نمیتونن روی اجرای همدیگه تأثیر بذارن – پس این وابستگی مشترک نیست. این موضوع به این معنی نیست که باید چنین وابستگیای رو وارد محدودهی تستنویسی کنی. در اکثر موارد، هنوز هم لازمه که اون رو با یه test double جایگزین کنی تا تست سریع بمونه. اما اگه اون وابستگی خارج از فرآیند بهاندازهی کافی سریع باشه
و اتصال بهش پایدار باشه، میتونی بهراحتی ازش در تستها استفاده کنی، بدون جایگزینی.
با این حال، در این کتاب، از اصطلاحات وابستگی مشترک (shared dependency) و وابستگی خارج از فرآیند (out-of-process dependency) بهصورت قابل جایگزین استفاده میکنم، مگر اینکه خلافش رو صراحتاً بیان کرده باشم. در پروژههای واقعی، بهندرت با وابستگی مشترکی مواجه میشی که خارج از فرآیند نباشه. اگه یه وابستگی درونفرآیندی (in-process) باشه، میتونی بهراحتی برای هر تست یه نمونهی جداگانه از اون فراهم کنی؛ نیازی نیست که بین تستها به اشتراک گذاشته بشه. به همین ترتیب، معمولاً با وابستگی خارج از فرآیندی مواجه نمیشی که مشترک نباشه. بیشتر این نوع وابستگیها قابل تغییر (mutable) هستن و بنابراین میتونن توسط تستها تغییر داده بشن.
با این مجموعه تعاریف، حالا میتونیم دو مکتب تست واحد رو از نظر مزایا با هم مقایسه کنیم.
۲.۳ مقایسهی مکتب کلاسیک و مکتب لندن در تست واحد
برای تأکید دوباره، تفاوت اصلی بین مکتب کلاسیک و مکتب لندن در نحوهی برخورد اونها با موضوع ایزولهسازی (isolation) در تعریف تست واحده. این تفاوت، به نحوهی تعریف «واحد»—یعنی چیزی که باید تحت تست قرار بگیره—و همچنین به رویکرد اونها در مدیریت وابستگیها هم سرایت میکنه.
همونطور که قبلاً اشاره کردم، من طرفدار مکتب کلاسیک در تست واحد هستم. این مکتب معمولاً تستهایی با کیفیت بالاتر تولید میکنه و بنابراین برای رسیدن به هدف نهایی تست واحد – یعنی رشد پایدار پروژه – مناسبتره. دلیل این ترجیح، شکنندگی (fragility) تستهاست: تستهایی که از mock استفاده میکنن، معمولاً شکنندهتر از تستهای کلاسیک هستن (در فصل ۵ بیشتر به این موضوع میپردازیم). فعلاً بیایم سراغ نکات کلیدی مکتب لندن و اونها رو یکییکی بررسی کنیم.
رویکرد مکتب لندن مزایای زیر را به همراه دارد:
- دانهبندی بهتر (Better granularity):
تستها بسیار ریزدانه هستند و فقط یک کلاس را در هر بار بررسی میکنند. - تستنویسی آسانتر برای گرافهای پیچیده از کلاسها:
چون تمام همکارها (collaborators) با test double جایگزین میشن، هنگام نوشتن تست نیازی نیست نگران وابستگیهای دیگر باشی. - در صورت شکست تست، دقیقاً مشخصه که چه چیزی خراب شده:
چون هیچ همکار واقعیای در تست حضور نداره، تنها مظنون ممکن، خود کلاسیه که تحت تست قرار گرفته. البته ممکنه هنوز هم مواردی وجود داشته باشه که سیستم تحت تست از یه value object استفاده کنه و تغییر در اون باعث شکست تست بشه. اما این موارد زیاد رایج نیستن، چون باقی وابستگیها در تست حذف شدن.
۲.۳.۱ تست واحد برای یک کلاس در هر بار اجرا
نکتهی مربوط به دانهبندی بهتر (granularity) به این بحث برمیگرده که «واحد» در تست واحد دقیقاً چی هست. مکتب لندن، کلاس رو بهعنوان واحد تست در نظر میگیره. از اونجایی که برنامهنویسها معمولاً از پسزمینهی شیگرایی میان، طبیعیه که کلاسها رو بهعنوان بلوکهای سازندهی اتمی در معماری کد تلقی کنن – و همین دیدگاه باعث میشه که کلاسها رو بهعنوان واحدهای اتمی برای تست هم در نظر بگیرن. این گرایش قابل درکه، اما گمراهکننده است.
نکته: تستها نباید «واحدهای کد» رو بررسی کنن، بلکه باید «واحدهای رفتار (units of behavior)» رو بررسی کنن—چیزی که در دامنهی مسئله معنا داره و ترجیحاً برای یک فرد غیر فنی (مثلاً یک کارشناس کسبوکار) هم قابل درک و مفید باشه. تعداد کلاسهایی که برای پیادهسازی اون رفتار لازم هست، هیچ اهمیتی نداره. اون واحد رفتاری ممکنه:
- در چندین کلاس پخش شده باشه
- فقط در یک کلاس پیادهسازی شده باشه
- یا حتی فقط یک متد کوچک باشه
حتی اگه هدفمون دونهدونه تست کردن کلاسها باشه، این دیدگاه کمکی به کیفیت تستها نمیکنه. تا وقتی تست داره یه «واحد رفتار» رو بررسی میکنه، تست خوبیه. اگه هدفمون کمتر از اون باشه – یعنی فقط یه تکه از پیادهسازی رو تست کنیم بدون اینکه رفتار نهایی رو ببینیم – تستها گنگ و شکننده میشن، و فهمیدن اینکه دقیقاً چی رو دارن بررسی میکنن سختتر میشه.
تست باید یه داستان تعریف کنه – داستانی دربارهی مشکلی که کد داره حلش میکنه. و این داستان باید منسجم باشه و برای یه آدم غیر فنی هم قابل فهم باشه.
مثلاً این یه داستان منسجمه:
وقتی سگم رو صدا میزنم، مستقیم میاد سمت من.
حالا این یکی رو ببین:
وقتی سگم رو صدا میزنم، اول پای جلوی چپش رو حرکت میده، بعد پای جلوی راست، سرش میچرخه، دمش شروع میکنه به تکون خوردن…
داستان دوم خیلی نامفهومه. هدف این حرکات چیه؟ سگ داره میاد سمت من؟ یا داره فرار میکنه؟ نمیتونی بفهمی.
تستهات هم همین شکلی میشن وقتی بهجای رفتار واقعی، فقط اجزای داخلی رو تست میکنی – مثل پاها، سر، یا دم سگ – در حالی که چیزی که باید تست بشه، خود «اومدن سگ به سمت صاحبش» هست. در فصل ۵ بیشتر دربارهی رفتار قابل مشاهده و تفاوتش با جزئیات داخلی پیادهسازی صحبت میکنم.
۲.۳.۲ تست واحد برای گراف بزرگی از کلاسهای بههمپیوسته
استفاده از mock بهجای همکارهای واقعی میتونه تست کردن یه کلاس رو آسونتر کنه – بهخصوص وقتی با یه گراف پیچیده از وابستگیها طرفی، که کلاس تحت تست خودش وابسته به چند کلاس دیگهست، و هر کدوم از اونها هم وابسته به کلاسهای دیگهان، و این زنجیره چند لایه ادامه پیدا میکنه. با استفاده از test double، میتونی وابستگیهای مستقیم کلاس رو جایگزین کنی و در نتیجه اون گراف رو بشکنی – که این کار میتونه مقدار زیادی از آمادهسازی تست رو کاهش بده. اگه از مکتب کلاسیک پیروی کنی، باید کل گراف شیء رو بازسازی کنی (بهجز وابستگیهای مشترک) فقط برای اینکه سیستم تحت تست رو راه بندازی – و این میتونه حسابی وقتگیر باشه.
البته همهی این حرفها درسته، اما این نوع استدلال روی مشکل اشتباهی تمرکز کرده. بهجای اینکه دنبال راهی باشی برای تست کردن یه گراف بزرگ و پیچیده از کلاسها، باید تمرکزت رو بذاری روی اینکه اصلاً چنین گرافی وجود نداشته باشه. در بیشتر مواقع، وجود یه گراف بزرگ از کلاسها نشونهی یه مشکل در طراحی کده.
در واقع، اینکه تستها این مشکل رو نشون بدن، چیز خوبیه. همونطور که در فصل ۱ گفتیم، توانایی تست واحد یه قطعه کد، یه شاخص منفی خوبه – با دقت نسبتاً بالایی کیفیت پایین کد رو پیشبینی میکنه. اگه برای تست کردن یه کلاس، مجبور باشی فاز arrange تست رو تا حد غیرمنطقی گسترش بدی، این یه نشونهی قطعی از وجود مشکله. استفاده از mock فقط این مشکل رو پنهان میکنه؛ نه اینکه ریشهش رو حل کنه. در بخش دوم کتاب، دربارهی نحوهی اصلاح این مشکل طراحی کد بیشتر صحبت میکنم.
۲.۳.۳ پیدا کردن دقیق محل باگ
اگه یه باگ وارد سیستمی بشه که تستهاش به سبک لندن نوشته شدن، معمولاً فقط همون تستهایی شکست میخورن که SUT یا سیستم تحت تستشون شامل اون باگه. اما در رویکرد کلاسیک، تستهایی که کلاینتهای کلاس خرابشده رو بررسی میکنن هم ممکنه شکست بخورن. این باعث یه اثر دومینویی میشه که یه باگ ساده میتونه باعث شکست تستها در کل سیستم بشه. در نتیجه، پیدا کردن ریشهی مشکل سختتر میشه و ممکنه مجبور بشی وقت بذاری برای دیباگ کردن تستها تا بفهمی دقیقاً چی خراب شده.
این نگرانی قابل قبوله، ولی من اون رو مشکل بزرگی نمیدونم. اگه تستهات رو مرتب اجرا کنی (ترجیحاً بعد از هر تغییر در کد)، اونوقت دقیقاً میدونی چی باعث باگ شده – همون چیزیه که آخرین بار ویرایشش کردی. پس پیدا کردن مشکل خیلی سخت نیست. ضمن اینکه، لازم نیست همهی تستهای شکستخورده رو بررسی کنی؛ درست کردن یکیشون، بقیه رو هم خودبهخود درست میکنه.
علاوه بر این، شکستهای زنجیرهای در کل تستها یه ارزش خاص دارن: اگه یه باگ باعث بشه نه فقط یه تست، بلکه تعداد زیادی تست خراب بشن، نشون میده اون قطعه کدی که خراب شده خیلی مهمه – کل سیستم بهش وابستهست. و این اطلاعات مفیدیه که باید موقع کار با اون کد در ذهن داشته باشی.
۲.۳.۴ تفاوتهای دیگر بین مکتب کلاسیک و مکتب لندن
دو تفاوت باقیمانده بین این دو مکتب عبارتاند از:
- رویکرد آنها به طراحی سیستم در تستمحور بودن (TDD)
- مسئلهی بیشتعیینگری (Over-specification)
توسعهی مبتنی بر تست (Test-driven development)
توسعهی مبتنی بر تست یه فرآیند توسعهی نرمافزاره که بر پایهی تستها پیش میره. در این روش، تستها نقش راهنما رو دارن و مسیر توسعه رو مشخص میکنن. این فرآیند شامل سه مرحلهست (برخی نویسندهها چهار مرحله هم در نظر میگیرن) و برای هر تستکیس، این چرخه رو تکرار میکنی:
۱️⃣ نوشتن یه تست شکستخورده:
تستی مینویسی که نشون بده چه قابلیتی باید اضافه بشه و اون قابلیت چه رفتاری باید داشته باشه.
۲️⃣ نوشتن فقط بهاندازهی کافی کد برای پاس شدن تست:
تو این مرحله، کد لازم نیست تمیز یا زیبا باشه—فقط باید تست رو پاس کنه.
۳️⃣ بازآرایی (Refactor) کد:
حالا که تست پاس شده، میتونی با خیال راحت کد رو تمیزتر و قابل نگهداریتر کنی.
📚 منابع خوب برای این موضوع، دو کتابی هستن که قبلاً معرفی شدن:
- Test-Driven Development: By Example نوشتهی Kent Beck
- Growing Object-Oriented Software, Guided by Tests نوشتهی Steve Freeman و Nat Pryce
سبک لندن در تست واحد منجر به رویکرد outside-in TDD میشه – یعنی از تستهای سطح بالا شروع میکنی که انتظارات کلی از سیستم رو مشخص میکنن. با استفاده از mock، تعیین میکنی که سیستم باید با چه همکارهایی ارتباط برقرار کنه تا به نتیجهی مورد انتظار برسه.
بعدش، قدمبهقدم جلو میری و گراف کلاسها رو پیادهسازی میکنی تا همهشون کامل بشن. mockها این فرآیند طراحی رو ممکن میکنن، چون میتونی روی یه کلاس در هر بار تمرکز کنی. وقتی اون کلاس رو تست میکنی، میتونی همهی همکارهاش رو قطع کنی و پیادهسازی اونها رو به زمان دیگهای موکول کنی.
اما مکتب کلاسیک چنین راهنمایی مستقیمی ارائه نمیده، چون باید با آبجکتهای واقعی در تستها کار کنی. در عوض، معمولاً از رویکرد inside-out استفاده میکنی – یعنی از مدل دامنه شروع میکنی و لایههای بیشتری روش میذاری تا نرمافزار برای کاربر نهایی قابل استفاده بشه.
ولی مهمترین تفاوت بین این دو مکتب، موضوع بیشتعیینگری (over-specification) هست – یعنی وابسته شدن تستها به جزئیات پیادهسازی کلاس تحت تست. سبک لندن معمولاً تستهایی تولید میکنه که بیشتر از سبک کلاسیک به پیادهسازی وابستهن. و این، اصلیترین انتقاد به استفادهی گسترده از mock و سبک لندن بهطور کلیه.
موضوع mock کردن خیلی گستردهتره. از فصل ۴ به بعد، بهتدریج همهی جنبههای مربوط بهش رو پوشش میدم.
۲.۴ تستهای یکپارچه در دو مکتب
مکتبهای لندن و کلاسیک در تعریف تست یکپارچه (integration test) هم با هم اختلاف دارن. این اختلاف، بهطور طبیعی از تفاوت دیدگاهشون نسبت به موضوع ایزولهسازی ناشی میشه.
مکتب لندن، هر تستی که از یه آبجکت واقعی بهعنوان همکار استفاده کنه رو تست یکپارچه میدونه. بیشتر تستهایی که به سبک کلاسیک نوشته میشن، از نگاه طرفداران مکتب لندن، تست یکپارچه محسوب میشن. برای مثال، به کد لیست ۱.۴ (فصل اول) نگاه کن که دو تست مربوط به قابلیت خرید مشتری رو معرفی میکنه. اون کد از دیدگاه کلاسیک یه تست واحد معمولیه، ولی برای پیروان مکتب لندن، یه تست یکپارچهست.
در این کتاب، من از تعاریف کلاسیک برای تست واحد و تست یکپارچه استفاده میکنم. یعنی تست واحد، تست خودکاریه که این ویژگیها رو داره:
- یه تکهی کوچک از کد رو بررسی میکنه،
- سریع اجرا میشه،
- و بهصورت ایزوله انجام میشه.
حالا که مشخص کردم منظور از ویژگی اول و سوم چیه، بیایم تعریف تست واحد رو از دیدگاه مکتب کلاسیک بازنویسی کنیم:
تست واحد، تستیه که:
- یه واحد رفتار مشخص رو بررسی میکنه،
- سریع اجرا میشه
- و بهصورت ایزوله از سایر تستها انجام میشه.
در نتیجه، تست یکپارچه (integration test) تستیه که یکی از این معیارها رو نداره. مثلاً تستی که به یه وابستگی مشترک مثل دیتابیس وصل میشه، نمیتونه بهصورت ایزوله از سایر تستها اجرا بشه. اگه یه تست وضعیت دیتابیس رو تغییر بده، نتیجهی همهی تستهای دیگهای که به همون دیتابیس وابستهن تغییر میکنه – بهخصوص اگه تستها بهصورت موازی اجرا بشن. برای جلوگیری از این تداخل، باید اقدامات اضافهای انجام بدی. بهطور خاص، باید این تستها رو بهصورت ترتیبی (sequential) اجرا کنی، تا هر تست نوبت خودش رو برای کار با اون وابستگی مشترک رعایت کنه.
بههمین شکل، ارتباط با یه وابستگی خارج از فرآیند باعث کند شدن تست میشه. مثلاً یه فراخوانی به دیتابیس میتونه چند صد میلیثانیه—و گاهی تا یه ثانیه—به زمان اجرای تست اضافه کنه. شاید در نگاه اول، میلیثانیهها مهم به نظر نرسن، اما وقتی تستهات زیاد بشه، هر ثانیه اهمیت پیدا میکنه.
در تئوری، میتونی یه تست کند بنویسی که فقط با آبجکتهای داخل حافظه کار میکنه، اما انجام این کار چندان ساده نیست. ارتباط بین آبجکتها در یه فضای حافظهی مشترک، خیلی کمهزینهتره نسبت به ارتباط بین فرآیندهای جداگانه. حتی اگه تست با صدها آبجکت داخل حافظه سروکار داشته باشه، باز هم ارتباط با اونها سریعتر از یه فراخوانی به دیتابیس اجرا میشه.
در نهایت، یه تست وقتی تست یکپارچه محسوب میشه که دو یا چند واحد رفتار رو بررسی کنه. این معمولاً نتیجهی تلاش برای بهینهسازی سرعت اجرای تستسوییته (test suite). وقتی دو تست کند داری که مراحل مشابهی رو طی میکنن ولی واحدهای رفتاری متفاوتی رو بررسی میکنن، ممکنه منطقی باشه که اونها رو با هم ترکیب کنی – یه تست که دو چیز مشابه رو بررسی میکنه، سریعتر اجرا میشه نسبت به دو تست ریزدانهی جداگانه. ولی با این حال، اون دو تست اولیه از قبل هم تست یکپارچه بودن (چون کند بودن)، پس این ویژگی معمولاً تعیینکننده نیست.
یه تست یکپارچه همچنین میتونه بررسی کنه که چطور دو یا چند ماژول که توسط تیمهای جداگانه توسعه داده شدن با هم کار میکنن. این هم زیرمجموعهی همون دستهی سومه—تستهایی که چند واحد رفتار رو همزمان بررسی میکنن.ولی باز هم، چون چنین یکپارچهسازیای معمولاً نیاز به یه وابستگی خارج از فرآیند داره، اون تست نمیتونه هیچکدوم از سه معیار تست واحد رو رعایت کنه.
تست یکپارچه نقش مهمی در بالا بردن کیفیت نرمافزار داره، چون کل سیستم رو بهصورت یکپارچه بررسی میکنه. در بخش سوم کتاب، با جزئیات بیشتری دربارهی تستهای یکپارچه صحبت میکنم.
۲.۴.۱ تستهای End-to-End زیرمجموعهای از تستهای یکپارچه هستن
بهطور خلاصه، تست یکپارچه تستیه که بررسی میکنه آیا کد شما در تعامل با:
- وابستگیهای مشترک،
- وابستگیهای خارج از فرآیند،
- یا کدی که توسط تیمهای دیگه در سازمان توسعه داده شده،
درست کار میکنه یا نه. یه مفهوم جداگانه هم وجود داره به اسم تست End-to-End. تستهای End-to-End زیرمجموعهای از تستهای یکپارچه محسوب میشن. اونها هم بررسی میکنن که کد شما چطور با وابستگیهای خارج از فرآیند تعامل داره. فرق بین تست End-to-End و تست یکپارچه اینه که تستهای End-to-End معمولاً شامل تعداد بیشتری از این وابستگیها میشن.
گاهی مرز بین این دو نوع تست واضح نیست، ولی بهطور کلی، تست یکپارچه فقط با یکی دو وابستگی خارج از فرآیند کار میکنه، در حالی که تست End-to-End با همهی وابستگیهای خارج از فرآیند یا با اکثریت اونها سروکار داره. اسمش هم از همینجا میاد—End-to-End یعنی تستی که سیستم رو از دید کاربر نهایی بررسی میکنه، و همهی اپلیکیشنهای خارجیای که سیستم باهاشون یکپارچه شده رو هم در بر میگیره. (شکل ۲.۶)
همچنین از اصطلاحاتی مثل UI تست (مخفف User Interface)، GUI تست (مخفف Graphical User Interface) و تستهای عملکردی (Functional Tests) هم استفاده میشه. این اصطلاحات تعریف دقیقی ندارن، اما بهطور کلی، همهشون تقریباً به یه معنی به کار میرن و میتونیم اونها رو مترادف بدونیم.
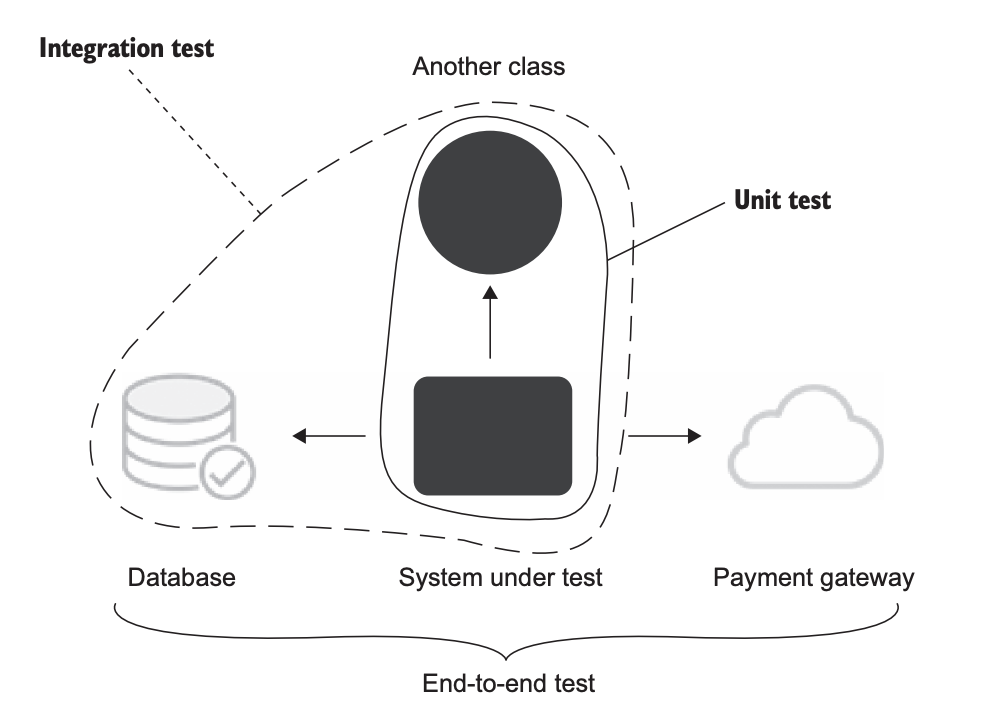
تستهای End-to-End معمولاً شامل همه یا تقریباً همهی وابستگیهای خارج از فرآیند هستن— یعنی کل مسیر اجرای سیستم از دید کاربر نهایی رو پوشش میدن. در مقابل، تستهای یکپارچه (Integration Tests) فقط با یکی دو تا از این وابستگیها کار میکنن— اونهایی که راهاندازی خودکارشون آسونتره، مثل دیتابیس یا سیستم فایل.
فرض کن اپلیکیشن شما با سه وابستگی خارج از فرآیند کار میکنه: یه دیتابیس، سیستم فایل، و یه درگاه پرداخت.
توی یه تست یکپارچهی معمولی، فقط دیتابیس و سیستم فایل داخل محدودهی تست قرار میگیرن، و برای درگاه پرداخت از یه test double استفاده میکنی. دلیلش اینه که روی دیتابیس و سیستم فایل کنترل کامل داری، و میتونی راحت اونها رو به وضعیت مورد نیاز برای تست برسونی.
اما روی درگاه پرداخت چنین سطحی از کنترل رو نداری. برای کار با درگاه پرداخت، ممکنه مجبور باشی با شرکت پردازش پرداخت تماس بگیری تا یه حساب تست مخصوص راه بندازی. و شاید لازم باشه هر از گاهی اون حساب رو بررسی کنی تا دستی همهی تراکنشهای باقیمونده از اجرای تستهای قبلی رو پاکسازی کنی.
از اونجایی که تستهای End-to-End از نظر نگهداری پرهزینهترین نوع تست هستن، بهتره اونها رو در مراحل پایانی فرآیند build اجرا کنی – بعد از اینکه همهی تستهای واحد و یکپارچه با موفقیت پاس شدن. حتی ممکنه تصمیم بگیری این تستها رو فقط روی سرور build اجرا کنی، نه روی ماشینهای شخصی توسعهدهندهها.
یادت باشه که حتی با تستهای End-to-End هم ممکنه نتونی همهی وابستگیهای خارج از فرآیند رو پوشش بدی. ممکنه برای بعضی از اون وابستگیها نسخهی تست وجود نداشته باشه، یا نتونی اونها رو بهصورت خودکار به وضعیت مورد نیاز برسونی.
بنابراین، ممکنه همچنان مجبور باشی از test double استفاده کنی – که این موضوع دوباره تأکید میکنه مرز مشخصی بین تست یکپارچه و تست End-to-End وجود نداره.
خلاصه
- در طول این فصل، به تعریف دقیقتری از تست واحد رسیدیم:
– تست واحد یه واحد رفتار مشخص رو بررسی میکنه،
– سریع اجرا میشه،
– و بهصورت ایزوله از سایر تستها انجام میشه. - موضوع ایزولهسازی بیشترین محل اختلافه. این اختلاف منجر به شکلگیری دو مکتب تست واحد شد:
مکتب کلاسیک (دیترویت) و مکتب لندن (mockist).
این تفاوت دیدگاه روی تعریف واحد و نحوهی برخورد با وابستگیهای سیستم تحت تست (SUT) تأثیر میذاره. – مکتب لندن معتقده که واحدهای تحت تست باید از هم ایزوله باشن.
واحد تحت تست یه واحد کده، معمولاً یه کلاس.
همهی وابستگیهاش—بهجز وابستگیهای تغییرناپذیر—باید با test double جایگزین بشن. – مکتب کلاسیک معتقده که تستهای واحد باید از هم ایزوله باشن، نه خود واحدها.
همچنین، واحد تحت تست یه واحد رفتاره، نه یه واحد کد.
بنابراین، فقط وابستگیهای مشترک باید با test double جایگزین بشن.
وابستگیهای مشترک اونهایی هستن که باعث میشن تستها روی اجرای همدیگه تأثیر بذارن. - مکتب لندن مزایایی مثل دانهبندی بهتر، راحتی در تست گرافهای بزرگ از کلاسهای بههمپیوسته، و راحتی در پیدا کردن محل باگ بعد از شکست تست ارائه میده.
- این مزایا در نگاه اول جذاب به نظر میرسن، اما چند مشکل هم به همراه دارن.
اول اینکه تمرکز روی کلاسهای تحت تست اشتباهه:
تستها باید واحدهای رفتار رو بررسی کنن، نه واحدهای کد.
علاوه بر این، ناتوانی در تست واحد یه قطعه کد نشونهی قویای از مشکل در طراحی کده.
استفاده از test double این مشکل رو حل نمیکنه، فقط پنهانش میکنه.
و در نهایت، هرچند راحتی در تشخیص محل باگ بعد از شکست تست مفیده، اما خیلی هم مهم نیست چون معمولاً خودت میدونی چی باعث باگ شده—همون چیزیه که آخرین بار ویرایشش کردی. - بزرگترین مشکل مکتب لندن در تست واحد، مسئلهی بیشتعیینگری (over-specification) هست – یعنی وابسته شدن تستها به جزئیات پیادهسازی SUT.
- تست یکپارچه تستیه که حداقل یکی از معیارهای تست واحد رو نداره.
تستهای End-to-End زیرمجموعهای از تستهای یکپارچهان؛
اونها سیستم رو از دید کاربر نهایی بررسی میکنن
و مستقیماً با همه یا تقریباً همهی وابستگیهای خارج از فرآیند اپلیکیشن تعامل دارن. - برای مطالعهی سبک کلاسیک، کتاب Test-Driven Development: By Example نوشتهی Kent Beck رو پیشنهاد میکنم.
برای سبک لندن، کتاب Growing Object-Oriented Software, Guided by Tests نوشتهی Steve Freeman و Nat Pryce رو ببین.
برای مطالعهی بیشتر دربارهی کار با وابستگیها، کتاب Dependency Injection: Principles, Practices, Patterns نوشتهی Steven van Deursen و Mark Seemann رو پیشنهاد میکنم.
;